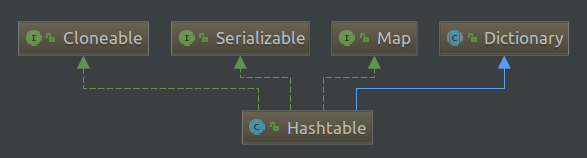
HashTable继承关系如下:
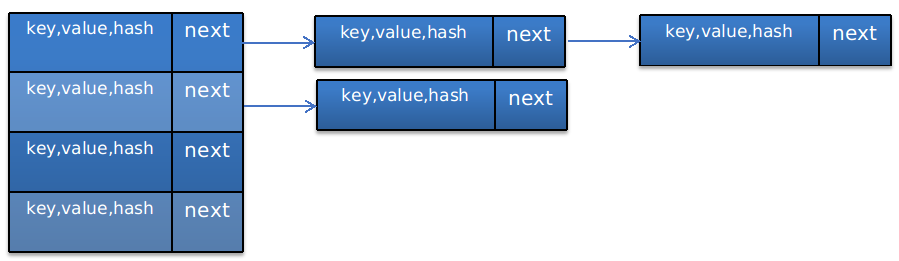
HashTable是一个线程安全的【键-值对】存储结构。其存储结构和HashMap相同,参考这里。
1. HashTable定义了一个类型为Entry<K,V>的数组table用来存储数据。
/**
* The hash table data.
*/
private transient Entry<K,V>[] table;
类型Entry<K,V>的定义如下:
/**
* Hashtable bucket collision list entry
*/
private static class Entry<K,V> implements Map.Entry<K,V> {
int hash;
final K key;
V value;
Entry<K,V> next;
}
由Entry<K,V>的定义可知,上图每个节点中其实存了4个变量:
key表示键,即存入map的键值
value表示值,即存入map的值
next表示下一个Entry节点
hash表示key的哈希值。
那么,table的图示为:
2. HashTable定义了count值来表示HashTable中元素的个数
/**
* The total number of entries in the hash table.
*/
private transient int count;
由于所有对count值进行操作的方法都是线程安全的,所以count可以精确表示HashTable中元素的个数。(在HashMap中,size()方法是不精确的)
有了精确的count值,求size() / isEmpty() 就比较简单了。
/**
* Returns the number of keys in this hashtable.
*
* @return the number of keys in this hashtable.
*/
public synchronized int size() {
return count;
}
/**
* Tests if this hashtable maps no keys to values.
*
* @return <code>true</code> if this hashtable maps no keys to values;
* <code>false</code> otherwise.
*/
public synchronized boolean isEmpty() {
return count == 0;
}
注意: 这些方法都带有synchronized关键字。
3. HashTable同样定义了
threshold: hashtable的重新扩容的阈值,一般值为(int)(capacity * loadFactor)。二般情况下是什么值呢?就是当HashTable的table数组的大小已经超过Integer最大值-8时,rehash的时候不在扩大table数组的大小,而是将threshold值放到最大。
loadFactor: 负载因子,默认是0.75f
modCount: 修改次数
代码如下:
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
*
* @serial
*/
private int threshold;
/**
* The load factor for the hashtable.
*
* @serial
*/
private float loadFactor;
/**
* The number of times this Hashtable has been structurally modified
* Structural modifications are those that change the number of entries in
* the Hashtable or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the Hashtable fail-fast. (See ConcurrentModificationException).
*/
private transient int modCount = 0;
3. HashTable默认构造函数为
/**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).
*/
public Hashtable() {
this(11, 0.75f);
}
为什么初始容量为11 ??
其中, this()调用了
/**
* Constructs a new, empty hashtable with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hashtable.
* @param loadFactor the load factor of the hashtable.
* @exception IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive.
*/
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
// 初始化table数组变量
table = new Entry[initialCapacity];
// 求threshold的值
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
initHashSeedAsNeeded(initialCapacity);
}
4. hash()方法
private int hash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();
}
5. put()方法,使用了synchronized方法修饰
/**
* Maps the specified <code>key</code> to the specified
* <code>value</code> in this hashtable. Neither the key nor the
* value can be <code>null</code>. <p>
*
* The value can be retrieved by calling the <code>get</code> method
* with a key that is equal to the original key.
*
* @param key the hashtable key
* @param value the value
* @return the previous value of the specified key in this hashtable,
* or <code>null</code> if it did not have one
* @exception NullPointerException if the key or value is
* <code>null</code>
* @see Object#equals(Object)
* @see #get(Object)
*/
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key);
// 在HashMap中,求一个key的索引位置是只用的hash & (tab.length-1)
int index = (hash & 0x7FFFFFFF) % tab.length;
// 如果已经包含了该key,更新value,并返回旧的value
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
// 如果HashTable中元素的个数已经超过了阈值threshold,需要对HashTable扩容,从新hash
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry. 这里同样是在链表头部插入元素,将当前链表的第一个节点作为新节点的下一个元素
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
// 元素个数加1
count++;
return null;
}
6. rehash(),HashTable是如何进行rehash的呢?
/**
* Increases the capacity of and internally reorganizes this
* hashtable, in order to accommodate and access its entries more
* efficiently. This method is called automatically when the
* number of keys in the hashtable exceeds this hashtable's capacity
* and load factor.
*/
protected void rehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table;
// overflow-conscious code
// oldCapacity左移1位,扩大2倍,可能会溢出
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
// 创建新的table,大小为newCapacity
Entry<K,V>[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
boolean rehash = initHashSeedAsNeeded(newCapacity);
// 更新table数组,为新的newMap
table = newMap;
// 遍历oldMap,迁移到新的newMap中
// oldMap数组的长度为oldCapacity
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
7. get()方法比较简单
(a). 根据key,求出hash值
(b). 根据hash值求出key所在的table的索引index,可以定位到链表的第一个元素
(c). 遍历链表娶老婆(元素), 娶不到返回null
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key.equals(k))},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @param key the key whose associated value is to be returned
* @return the value to which the specified key is mapped, or
* {@code null} if this map contains no mapping for the key
* @throws NullPointerException if the specified key is null
* @see #put(Object, Object)
*/
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
8. remove(),最后再来学习下remove()方法
/**
* Removes the key (and its corresponding value) from this
* hashtable. This method does nothing if the key is not in the hashtable.
*
* @param key the key that needs to be removed
* @return the value to which the key had been mapped in this hashtable,
* or <code>null</code> if the key did not have a mapping
* @throws NullPointerException if the key is <code>null</code>
*/
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
// 和get方法类似,同样是先获取到key对应的链表tab[index]
// 然后遍历链表,移除元素
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
// prev -> e ,prev是e的下一个元素,e就是要删除的元素
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
// count个数减1
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
HashTable的线程安全是使用synchronized关键字实现的,因此效率不高,所以在多线程环境下,推荐使用ConcurrentHashMap。