RDB持久化
文章来源 你管这破玩意叫 RDB
ps:文章简单,但是理论基础清晰,下面只写了关键认知点
RDB持久化的过程:通过frok子进程的,采用copy-on-write(写时复制)的技术,来实现内存空间数据的持久化;
为什么要fork子进行,什么是写时复制技术(从操作系统底层来理解)
写时复制
我:主人,我做好持久化方案啦!
主人:嗯我看看... 哎呀,把内存复制一份,这个想法很好,但是差了点火候呀,你对操作系统了解的还不够深入。
我:啊,为啥呢?
主人:你想想看,你现在的目的,就是为了让持久化和处理客户端命令的这两个过程所用到的内存空间隔离开,是不是?
我:嗯嗯是的。
主人:对呀,那其实你只需要新建一个进程去做持久化的过程即可,不同进程之间的内存是隔离的,也就是新建一个进程,会将原有进程的内存空间完全拷贝一份新的。
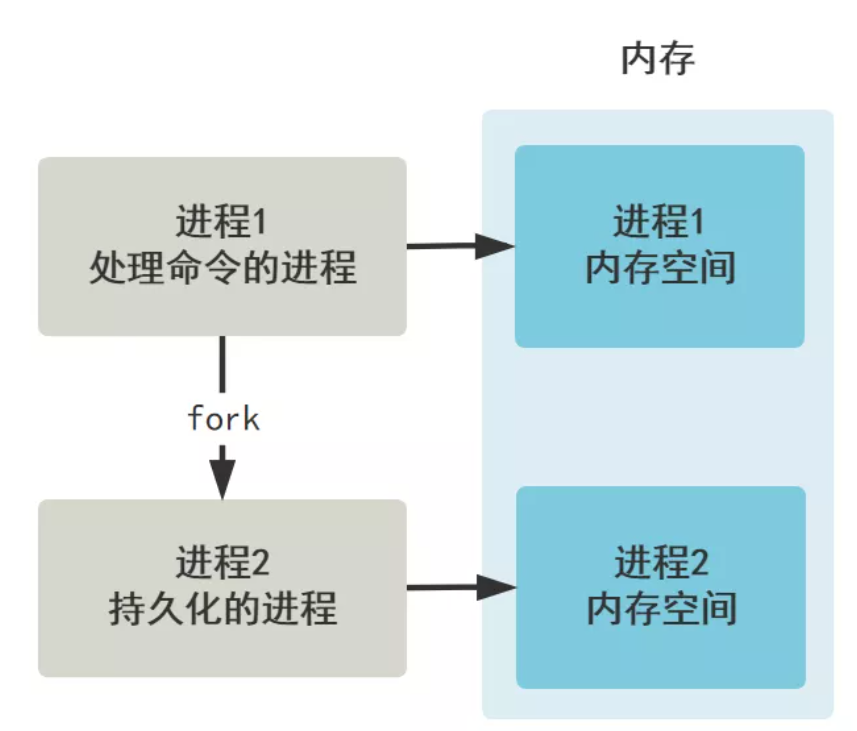
我:啊,那这不是和我自己复制一份内存一样嘛,耗时差不多吧?
主人:我刚刚的图只是给用户的感觉是这样的,实际上,linux 采用了写时复制技术,在 fork 出子进程时并没有立刻将内存进行拷贝,仅仅是拷贝了一份映射关系,让它们暂时指向同一个内存空间。
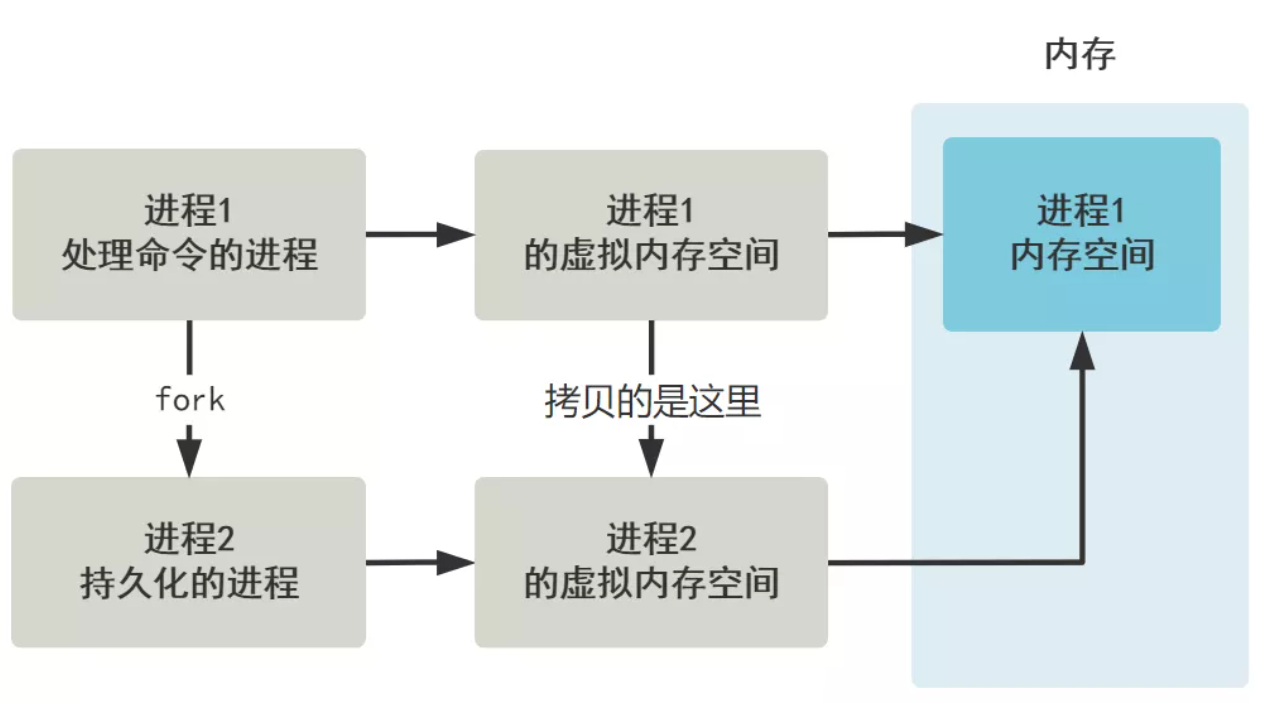
主人:而当父子进程对这块内存空间进行写操作时,才会真正复制内存,而且是以页为单位。
我:原来如此,也就是说,我可以利用操作系统的进程的写时复制内存的原理,来代替我自己复制全部内存这个方案,因为持久化过程,对内存的写操作想来也不会特别多,大多数值都是不变的,所以这样就提高了效率。主人:是的,正是如此。
我:妙呀!我赶紧把方案修改了,要持久化时我就 fork 一个子进程去做这件事,由操作系统的进程内存隔离的特征替我保证时点性,写时复制原理替我保证效率,也就是减少客户端阻塞时间,伪代码大概是这个样子。
持久化 配置
具体什么时候进行持久化 也是配置项
# Save the DB on disk: # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed save 900 1 save 300 10 save 60 10000
rdb 持久化过程,也可以手动触发,即直接输入 bgsave,同自动触发完全一样。
其在 redis 的源码中,叫做 bgsaveCommand 方法。