在JDK1.7及以前中,如果在并发环境中使用HashMap保存数据,有可能会产生死循环的问题,造成cpu的使用率飙升。之所以会发生该问题,实际上就是因为HashMap中的扩容问题。
HashMap的实现实际上是一个数组+链表的实现(JDK1.8中当链表长度达到一定值会转化为红黑树),当HashMap中保存的值超过阈值时将会进行一次扩容操作,并发环境下可能存在一个线程发现HashMap容量不够需要扩容,而在这个过程中,另外一个线程也刚好进行扩容操作,这时就有可能造成死循环的问题。扩容操作一般是在调用put(...)方法时进行的,put时会对容量进行检查。如果在扩容是链表中产生一个环形链表,那么在使用get(...)获取数据时将可能产生死循环。
//进行扩容时调用的方法
void resize(int newCapacity) {
Entry[] oldTable = table;//保存旧的数组
int oldCapacity = oldTable.length;//保存旧的容量
if (oldCapacity == MAXIMUM_CAPACITY) {//无法再进行扩容
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//将原数组中的元素迁移到扩容后的数组中
//死循环就是在这个方法中产生的
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
在并发环境中,多个线程并不是一起执行的,而是由cpu来调度,任何线程在任意时刻都有可能停下来,当线程停下来时状态实际上被保存在栈帧中,下一次被cpu分配到执行权时从读取当前状态开始继续执行,对于被cpu挂起的线程在挂起这段时间相当于是"时间暂停"了。明白了这些接下来我们模拟死循环出现的情况,实际上这种情况是很不容易出现的,因为需要的条件较多,但是如果我们线上环境执行频率很高的话产生这种情况就显得比较容易了,一旦产生一次那就是灾难,除了修改代码重启服务器基本没别的解决方法。
假设当前HashMap中数组长度为1,并且只保存了两个值(设置的值都是为了产生死循环),如下图,改图表示一个长度为1的数组,保存值为1和3的两个值:
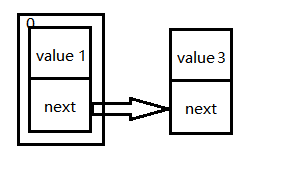
现在假设两个线程都在进行扩容操作,线程1刚开始,当走到Entry<K,V> next = e.next;时线程挂起,cpu被分配给线程2。
线程2在cpu分配的执行时间中对HashMap操作后变成下图所示。扩容后,数组长度变为2,由于扩容是重新插入(头插法)的原因,值得顺序变了,现在value=3持有value=1的引用。此时线程2挂起,cpu切换到线程1。之前保存的状态中e的值为value=1的entry且e包含value=3的值得引用。
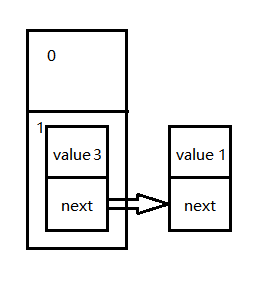
线程1继续之前的操作:
e.next = newTable[i];
newTable[i] = e;
e = next;
经过两次循环后:
看起来和正常的没有什么区别,理论上来说,正常情况下由于value=3的entry的next为null此时应该跳出循环,但是问题在于之前的线程2使得value=3持有value=1的引用,这时还会在进行一次循环:
//此时e = value(1)
Entry<K,V> next = e.next; //next=null
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //e.next=value(3) 死循环了
newTable[i] = e;
e = next;
由上可知此时value(3).next=value(1) 并且value(1).next=value(3),产生了环形链表。
如果之后调用get(...)方法,能找到还好,如果查找的值不存在,那么get方法会在环形链表处一直循环无法退出,只能重启服务器了...