今天下载安装了spark,下面是下载过程:
(1)根据林子雨老师的下载教程,选择spark3.0.0进行下载,点击Download后面的下载链接进行下载。网址(http://spark.apache.org/downloads.html)
(2)解压
(3)修改Spark的配置文件spark-env.sh,第一行添加“export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)”
(4)检验是否安装成功
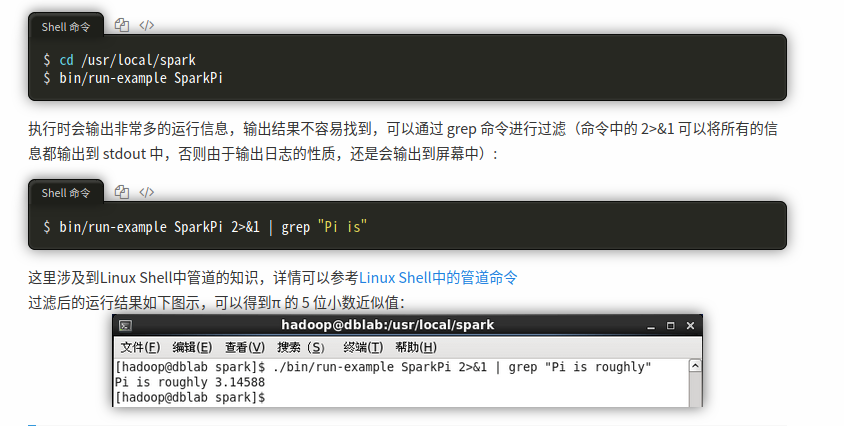
以下是我的检验结果:

接下来使用命令:bin/spark-shell就可以开始使用scala代码进行调试了。
一些RDD基础操作试验:
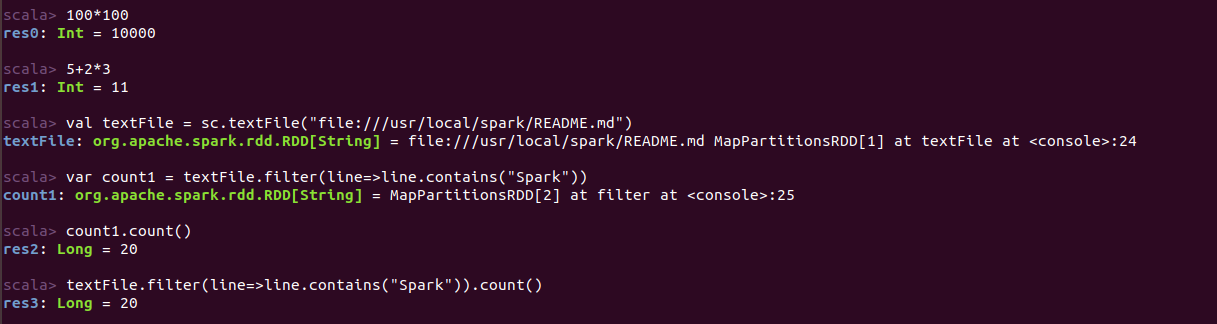
计算配置文件ReADME.md中包含“Spark”字符串的行数,两种方法 :
①
1 var count1 = textFile.filter(line=>line.contains("Spark")) 2 count1.count()
②
1 textFile.filter(line=>line.contains("Spark")).count();
运行结果:
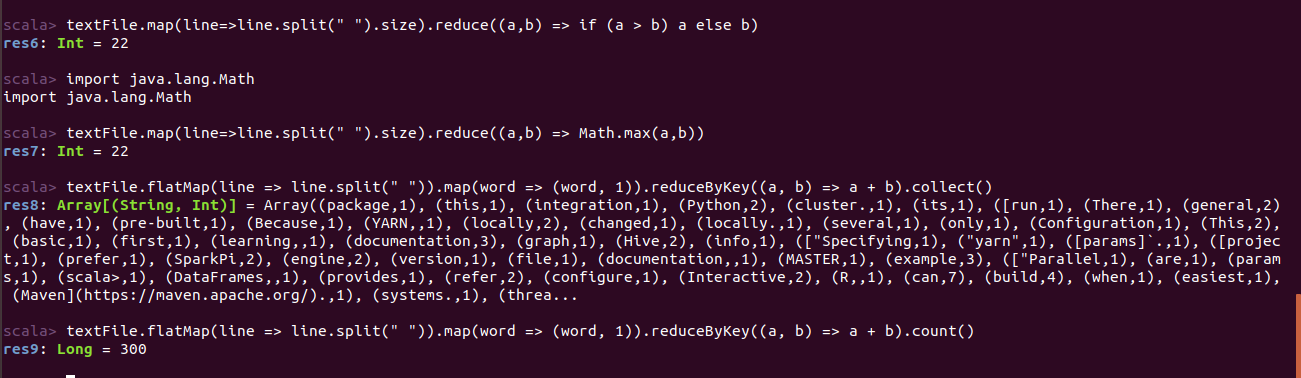
通过如下代码可以找到包含单词最多的那一行内容共有几个单词:
1 //①不导入库 2 textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) 3 //②导入Math库 4 import java.lang.Math 5 textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
使用“Ctrl+D”组合键,退出Spark Shell。
编写Scala独立应用程序
① 因为使用 Scala 编写的程序需要使用 sbt 进行编译打包,Java 程序使用 Maven 编译打包,而 Python 程序通过 spark-submit 直接提交。所以我们想要使用scala代码进行编写,那么就需要下载sbt。
第一次下载后运行命令“./sbt sbt-version”发现如下报错:

网上搜索了一下,发现有人说再来一次,我尝试了一下发现果真可以了。

② 编写Scala应用程序
在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件,代码如下:


1 /* SimpleApp.scala */ 2 import org.apache.spark.SparkContext 3 import org.apache.spark.SparkContext._ 4 import org.apache.spark.SparkConf 5 6 object SimpleApp { 7 def main(args: Array[String]) { 8 val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system 9 val conf = new SparkConf().setAppName("Simple Application") 10 val sc = new SparkContext(conf) 11 val logData = sc.textFile(logFile, 2).cache() 12 val numAs = logData.filter(line => line.contains("a")).count() 13 val numBs = logData.filter(line => line.contains("b")).count() 14 println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) 15 } 16 }
③ 使用sbt打包Scala程序
通过 sbt 进行编译打包。 在./sparkapp 中新建文件 simple.sbt(vim ./sparkapp/simple.sbt),添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系:
1 name := "Simple Project" 2 version := "1.0" 3 scalaVersion := "2.11.8" 4 libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
执行如下命令检查整个应用程序的文件结构:
1 cd ~/sparkapp 2 find .
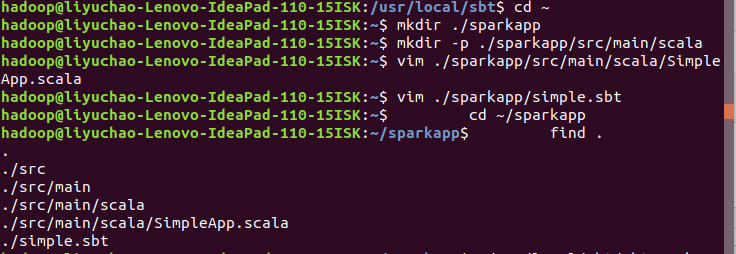
通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
1 /usr/local/sbt/sbt package
结果:

④通过 spark-submit 运行程序
将生成的 jar 包通过 spark-submit 提交到 Spark 中运行。
1 /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2 #上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果 3 /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
结果:
