一:RabbitMQ介绍
RabbitMQ是AMPQ(高级消息协议队列)的标准实现。也就是说是一种消息队列。
二:RabbitMQ和线程进程queue区别
线程queue:不能跨进程,只能用于多个线程数据交互。
进程queue:只用于父进程和子进程交互或者同属于一个父进程的多个子进程间交互
如果两个不同的程序或者语言,或者不同服务器消息如何交互了?这里就可以使用RabbitMQ
三:安装RabbitMQ
RabbitMQ是由erlang语言开发的,所以要安装erlang
1)erlang安装
下载:http://erlang.org/download.html 自己根据需要下载源码包或win的二进制包
2)RabbitMQ程序安装
下载:http://www.rabbitmq.com/server.html 自己根据需要下载源码包或win的二进制包
3)python rabbitmq模块安装
pip install pika
注意:
1)windows和linux安装完成后都有rabbitmq服务 下图是windows

2)如果程序运行报如下错:pika.exceptions.ConnectionClosed
说明RabbitMQ没有安装或者RabbitMQ服务没有起动。
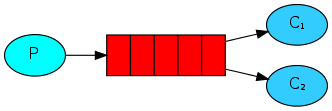
四:RabbitMQ实现最简单的队列通信模型
整个RabbitMQ的实现原理模型见下图,其实就是一个带路由任务分发队列的生产者与消费者模型。
如图所示,即生产者生产出相应的信息,发送给路由器,路由器根据信息中的关键Key信息,
将信息分发到不同的消息队列中,再由消费者去不同的消息队列中读取数据的过程。

说明:
Broker:简单来说就是消息队列服务器实体。
Exchange;消息交换机,它指定消息按什么规则,路由到那个列表。
Queue:消息队列载体,每个消息都会被投入一个或者多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing key:路由关键字,exchange根据这个关键词进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
prouducer:消息生产者,就是投递消息的程序。
conumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接,可以建立多个channel,每个channel代表一个会话任务。
消息队列使用过程大概如下:
1)客户端连接到消息队列服务器,打开一个channel.
2) 客户端声明一个exchange,并设置相关属性
3)客户端声明一个queue,并设置相关属性
4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
5)客户端投递消息到exchange
五:简单示例
生产消费
发送端producer
import pika # 建立一个实例 connection = pika.BlockingConnection( pika.ConnectionParameters('localhost',5672) # 默认端口5672,可不写 ) # 声明一个管道,在管道里发消息 channel = connection.channel() # 在管道里声明queue channel.queue_declare(queue='hello') # RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. channel.basic_publish(exchange='', routing_key='hello', # queue名字 body='Hello World!') # 消息内容 print(" [x] Sent 'Hello World!'") connection.close() # 队列关闭
import pika import time # 建立实例 connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) # 声明管道 channel = connection.channel() # 为什么又声明了一个‘hello’队列? # 如果确定已经声明了,可以不声明。但是你不知道那个机器先运行,所以要声明两次。 channel.queue_declare(queue='hello') def callback(ch, method, properties, body): # 四个参数为标准格式 print(ch, method, properties) # 打印看一下是什么 print(" [x] Received %r" % body) time.sleep(15) ch.basic_ack(delivery_tag = method.delivery_tag)
# 和no_ack=False配置使用,表示告消费端处理完了,消除queue消息。如果没有设置basic_ack如果客户断了或者其他情况,queue消息还是存在会发给其他消费端 channel.basic_consume( # 消费消息 callback, # 如果收到消息,就调用callback函数来处理消息 queue='hello', # 你要从那个队列里收消息 # no_ack=True # 如果设置no_ack=True表示,不管消费端有没有处理完,都清除queue消息,默认是no_ack=False,表示保留消息 ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 开始消费消息
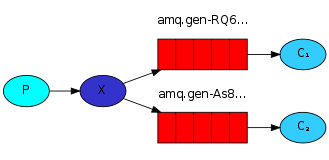
六:RabbitMQ 消息分发轮询
问题1:上面的只是一个生产者、一个消费者,能不能一个生产者多个消费者呢?
RabbitMQ会默认采用轮询机制;把消息依次分发。把p发的消息依次分发给各个消费者(c),跟负载均衡差不多。
问题2:如果消费端程序没有运行结束,就受到中断或者RabbitMQ服务中断,queue中的消息是还存在?
两种模式:
如果设置no_ack=True表示,不管消费端有没有处理完,都清除queue中消息。
默认是no_ack=False,表示保留消息。当消费端中断消息会发其他消费端。当设置了basic_ack(delivery_tag = method.delivery_tag) 表示
表示告消费端处理完了,消除queue中消息,如果没有设置,表示消息还在队列中。
七:RabbitMQ 消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,
一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。
为解决此问题,可以在各个消费者端,配置perfetch=1,
意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
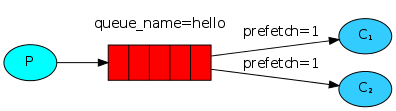
只需要在消费者端,channel.basic_consume前加上就可以了
channel.basic_qos(prefetch_count=1) # 类似权重,按能力分发,如果有一个消息,就不在给你发 channel.basic_consume( # 消费消息
八:RabbitMQ 消息持久化
上面的效果消费端断了就转到另外一个消费端去了,但是生产者怎么知道消费端断了呢?
因为生产者和消费者是通过socket连接的,socket断了,就说明消费端断开了。
如果生产者中断某种RabbitMQ服务中断消息是否还存在了?答案消息丢失了。为了解决上面问题需要对队列和消息设置持久化
这个地方需要设置两个地方:
1)队列持久化
在管理声明时候设置 durable=True,表示队列设置了持久化,注意这里只是队列持久化,但是消息还没有持久化。
# 在管道里声明queue channel.queue_declare(queue='hello2', durable=True)
2)消息持久化
在basic_publish里添加properties设置delivery_mode=2
channel.basic_publish(exchange='', routing_key='hello2', body='Hello World!', properties=pika.BasicProperties( delivery_mode=2, # make message persistent ) )
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost',5672)) # 默认端口5672,可不写 channel = connection.channel() #声明queue channel.queue_declare(queue='hello2', durable=True) #durable=True设置队列序列化
#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='', routing_key='hello2', body='Hello World!',
properties=pika.BasicProperties( delivery_mode=2, # make message persistent ) )
print(" [x] Sent 'Hello World!'")
connection.close()
import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel() channel.queue_declare(queue='hello2', durable=True) def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(10) ch.basic_ack(delivery_tag = method.delivery_tag) # 告诉生产者,消息处理完成 channel.basic_qos(prefetch_count=1) # 类似权重,按能力分发,如果有一个消息,就不在给你发 channel.basic_consume( # 消费消息 callback, # 如果收到消息,就调用callback queue='hello2', # no_ack=True # 一般不写,处理完接收处理结果。宕机则发给其他消费者 ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
九:PublishSubscribe(消息发布订阅)
前面的效果都是一对一发,如果做一个广播效果可不可以,这时候就要用到exchange了
exchange必须精确的知道收到的消息要发给谁。exchange的类型决定了怎么处理,
类型有以下几种:
- fanout: 所有绑定到此exchange的queue都可以接收消息
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
1)fanout模式
消息publisher
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') message = ' '.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close()
#_*_coding:utf-8_*_ __author__ = 'Alex Li' import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_name = result.method.queue channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
2)选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列

import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error] " % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
3)更细致的消息过滤

import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]... " % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
十:RabbitMQ RPC 实现(Remote procedure call)
上面的流都是单向的,如果远程的机器执行完返回结果,就实现不了了。
如果返回,这种模式叫什么呢,RPC(远程过程调用),snmp就是典型的RPC
RabbitMQ能不能返回呢,怎么返回呢?既是发送端又是接收端。
但是接收端返回消息怎么返回?可以发送到发过来的queue里么?不可以。
返回时,再建立一个queue,把结果发送新的queue里
为了服务端返回的queue不写死,在客户端给服务端发指令的的时候,同时带一条消息说,你结果返回给哪个queue
RPC Server
import pika import uuid import time class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, # 只要一收到消息就调用on_response no_ack=True, queue=self.callback_queue) # 收这个queue的消息 def on_response(self, ch, method, props, body): # 必须四个参数 # 如果收到的ID和本机生成的相同,则返回的结果就是我想要的指令返回的结果 if self.corr_id == props.correlation_id: self.response = body def call(self, n): self.response = None # 初始self.response为None self.corr_id = str(uuid.uuid4()) # 随机唯一字符串 self.channel.basic_publish( exchange='', routing_key='rpc_queue', # 发消息到rpc_queue properties=pika.BasicProperties( # 消息持久化 reply_to = self.callback_queue, # 让服务端命令结果返回到callback_queue correlation_id = self.corr_id, # 把随机uuid同时发给服务器 ), body=str(n) ) while self.response is None: # 当没有数据,就一直循环 # 启动后,on_response函数接到消息,self.response 值就不为空了 self.connection.process_data_events() # 非阻塞版的start_consuming() # print("no msg……") # time.sleep(0.5) # 收到消息就调用on_response return int(self.response) if __name__ == '__main__': fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(7)") response = fibonacci_rpc.call(7) print(" [.] Got %r" % response)
Client
import pika import time def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) ch.basic_publish( exchange='', # 把执行结果发回给客户端 routing_key=props.reply_to, # 客户端要求返回想用的queue # 返回客户端发过来的correction_id 为了让客户端验证消息一致性 properties=pika.BasicProperties(correlation_id = props.correlation_id), body=str(response) ) ch.basic_ack(delivery_tag = method.delivery_tag) # 任务完成,告诉客户端 if __name__ == '__main__': connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') # 声明一个rpc_queue , channel.basic_qos(prefetch_count=1) # 在rpc_queue里收消息,收到消息就调用on_request channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming()
十一:总结
1.概念:
Connection: 一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。程序的起始处就是建立这个TCP连接。
Channels: 虚拟连接。建立在上述的TCP连接中。数据流动都是在Channel中进行的。一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
2.队列:
首先建立一个Connection,然后建立Channels,在channel上建立队列
建立时指定durable参数为真,队列将持久化;指定exclusive为真,队列为临时队列,
关闭consumer后该队列将不再存在,一般情况下建立临时队列并不指定队列名称, rabbitmq将随机起名,通过result.method.queue来获取队列名:
result = channel.queue_declare(exclusive=True)
result.method.queue
区别:durable是队列持久化与否,如果为真,队列将在rabbitmq服务重启后仍存在,如果为假,rabbitmq服务重启前不会消失,与consumer关闭与否无关;
而exclusive是建立临时队列,当consumer关闭后,该队列就会被删除
3.exchange和bind
Exchange中durable参数指定exchange是否持久化,exchange参数指定exchange名称,type指定exchange类型。Exchange类型有direct,fanout和topic。
Bind是将exchange与queue进行关联,exchange参数和queue参数分别指定要进行bind的exchange和queue,routing_key为可选参数。
Exchange的三种模式:
Direct:
任何发送到Direct Exchange的消息都会被转发到routing_key中指定的Queue
1.一般情况可以使用rabbitMQ自带的Exchange:””(该Exchange的名字为空字符串);
2.这种模式下不需要将Exchange进行任何绑定(bind)操作;
3.消息传递时需要一个“routing_key”,可以简单的理解为要发送到的队列名字;
4.如果vhost中不存在routing_key中指定的队列名,则该消息会被抛弃。
Demo中虽然声明了一个exchange='yanfa'和queue='anheng'的bind,但是在后面发送消息时并没有使用该exchange和bind,
而是采用了direct的模式,没有指定exchange,而是指定了routing_key的名称为队列名,消息将发送到指定队列。
如果一个exchange 声明为direct,并且bind中指定了routing_key,那么发送消息时需要同时指明该exchange和routing_key.
Fanout:
任何发送到Fanout Exchange的消息都会被转发到与该Exchange绑定(Binding)的所有Queue上
1.可以理解为路由表的模式
2.这种模式不需要routing_key
3.这种模式需要提前将Exchange与Queue进行绑定,一个Exchange可以绑定多个Queue,一个Queue可以同多个Exchange进行绑定。
4.如果接受到消息的Exchange没有与任何Queue绑定,则消息会被抛弃。
Demo中创建了一个将一个exchange和一个queue进行fanout类型的bind.但是发送信息时没有用到它,
如果要用到它,只要在发送消息时指定该exchange的名称即可,该exchange就会将消息发送到所有和它bind的队列中。在fanout模式下,指定的routing_key是无效的 。
Topic:
任何发送到Topic Exchange的消息都会被转发到所有关心routing_key中指定话题的Queue上
1.这种模式较为复杂,简单来说,就是每个队列都有其关心的主题,所有的消息都带有一个“标题”(routing_key),
Exchange会将消息转发到所有关注主题能与routing_key模糊匹配的队列。
2.这种模式需要routing_key,也许要提前绑定Exchange与Queue。
3.在进行绑定时,要提供一个该队列关心的主题,如“#.log.#”表示该队列关心所有涉及log的消息(一个routing_key为”MQ.log.error”的消息会被转发到该队列)。
4.“#”表示0个或若干个关键字,“*”表示一个关键字。如“log.*”能与“log.warn”匹配,无法与“log.warn.timeout”匹配;但是“log.#”能与上述两者匹配。
5.同样,如果Exchange没有发现能够与routing_key匹配的Queue,则会抛弃此消息。
4.任务分发
1.Rabbitmq的任务是循环分发的,如果开启两个consumer,producer发送的信息是轮流发送到两个consume的。
2.在producer端使用cha.basic_publish()来发送消息,其中body参数就是要发送的消息,properties=pika.BasicProperties(delivery_mode = 2,)启用消息持久化,可以防止RabbitMQ Server 重启或者crash引起的数据丢失。
3.在接收端使用cha.basic_consume()无限循环监听,如果设置no-ack参数为真,每次Consumer接到数据后,而不管是否处理完成,RabbitMQ Server会立即把这个Message标记为完成,然后从queue中删除了。为了保证数据不被丢失,RabbitMQ支持消息确认机制,即acknowledgments。为了保证数据能被正确处理而不仅仅是被Consumer收到,那么我们不能采用no-ack。而应该是在处理完数据后发送ack。
在处理数据后发送的ack,就是告诉RabbitMQ数据已经被接收,处理完成,RabbitMQ可以去安全的删除它了。如果Consumer退出了但是没有发送ack,那么RabbitMQ就会把这个Message发送到下一个Consumer。这样就保证了在Consumer异常退出的情况下数据也不会丢失。
这里并没有用到超时机制。RabbitMQ仅仅通过Consumer的连接中断来确认该Message并没有被正确处理。也就是说,RabbitMQ给了Consumer足够长的时间来做数据处理。
Demo的callback方法中ch.basic_ack(delivery_tag = method.delivery_tag)告诉rabbitmq消息已经正确处理。如果没有这条代码,Consumer退出时,Message会重新分发。然后RabbitMQ会占用越来越多的内存,由于RabbitMQ会长时间运行,因此这个“内存泄漏”是致命的。去调试这种错误,可以通过一下命令打印un-acked Messages:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
4.公平分发:设置cha.basic_qos(prefetch_count=1),这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理一个Message。换句话说,在接收到该Consumer的ack前,他它不会将新的Message分发给它。