没想到再接着学习都是2019年3月30日16:37:49 了。。。
https://www.bilibili.com/video/av39137333/?p=7
2.1.3数据集的划分
机器学习一般的数据集会划分为两个部分:
-
2019年3月6日10:50:29
07 sklearn 数据集使用
https://www.bilibili.com/video/av39137333/?p=7
思考:拿到的数据是否全部用来训练一个模型?
模型进行评估,拿到数据时,留出一部分,用来跟模型的数据进行比较。
测试集 20-30%
安装PyCharm
2019年3月5日16:11:12
https://blog.csdn.net/sinat_32582203/article/details/71633678
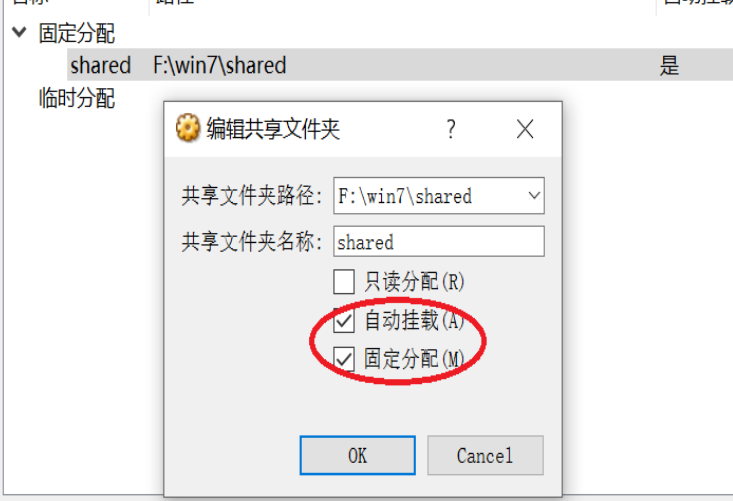
重启电脑后,会出现。
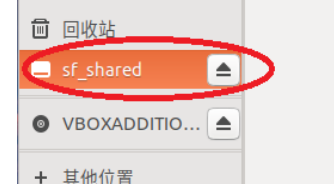
virtualBox 新建共享文件夹后,打开提示没有权限
https://blog.csdn.net/idoming/article/details/51788878
https://blog.csdn.net/idoming/article/details/51788878
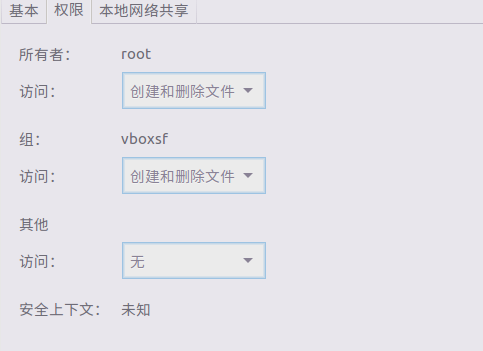
sudo usermod -a -G vboxsf yourusername
07 sklearn 数据集使用
https://www.bilibili.com/video/av39137333/?p=7
2019年3月4日16:51:28
思考:拿到的数据是否全部用来训练一个模型?
模型进行评估,拿到数据时,留出一部分,用来跟模型的数据进行比较。
2.1.3 数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型。
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
数据集划分api
- sklearn.model_selection.train_test_split(arrays,*options)
- x数据集的特征值
- y数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 训练集特征值,测试集特征值,训练集目标值,测试集目标值
2019年3月4日08:18:31
2.1.2 sklearn
1.scikit-learn 数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
2.sklearn 小数据集
- sklearn.datasets.load_iris()
加载并返回鸢尾花数据集 Iris 是在UCI数据学习仓库里面特别流行的数据集。

- sklearn.datasets.load_boston()
加载并返回波士顿房价数据集

3.sklearn 大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train')
- subset:'train'或者'test','all',可选,选择要加载的数据集
- 训练集的“训练”,测试集的“测试”,两者的“全部”
4.sklearn 数据集的使用
sklearn 数据集返回值介绍
- load 和 fetch 返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是[n_samples*n_features]的二维 numpy.ndarray数组
- target:标签数组,是n_samples 的一维numpy.ndarray数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名

from sklearn.datasets import load_iris
#获取鸢尾花数据集
iris =load_iris()
print("鸢尾花数据集的返回值:
",iris)
#返回值是一个继承自字典的Bench
print("鸢尾花的特征值:
",iris["data"])
print("鸢尾花的目标值:
",iris.target)
print("鸢尾花特征的名字:
",iris.feature_names)
print("鸢尾花目标值的名字:
",iris.target_names)
print("鸢尾花的描述:
",iris.DESCR)
pyCharm 工具的安装