在k8s中,如果想ping svc以及ip,发现无法ping通,使用测试环境为k8s 1.6,后来k8s升级到1.12版本,发现ping svc以及ip可以ping通,这里分析一下原因。
后来发现是由于1.8的代理模式不是ipvs(1.6版本没有引入ipvs),1.12可以配置iptables和ipvs,而1.12版本配置使用的是ipvs。
这里就分析一下三种模式区别以及性能对比。
1.三种代理模式
先了解一下代理模式有哪几种。
-
- userspace 代理模式(K8S 1.1之前版本)
- iptables 代理模式(K8S 1.10之前版本)
- ipvs 代理模式(K8S 1.11之后版本,激活ipvs需要修改配置)
1.1 userspace模式
在 userspace 模式下,kube-proxy 通过监听 K8s apiserver 获取关于 Service 和 Endpoint 的变化信息,在内存中维护一份从ClusterIP:Port 到后端 Endpoints 的映射关系,通过反向代理的形式,将收到的数据包转发给后端,并将后端返回的应答报文转发给客户端。该模式下,kube-proxy 会为每个 Service (每种协议,每个 Service IP,每个 Service Port)在宿主机上创建一个 Socket 套接字(监听端口随机)用于接收和转发 client 的请求。默认条件下,kube-proxy 采用 round-robin 算法从后端 Endpoint 列表中选择一个响应请求。
由于其需要来回在用户空间和内核空间交互通信,因此效率很差,接着就有了第二种方式

1.2 Iptables模式
在iptables 模式下,kube-proxy 依然需要通过监听K8s apiserver 获取关于 Service 和 Endpoint 的变化信息。不过与 userspace 模式不同的是,kube-proxy 不再为每个 Service 创建反向代理(也就是无需创建 Socket 监听),而是通过安装 iptables 规则,捕获访问 Service ClusterIP:Port 的流量,直接重定向到指定的 Endpoints 后端。默认条件下,kube-proxy 会 随机 从后端 Endpoint 列表中选择一个响应请求。ipatbles 模式与 userspace 模式的不同之处在于,数据包的转发不再通过 kube-proxy 在用户空间通过反向代理来做,而是基于 iptables/netfilter 在内核空间直接转发,避免了数据的来回拷贝,因此在性能上具有很大优势,而且也避免了大量宿主机端口被占用的问题。
但是将数据转发完全交给 iptables 来做也有个缺点,就是一旦选择的后端没有响应,连接就会直接失败了,而不会像 userspace 模式那样,反向代理可以支持自动重新选择后端重试,算是失去了一定的重试灵活性。不过,官方建议使用 Readiness 探针来解决这个问题,一旦检测到后端故障,就自动将其移出 Endpoint 列表,避免请求被代理到存在问题的后端。
并且iptables 因为它纯粹是为防火墙而设计的,并且基于内核规则列表,集群数量越多性能越差。
一个例子是,在5000节点集群中使用 NodePort 服务,如果我们有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个 iptable 记录,这可能使内核非常繁忙。
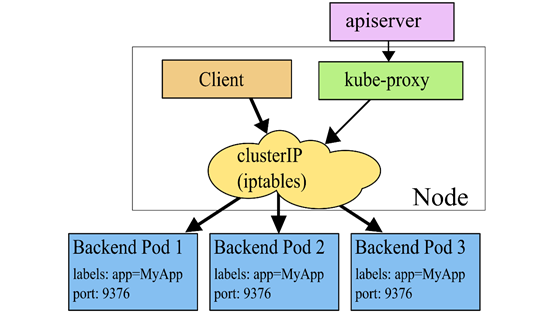
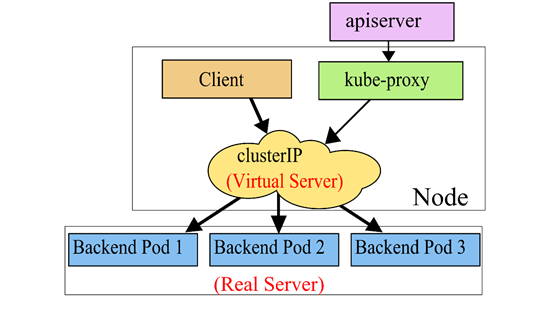
1.3 Ipvs代理模式
IPVS 是一个用于负载均衡的 Linux 内核功能。IPVS 模式下,kube-proxy 使用 IPVS 负载均衡代替了 iptable。这种模式同样有效,IPVS 的设计就是用来为大量服务进行负载均衡的,它有一套优化过的 API,使用优化的查找算法,而不是简单的从列表中查找规则。
这样一来,kube-proxy 在 IPVS 模式下,其连接过程的复杂度为 O(1)。换句话说,多数情况下,他的连接处理效率是和集群规模无关的。
另外作为一个独立的负载均衡器,IPVS 包含了多种不同的负载均衡算法,例如轮询、最短期望延迟、最少连接以及各种哈希方法等。而 iptables 就只有一种随机平等的选择算法。
IPVS代理模式基于netfilter hook函数,该函数类似于iptables模式,但使用hash表作为底层数据结构,在内核空间中工作。这意味着IPVS模式下的kube-proxy使用更低的重定向流量。其同步规则的效率和网络吞吐量也更高。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。IPVS是专门为负载均衡设计的,并且底层使用哈希表这种非常高效的数据结构,几乎可以允许无限扩容。
IPVS 的一个潜在缺点就是,IPVS 处理数据包的路径和通常情况下 iptables 过滤器的路径是不同的。如果计划在有其他程序使用 iptables 的环境中使用 IPVS,需要进行一些研究,看看他们是否能够协调工作。(Calico 已经和 IPVS kube-proxy 兼容)
2.性能对比
iptables 的连接处理算法复杂度是 O(n),而 IPVS 模式是 O(1),但是在微服务环境中,其具体表现如何呢?
在多数场景中,有两个关键属性需要关注:
-
- 响应时间:一个微服务向另一个微服务发起调用时,第一个微服务发送请求,并从第二个微服务中得到响应,中间消耗了多少时间?
- CPU消耗:运行微服务的过程中,总体 CPU 使用情况如何?包括用户和核心空间的 CPU 使用,包含所有用于支持微服务的进程(也包括 kube-proxy)。
为了说明问题,我们运行一个微服务作为客户端,这个微服务以 Pod 的形式运行在一个独立的节点上,每秒钟发出 1000 个请求,请求的目标是一个 Kubernetes 服务,这个服务由 10 个 Pod 作为后端,运行在其它的节点上。接下来我们在客户端节点上进行了测量,包括 iptables 以及 IPVS 模式,运行了数量不等的 Kubernetes 服务,每个服务都有 10 个 Pod,最大有 10,000 个服务(也就是 100,000 个 Pod)。我们用 golang 编写了一个简单的测试工具作为客户端,用标准的 NGINX 作为后端服务。
2.1 响应时间
响应时间很重要,有助于我们理解连接和请求的差异。典型情况下,多数微服务都会使用持久或者 keepalive 连接,这意味着每个连接都会被多个请求复用,而不是每个请求一次连接。这很重要,因为多数连接的新建过程都需要完成三次 TCP 握手的过程,这需要消耗时间,也需要在 Linux 网络栈中进行更多操作,也就会消耗更多 CPU 和时间。
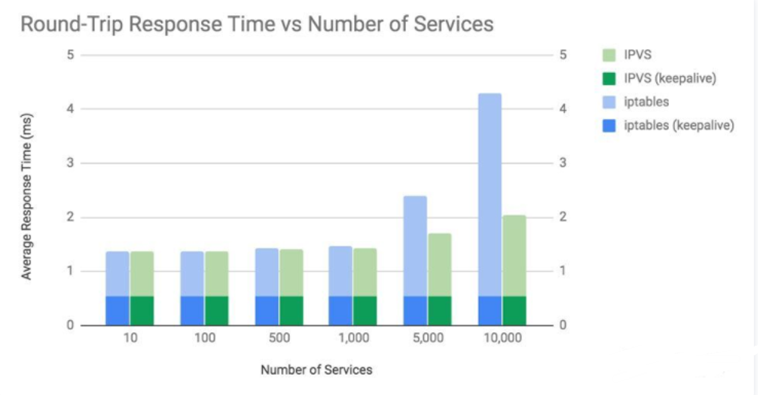
这张图展示了两个关键点:
-
- iptables 和 IPVS 的平均响应时间在 1000 个服务(10000 个 Pod)以上时,会开始观察到差异。
- 只有在每次请求都发起新连接的情况下,两种模式的差异才比较明显。
不管是 iptables 还是 IPVS,kube-proxy 的响应时间开销都是和建立连接的数量相关的,而不是数据包或者请求数量,这是因为 Linux 使用了 Conntrack,能够高效地将数据包和现存连接关联起来。如果数据包能够被 Conntrack 成功匹配,那就不需要通过 kube-proxy 的 iptables 或 IPVS 规则来推算去向。Linux conntrack 非常棒!(绝大多数时候)
值得注意的是,例子中的服务端微服务使用 NGINX 提供一个静态小页面。多数微服务要做更多操作,因此会产生更高的响应时间,也就是 kube-proxy 处理过程在总体时间中的占比会减少。
还有个需要解释的古怪问题:既然 IPVS 的连接过程复杂度是 O(1),为什么在 10,000 服务的情况下,非 Keepalive 的响应时间还是提高了?我们需要深入挖掘更多内容才能解释这一问题,但是其中一个因素就是因为上升的 CPU 用量拖慢了整个系统。这就是下一个主题需要探究的内容。
2.2 CPU用量
为了描述 CPU 用量,下图关注的是最差情况:不使用持久/keepalive 连接的情况下,kube-proxy 会有最大的处理开销。
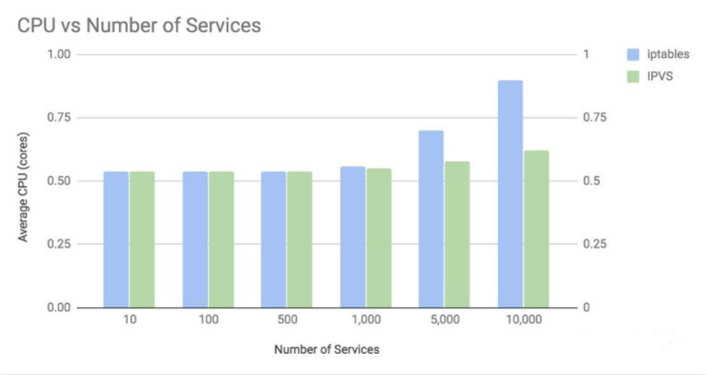
上图说明了两件事:
-
- 在超过 1000 个服务(也就是 10,000 个 Pod)的情况下,CPU 用量差异才开始明显。
- 在一万个服务的情况下(十万个后端 Pod),iptables 模式增长了 0.35 个核心的占用,而 IPVS 模式仅增长了 8%。
有两个主要因素造成 CPU 用量增长:
第一个因素是,缺省情况下 kube-proxy 每 30 秒会用所有服务对内核重新编程。这也解释了为什么 IPVS 模式下,新建连接的 O(1) 复杂度也仍然会产生更多的 CPU 占用。另外,如果是旧版本内核,重新编程 iptables 的 API 会更慢。所以如果你用的内核较旧,iptables 模式可能会占用更多的 CPU。
另一个因素是,kube-proxy 使用 IPVS 或者 iptables 处理新连接的消耗。对 iptables 来说,通常是 O(n) 的复杂度。在存在大量服务的情况下,会出现显著的 CPU 占用升高。例如在 10,000 服务(100,000 个后端 Pod)的情况下,iptables 会为每个请求的每个连接处理大约 20000 条规则。如果使用 NINGX 缺省每连接 100 请求的 keepalive 设置,kube-proxy 的 iptables 规则执行次数会减少为 1%,会把 iptables 的 CPU 消耗降低到和 IPVS 类似的水平。
客户端微服务会简单的丢弃响应内容。真实世界中自然会进行更多处理,也会造成更多的 CPU 消耗,但是不会影响 CPU 消耗随服务数量增长的事实。
2.3 结论
二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。
在超过 1000 服务的规模下,kube-proxy 的 IPVS 模式会有更好的性能表现。虽然可能有多种不同情况,但是通常来说,让微服务使用持久连接、运行现代内核,也能取得较好的效果。如果运行的内核较旧,或者无法使用持久连接,那么 IPVS 模式可能是个更好的选择。
抛开性能问题不谈,IPVS 模式还有个好处就是具有更多的负载均衡算法可供选择。
如果你还不确定 IPVS 是否合适,那就继续使用 iptables 模式好了。这种传统模式有大量的生产案例支撑,他是一个不完美的缺省选项。
2.4 Calico和kube-proxy的iptables比较
本文中我们看到,kube-proxy 中的 iptables 用法在大规模集群中可能会产生性能问题。有人问我 Calico 为什么没有类似的问题。答案是 Calico 中 kube-proxy 的用法是不同的。kube-proxy 使用了一个很长的规则链条,链条长度会随着集群规模而增长,Calico 使用的是一个很短的优化过的规则链,经由 ipsets 的加持,也具备了 O(1) 复杂度的查询能力。
下图证明了这一观点,其中展示了每次连接过程中,kube-proxy 和 Calico 中 iptables 规则数量的平均值。这里假设集群中的节点平均有 30 个 Pod,每个 Pod 具有 3 个网络规则。
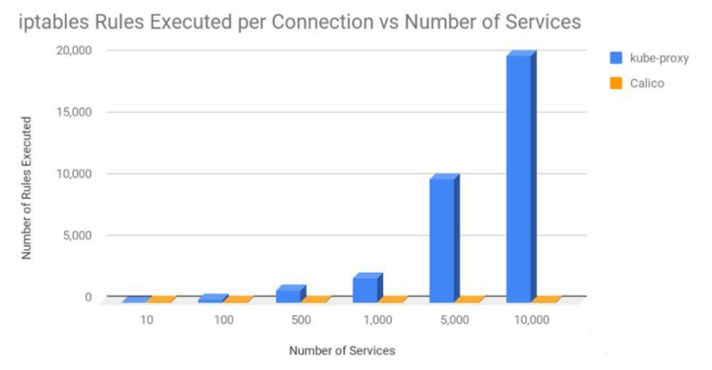
即使是使用 10,000 个服务和 100,000 个 Pod 的情况下,Calico 每连接执行的 iptables 规则也只是和 kube-proxy 在 20 服务 200 个 Pod 的情况基本一致。