背景:通过课程,深入学习redis,而不是片面的了解。
参考极客时间 《146-Redis核心技术与实战》
再推荐一个redis知识点总结的网站,感觉都有覆盖,讲的也很好
http://c.biancheng.net/redis/what-is-redis.html
00|开篇词 | 这样学Redis,才能技高一筹
redis全景图
那么,所谓的 Redis 知识全景图都包括什么呢?简单来说,就是“两大维度,三大主线”。
“两大维度”就是指系统维度和应用维度,“三大主线”也就是指高性能、高可靠和高可扩展(可以简称为“三高”)。
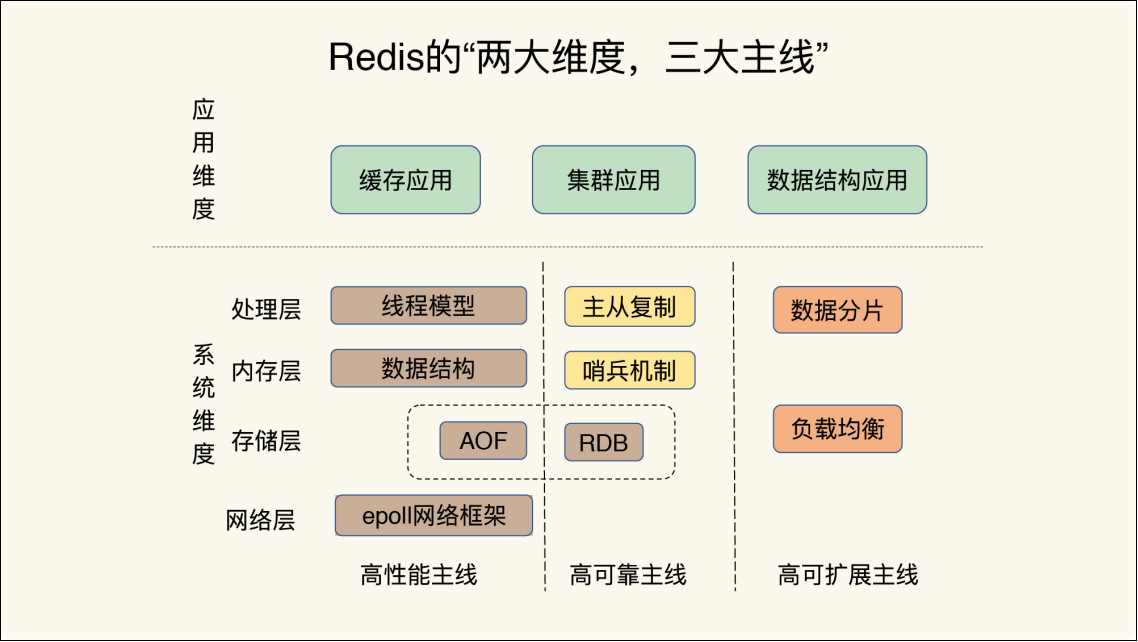
高性能主线,包括线程模型、数据结构、持久化、网络框架;
高可靠主线,包括主从复制、哨兵机制;
高可扩展主线,包括数据分片、负载均衡。
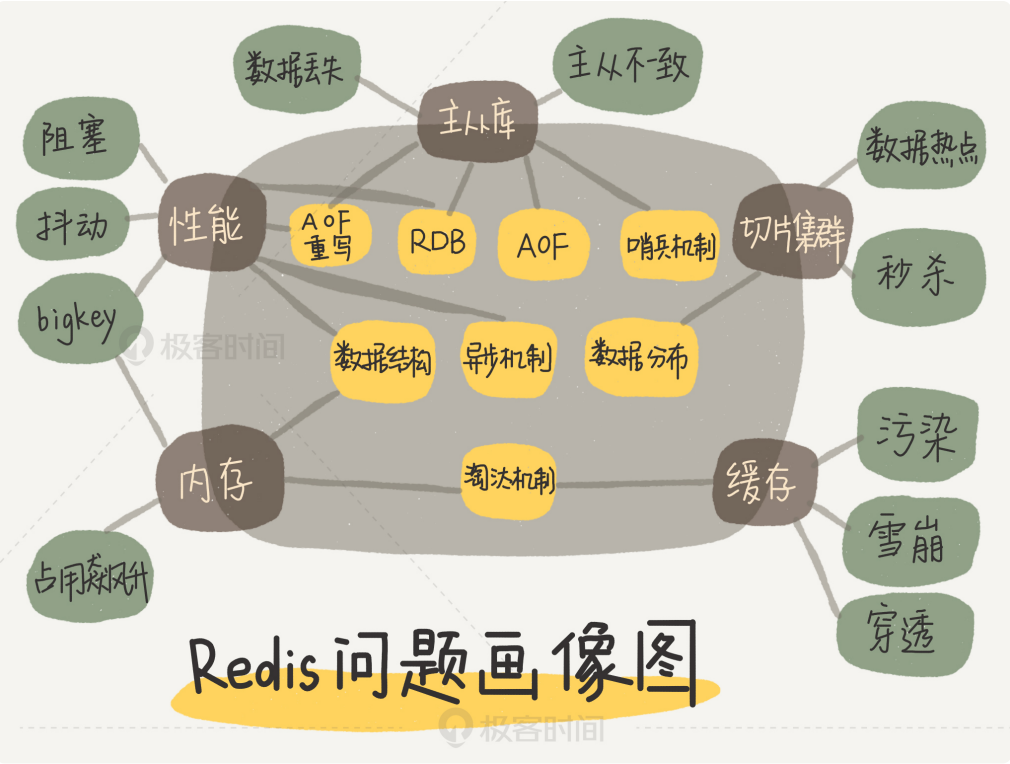
reids问题画像
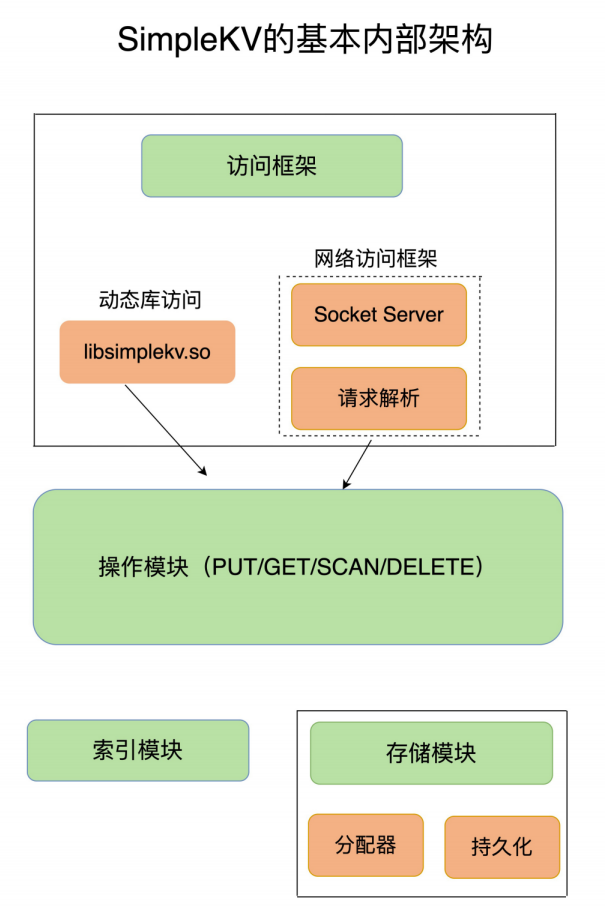
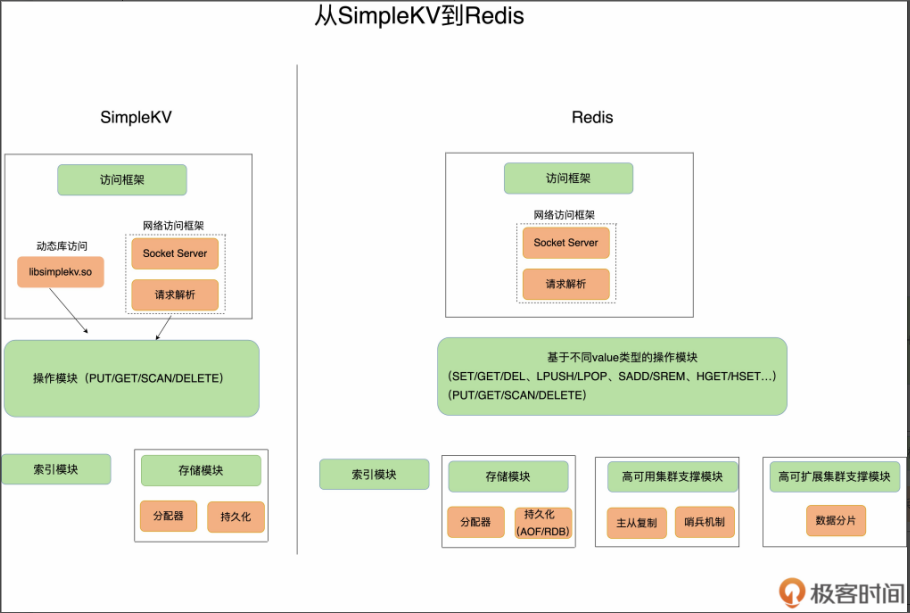
01 | 基本架构:一个键值数据库包含什么?
大体来说,一个键值数据库包括了访问框架、索引模块、操作模块和存储模块四部分(见下图)。接下来,我们就从这四个部分入手,继续构建我们的 SimpleKV。
02 | 数据结构:快速的Redis有哪些慢操作?
简单来说,底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈
希表、跳表和整数数组。它们和数据类型的对应关系如下图所示:
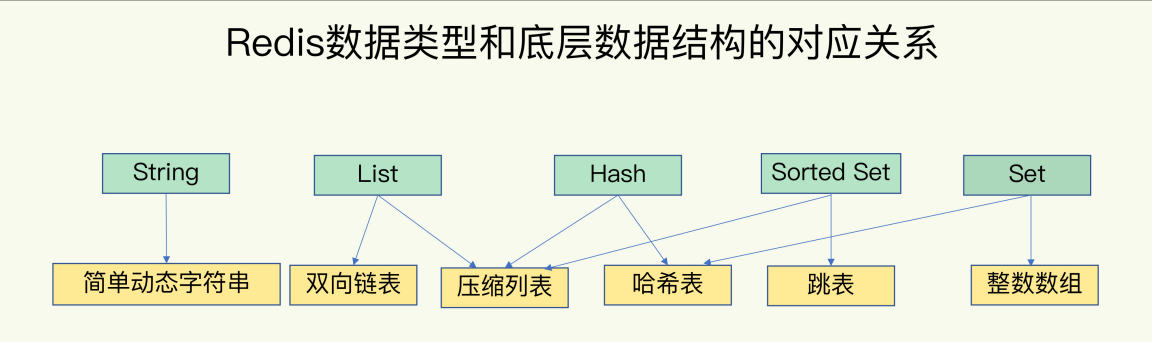
可以看到,String 类型的底层实现只有一种数据结构,也就是简单动态字符串。而 List、
Hash、Set 和 Sorted Set 这四种数据类型,都有两种底层实现结构。通常情况下,我们会
把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据。
键和值用什么结构组织?
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。
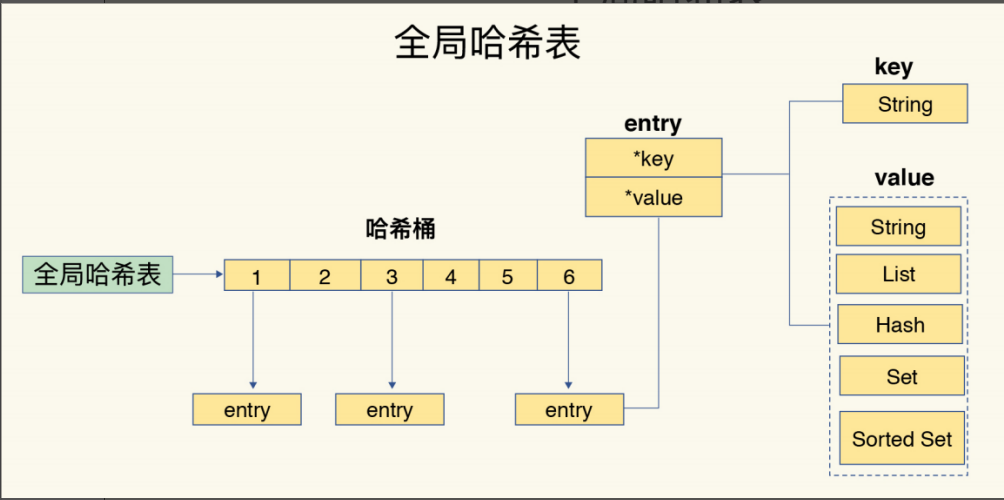
因为这个哈希表保存了所有的键值对,所以,我也把它称为全局哈希表。哈希表的最大好
处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算
键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
但是,如果你只是了解了哈希表的 O(1) 复杂度和快速查找特性,那么,当你往 Redis 中
写入大量数据后,就可能发现操作有时候会突然变慢了。这其实是因为你忽略了一个潜在
的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
Redis 解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希
桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
为了避免哈希表扩容时候的阻塞问题,Redis 采用了渐进式 rehash。
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求
时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝
到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的
entries。如下图所示:

这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操
作,保证了数据的快速访问。
集合数据操作效率
集合的操作效率和哪些因素相关呢?
首先,与集合的底层数据结构有关。例如,使用哈希表实现的集合,要比使用链表实现的
集合访问效率更高。其次,操作效率和这些操作本身的执行特点有关,比如读写一个元素
的操作要比读写所有元素的效率高
集合类型的底层数据结构主要有 5 种:整数数组、双向链表、哈
希表、压缩列表和跳表。
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同
的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的
偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。

压缩列表是为了节约Redis的内存而开发的,是由一系列的特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
zlbytes:记录整个压缩列表占用的内存字节数;zltail:记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,可以计算出表尾节点的地址;zllen:压缩列表包含的节点数量;entryX:列表节点;zlend:标记压缩列表的末端。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段
的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查
找,此时的复杂度就是 O(N) 了。
我们再来看下跳表。
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。具体来说,跳
表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,
如下图所示:


四句口诀:
单元素操作是基础;
范围操作非常耗时;
统计操作通常高效;
例外情况只有几个。