理论部分具体还是参考的
1 相关概念
1.1 什么是JDBC
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
1.2 数据库驱动
我们安装好数据库之后,我们的应用程序也是不能直接使用数据库的,必须要通过相应的数据库驱动程序去和数据库打交道。其实也就是数据库厂商的JDBC接口实现,即对数据库连接等操作进行支持的jar文件。
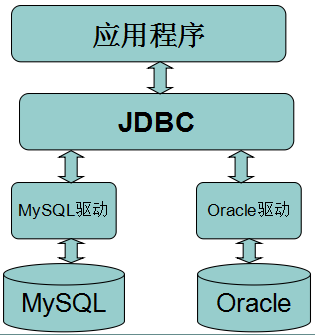
2、常用接口
2.1 Driver
在编程中要连接数据库,必须先装载特定厂商的数据库驱动程序。在将对应驱动的jar包配置到项目的lib之后,可以按照不同数据库的情况装载驱动:
/*装载MySQL驱动*/ Class.forName("com.mysql.jdbc.Driver"); /*装载Oralce驱动*/ Class.forName("oracle.jdbc.driver.OracleDriver");
2.2 Connection
Connection与特定数据库的连接(会话),在连接上下文中执行sql语句并返回结果。
/*连接MySQL数据库*/ Connection conn = DriverManager.getConnection("jdbc:mysql://host:port/database","user","password") /*连接ORACLE数据库*/ Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@host:port:database","user","password") /*连接SQL SERVER数据库*/ Connection conn = DriverManager.getConnection("jdbc:microsoft:sqlserver://host:port;DatabaseName=database","user","password")
常用方法:
-
createStatement():创建向数据库发送sql的statement对象。 -
prepareStatement():创建向数据库发送预编译sql的PreparedStatement对象。 -
prepareCall():创建执行存储过程的callableStatement对象。 -
setAutoCommit():设置事务是否自动提交。 -
commit():在链接上提交事务。 -
rollback():在链接上回滚事务。
2.3 Statement
用于执行静态SQL语句并返回它所生成结果的对象。
三种Statement类:
-
Statement:由createStatement创建,用于发送简单的SQL语句(不带参数)。 -
PreparedStatement:继承自Statement接口,由prepareStatement创建,用于发送含有一个或多个参数的SQL语句。PreparedStatement对象比Statement对象效率更高,并且可以防止SQL注入,所以我们一般使用PreparedStatement。 -
CallableStatement:继承自PreparedStatement,由方法prepareCall创建,用于调用存储过程。
常用的Statement方法:
-
execute(String sql):运行语句,返回是否有结果集。 -
executeQuery(String sql):运行select语句,返回ResultSet结果集。 -
executeUpdate(String sql):运行insert/update/delete操作,返回更新的行数。 -
addBatch:把多条sql语句方法一个批处理中。 -
executeBatch:想数据库发送一批sql语句执行。
2.4 ResultSet
ResultSet提供检索不同类型字段的方法,常用的有:
-
getString(int index)、getString(String columnName):获得在数据库里是varchar、char等类型的数据对象。 -
getFloat(int index)、getFloat(String columnName):获得在数据库里是Float类型的数据对象。 -
getDate(int index)、getDate(String columnName):获得在数据库里是Date类型的数据。 -
getBoolean(int index)、getBoolean(String columnName):获得在数据库里是Boolean类型的数据。 -
getObject(int index)、getObject(String columnName):获取在数据库里任意类型的数据。
ResultSet还提供了对结果集进行滚动的方法:
-
next():移动到下一行 -
Previous():移动到前一行 -
absolute(int row):移动到指定行 -
beforeFirst():移动resultSet的最前面。 -
afterLast():移动到resultSet的最后面。
使用后依次关闭对象及连接:ResultSet → Statement → Connection。
3、实践一:简单地使用JDBC创建连接,向数据库表插入数据
3.1 数据库驱动下载
我们常用的Oracle和MySQL数据库的驱动下载如下,需要下载对应版本的驱动:
MySQL的数据库驱动可以访问官网:https://dev.mysql.com/downloads/connector/j/下载。后续更加具体的配置可以看

Oracle的数据库驱动我看到更多的是付费下载,或者说找到了一个好心人:
3.2 数据库驱动配置的问题
使用的是IntelliJ IDEA+maven。所以先配置xml文件,添加如下依赖,版本号可以按照自己的情况添加。
<dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.39</version> </dependency> </dependencies>
如果没有将对应驱动的jar包配置好,如配置到maven仓库,那么上面语句的mysql-connector-java会被标红。
但是配置到这里,也有可能会在运行的时候报错ClassNotFoundException: com.mysql.jdbc.Driver.
需要右击项目名称,选择Maven-Reimport。最后驱动显示在lib列表中就可以使用了。
3.3 代码
数据库连接的流程是
-
加载驱动
-
获取数据库连接
Connection -
创建用于运行
sql语句的Statement/PreparedStatement -
运行
sql语句并返回结果(结果可能是结果集ResultSet) -
关闭
ResultSet(如果存在) -
关闭
Statement/PreparedStatement -
关闭数据库连接
Connection


package com.lwx.sjcoding; import java.sql.*; import java.util.Collection; public class JDBCMySQLConnect { private final static String DB_URL= "jdbc:mysql://localhost:3306/learn?useSSL=true&useUnicode=true&characterEncoding=UTF-8"; private final static String USER_NAME = "root"; private final static String PSW= "123456"; private final static String DRIVER = "com.mysql.jdbc.Driver"; static { /** * 加载驱动 */ try{ Class.forName(DRIVER); }catch (ClassNotFoundException e){ e.printStackTrace(); } } /** * 建立连接 */ public static Connection getConnection(){ try{ return DriverManager.getConnection(DB_URL,USER_NAME,PSW); }catch (SQLException e) { e.printStackTrace(); } return null; } /** * 创建statement */ public static Statement createStatement(Connection connection){ try{ return connection.createStatement(); }catch (SQLException e) { e.printStackTrace(); } return null; } /* * 创建 preparedStatement * */ public static PreparedStatement prepareStatement(Connection connection,String sql){ try{ return connection.prepareStatement(sql); }catch (SQLException e) { e.printStackTrace(); } return null; } /* * 关闭连接 * */ public static void close(Connection connection,Statement statement,PreparedStatement preparedStatement,ResultSet resultSet){ try { if(resultSet!=null){ resultSet.close(); } } catch (SQLException e) { e.printStackTrace(); } try { if(statement!=null){ statement.close(); } } catch (SQLException e) { e.printStackTrace(); } try { if(preparedStatement!=null){ preparedStatement.close(); } } catch (SQLException e) { e.printStackTrace(); } try { if(connection!=null){ connection.close(); } } catch (SQLException e) { e.printStackTrace(); } } public static void main(String[] args){ Connection connection = JDBCMySQLConnect.getConnection(); String sql = "insert into anagrams(item_key,item) values(?,?)"; PreparedStatement preparedStatement = JDBCMySQLConnect.prepareStatement(connection,sql); try { preparedStatement.setString(1,"ssssssss"); preparedStatement.setString(2,"sssssss"); int result = preparedStatement.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } JDBCMySQLConnect.close(connection,null,preparedStatement); } }
3.4 Statement和PreparedStatement问题
Statement用于运行原始的sql语句,有些语句需要拼接形成,每次运行都进行一次编译。
String sql = "select * from mytable where id = "+myid;
ResultSet rSet = statement.executeQuery(Sql);
PreparedStatement有预编译的过程,传入的是带参数的sql语句,批量语句中可只进行一次预编译,可提高效率,同时也防止了SQL注入。
String sql = "select * from mytable where id = ?";
推荐使用PreparedStatement。
3.5 ?useSSL=true的意义
private final static String DB_URL1= "jdbc:mysql://localhost:3306/learn";
使用上面的代码会报警告如下,主要是说需要指定useSSL为true或者false。
Sun Aug 29 16:38:27 CST 2021 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
譬如说,这样子:
private final static String DB_URL2= "jdbc:mysql://localhost:3306/learn?useSSL=true";
当设置useSSL=false的时候即不启用SSL连接。当设置useSSL=true的时候需要进行SSL连接的一些配置,如查看MySQL数据库是否支持SSL、配置私钥公钥等等。
配置SSL连接对性能影响不大,不过,一般,如果数据库和程序在同一服务器上,可以不需要配置SSL。
4、实践二:数据库批量插入
4.1 代码
package com.lwx.sjcoding; import java.sql.*; import java.text.SimpleDateFormat; import java.util.Collection; import java.util.Random; public class JDBCMySQLConnect { private final static String DB_URL= "jdbc:mysql://localhost:3306/learn?useSSL=true&useUnicode=true&characterEncoding=UTF-8"; private final static String USER_NAME = "root"; private final static String PSW= "123456"; private final static String DRIVER = "com.mysql.jdbc.Driver"; static { /** * 加载驱动 */ try{ Class.forName(DRIVER); }catch (ClassNotFoundException e){ e.printStackTrace(); } } /** * 建立连接 */ public static Connection getConnection(){ try{ return DriverManager.getConnection(DB_URL,USER_NAME,PSW); }catch (SQLException e) { e.printStackTrace(); } return null; } /** * 创建statement */ public static Statement createStatement(Connection connection){ try{ return connection.createStatement(); }catch (SQLException e) { e.printStackTrace(); } return null; } /* * 创建 preparedStatement * */ public static PreparedStatement prepareStatement(Connection connection,String sql){ try{ return connection.prepareStatement(sql); }catch (SQLException e) { e.printStackTrace(); } return null; } /* * 关闭连接 * */ public static void close(Connection connection,Statement statement,PreparedStatement preparedStatement,ResultSet resultSet){ try { if(resultSet!=null){ resultSet.close(); } } catch (SQLException e) { e.printStackTrace(); } try { if(statement!=null){ statement.close(); } } catch (SQLException e) { e.printStackTrace(); } try { if(preparedStatement!=null){ preparedStatement.close(); } } catch (SQLException e) { e.printStackTrace(); } try { if(connection!=null){ connection.close(); } } catch (SQLException e) { e.printStackTrace(); } } /*是否自动提交*/ public static void setAutoCommit(Connection connection,boolean f){ try { connection.setAutoCommit(f); } catch (SQLException e) { e.printStackTrace(); } } public static void main(String[] args){ JDBCMySQLConnect jdbcMySQLConnect = new JDBCMySQLConnect(); jdbcMySQLConnect.insertTest(0,1000000,10000); } public void insertTest(int start,int end,int limit){ Connection connection = JDBCMySQLConnect.getConnection(); JDBCMySQLConnect.setAutoCommit(connection,false); String tableName1 = "a_table"; String tableName2 = "b_table"; String tableName3 = "c_table"; Statement statement = JDBCMySQLConnect.createStatement(connection); JDBCMySQLConnect.clearTable(statement,tableName1); JDBCMySQLConnect.clearTable(statement,tableName2); JDBCMySQLConnect.clearTable(statement,tableName3); statementInsert(connection,tableName1,start,end,limit); preparedStatamentInsert(connection,tableName2,start,end,limit); bacthInsert(connection,tableName3,start,end,limit); JDBCMySQLConnect.close(connection,statement,null,null); } public void statementInsert(Connection connection,String tableName,int start,int end,int limit){ if(end<start) return;; long time = System.currentTimeMillis(); SimpleDateFormat form = new SimpleDateFormat("yyyyMMddHHmmss"); Statement statement = JDBCMySQLConnect.createStatement(connection); for(int i=start;i<end;i++){ try { String sql = String.format("insert into "+tableName+"(id,item,time) values(%d,'%s','%s')",i,"aaa",form.format(new Date(System.currentTimeMillis()))+i); statement.executeUpdate(sql); if (i % limit == 0){ connection.commit(); } } catch (Exception e) { e.printStackTrace(); } } System.out.println("Statement limit "+limit+", "+(end-start)+" Cost: "+(System.currentTimeMillis()-time)*1.0/1000+"ms"); JDBCMySQLConnect.close(null,statement,null,null); } public void preparedStatamentInsert(Connection connection,String tableName ,int start,int end,int limit){ if(end<start) return;; long time = System.currentTimeMillis(); SimpleDateFormat form = new SimpleDateFormat("yyyyMMddHHmmss"); String sql = "insert into "+tableName+"(id,item,time) values(?,?,?)"; PreparedStatement preparedStatement = JDBCMySQLConnect.prepareStatement(connection,sql); for(int i=start;i<end;i++){ try { preparedStatement.setInt(1,i); preparedStatement.setString(2,"aaa"); preparedStatement.setString(3,form.format(new Date(System.currentTimeMillis()))+i); preparedStatement.executeUpdate(); if (i % limit == 0){ connection.commit(); } } catch (SQLException e) { e.printStackTrace(); } } System.out.println("PreparedStatement limit "+limit+", "+(end-start)+" Cost: "+(System.currentTimeMillis()-time)*1.0/1000+"ms"); JDBCMySQLConnect.close(null,null,preparedStatement,null); } public void bacthInsert(Connection connection,String tableName ,int start,int end,int limit){ if(end<start || limit<=0) return;; long time = System.currentTimeMillis(); SimpleDateFormat form = new SimpleDateFormat("yyyyMMddHHmmss"); String sql = "insert into "+tableName+"(id,item,time) values(?,?,?)"; PreparedStatement preparedStatement = JDBCMySQLConnect.prepareStatement(connection,sql); try { for(int i=start;i<end;i++){ preparedStatement.setInt(1,i); preparedStatement.setString(2,"aaa"); preparedStatement.setString(3,form.format(new Date(System.currentTimeMillis()))+i); preparedStatement.addBatch(); // 1w条记录插入一次 if (i % limit == 0){ preparedStatement.executeBatch(); connection.commit(); } } preparedStatement.executeBatch(); connection.commit(); } catch (SQLException e) { e.printStackTrace(); } System.out.println("Batch limit "+limit+", "+(end-start)+" Cost: "+(System.currentTimeMillis()-time)*1.0/1000+"ms"); JDBCMySQLConnect.close(null,null,preparedStatement,null); } public static void clearTable(Statement statement,String tableName){ try { statement.executeUpdate("truncate table "+tableName); } catch (SQLException e) { e.printStackTrace(); } } //创建随机长度的随机字符串 public static String getRandomString(){ Random random=new Random(); int length = random.nextInt(50)+1; String str="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"; StringBuffer sb=new StringBuffer(); for(int i=0;i<length;i++){ int number=random.nextInt(62); sb.append(str.charAt(number)); } return sb.toString(); } }
4.2 Statement和PreparedStatement使用问题
上述代码最终结果是:
10W条记录: Statement limit 10000, 100000 Cost: 11.963ms PreparedStatement limit 10000, 100000 Cost: 14.627ms Batch limit 10000, 100000 Cost: 12.513ms 100W条记录: Statement limit 10000, 1000000 Cost: 119.002ms PreparedStatement limit 10000, 1000000 Cost: 123.422ms Batch limit 10000, 1000000 Cost: 119.148ms
前面我经历了
-
“怎么也实现不了使用
Preparedstatement插入数据比使用Statement快” -
“以为找到了方法使用
Preparedstatement比使用Statement快近十倍” -
“以为使用
Preparedstatement比使用Statement快了一点,数据量越大越明显” -
“还是怎么也实现不了使用
Preparedstatement插入数据比使用Statement快”
网上一查Statement和PreparedStatement的区别,就是说PreparedStatement效率较高的,我也有去看一些别人的代码,复制粘贴下来跑一跑,结果跟文章描述的“使用Preparedstatement插入数据比使用Statement快”是相反的。不清楚是不是表格设计的问题,不过三张表都是一个结构。
CREATE TABLE `a_table` ( `id` int(11) NOT NULL, `item` varchar(255) DEFAULT NULL, `time` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8
我是真的没有试验出来在批量插入的效率上,PreparedStatement优于Statement,要么是表结构的问题,要么就是我试验方法的问题,前面四个阶段的原因分别为:
-
“怎么也实现不了使用
Preparedstatement插入数据比使用Statement快”:setAutoCommit使用了默认的true,即自动提交。 -
“以为找到了方法使用
Preparedstatement比使用Statement快近十倍”:关闭自动提交后,Statement部分代码每运行一次executeUpdate则commit一次,而PreparedStatement.addBatch则每1W条提交一次commit一次。感觉大部分人是这个方法,但是我感觉主要是因为commit。 -
“以为使用
Preparedstatement比使用Statement快了一点,数据量越大越明显”:都更改为每1W条commit一次,后面发现是因为Statement的那个表,我之前设置了主键id,导致插入速度变慢。 -
“还是怎么也实现不了使用
Preparedstatement插入数据比使用Statement快”:就这样了
或许不够严谨,但是在效率上我的确没有看到Preparedstatement明显优于Statement的地方。但是考虑防止SQL注入等等原因,批量处理的时候使用PreparedStatement.addBatch应该还是推荐的吧。
4.3 setAutoCommit的问题
setAutoCommit用于设定是否自动提交,默认是true。一开始我就忽略了这个,所以结果如下。
Statement limit 100000 Cost: 76.795ms PreparedStatement limit 100000 Cost: 76.555ms Batch limit 100000 Cost: 78.427ms
因为设定自动提交,那么对于么一条insert语句,都会产生一条log写入磁盘,即使设置了批量插入,但其效果就像单条插入一样,导致插入速度十分缓慢。
无论对于Statement还是PreparedStatement,或是PreparedStatement.addBatch,在插入10W条数据的时候,是否是每次插入都进行一次commit,还是说隔1W条记录commit一次,这才是消耗时间是10ms左右还是77ms左右的关键因素。
4.4 设置主键为什么会使得数据插入变慢
之前了解索引的时候好像有提及,主键是唯一的,每次插入前需要确定插入的数据是否唯一,会产生额外的时间消耗。
5、实践三:有关索引
5.1 查看索引、创建索引和删除索引
5.1.1 查看索引
--查看索引 show index from a_table; show index from b_table; show index from c_table;
5.1.2 删除索引
--删除索引 alter table a_table drop index id;
5.1.3 创建索引
聚簇索引,决定了表的物理结构,一般来说默认是表的主键,或者若没有主键,会在第一个唯一的非空字段上创建,或者会创建一个隐含的字段作为聚簇索引。聚簇索引相关的说法众说纷纭,有人说过可以在非唯一字段上创建(但是我没试过不清楚怎么做),也可以在一些更实用的字段(如时间)上创建,创建在自增序列上反而是浪费;也有人说创建在自增序列上是最好的,可以减少插入时维护的成本。
也可以创建复合主键。
ALTER TABLE `user` ADD PRIMARY KEY ( `aa` )
非聚簇索引,会消耗额外的空间维护一个B+树,会指向表(聚簇索引)的位置。如果数据能在非聚簇索引的树上找到就无需到表的位置。可创建复合索引、前缀索引、唯一索引。
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name (index_col_name,...) index_col_name: col_name [(length)] [ASC | DESC]
详细概念可了解:
5.1.4 主键索引
前面我们获得一个表a_table,数据量100W,id和time都是唯一的,item都是重复数据。而id是有序的递增序列。
public void selectTest(int start,int end){ Connection connection = JDBCMySQLConnect.getConnection(); String tableName1 = "a_table"; String tableName2 = "b_table"; String tableName3 = "c_table"; long time = System.currentTimeMillis(); String sql = "select * from "+tableName1+" where id = ? "; PreparedStatement preparedStatement = JDBCMySQLConnect.prepareStatement(connection,sql); ResultSet resultSet=null; try{ for(int i=start;i<end;i++){ preparedStatement.setInt(1,i); //preparedStatement.setString(2,"aaa"); resultSet = preparedStatement.executeQuery(); } }catch (SQLException e){ e.printStackTrace(); } System.out.println("select: "+(end-start)+" Cost: "+(System.currentTimeMillis()-time)*1.0/1000+"ms"); JDBCMySQLConnect.close(connection,null,null,resultSet); } public static void main(String[] args){ JDBCMySQLConnect jdbcMySQLConnect = new JDBCMySQLConnect(); //jdbcMySQLConnect.insertTest(0,1000000,10000); jdbcMySQLConnect.selectTest(0,10); jdbcMySQLConnect.selectTest(0,100); jdbcMySQLConnect.selectTest(0,1000); }
未创建主键:
select: 10 Cost: 3.303ms select: 100 Cost: 30.571ms select: 1000 Cost: 335.367ms ALTER TABLE a_table ADD PRIMARY KEY ( id );创建主键: select: 10 Cost: 0.011ms select: 100 Cost: 0.03ms select: 1000 Cost: 0.153ms
查询速度十分明显地变快。
还有一个使用String sql = "select * from "+tableName1+" where id <= "+limt;,结果如下
未创建主键索引: select: 10 Cost: 0.339ms select: 100 Cost: 0.391ms select: 1000 Cost: 0.312ms 创建了主键索引: select: 10 Cost: 0.019ms select: 100 Cost: 0.001ms select: 1000 Cost: 0.003ms
5.1.5 创建普通索引
public void selectTest(String sql){ Connection connection = JDBCMySQLConnect.getConnection(); long time = System.currentTimeMillis(); Statement statement = JDBCMySQLConnect.createStatement(connection); ResultSet resultSet = null; try { resultSet = statement.executeQuery(sql); } catch (SQLException e) { e.printStackTrace(); } System.out.println(sql+" Cost: "+(System.currentTimeMillis()-time)*1.0/1000+"ms"); JDBCMySQLConnect.close(connection,statement,null,resultSet); }
由于time是由时间和递增序列拼接的,虽然是唯一序列,但是不好确定它的值,进行批量查询。所以仅设置三个语句:
-
like 'XX%':在理论上这个似乎可以使用到索引,实践上看不太出来。该语句适用前缀索引,但是time的前10位非唯一。 -
一个存在数据表中的记录:索引很明显提升了查询速度,不过在创建前缀索引后例外。
-
一个不存在数据表中的记录:索引很明显提升了查询速度。
创建索引前: select * from a_table where time like '2021083115%' Cost: 1.316ms select * from a_table where time = '20210831152405120' Cost: 0.29ms select * from a_table where time = '11111111111111111' Cost: 0.208ms 索引:CREATE INDEX a_time ON a_table (time) select * from a_table where time like '2021083115%' Cost: 1.298ms select * from a_table where time = '20210831152405120' Cost: 0.001ms select * from a_table where time = '11111111111111111' Cost: 0.002ms 唯一索引:alter table a_table drop index a_time;CREATE UNIQUE INDEX a_time ON a_table (time) select * from a_table where time like '2021083115%' Cost: 1.552ms select * from a_table where time = '20210831152405120' Cost: 0.002ms select * from a_table where time = '11111111111111111' Cost: 0.001ms 前缀索引:alter table a_table drop index a_time;CREATE INDEX a_time ON a_table (time(10)) select * from a_table where time like '2021083115%' Cost: 1.214ms select * from a_table where time = '20210831152405120' Cost: 1.814ms select * from a_table where time = '11111111111111111' Cost: 0.001ms
之前有说过,非聚集索引会另外消耗空间构建索引的树结构,并指向原数据表。一般来说非聚集索引是通过保存聚集索引的值(即主键id)来指向原数据表。那么通过非聚集索引来获取主键,只需要遍历非聚集索引空间即可,查询速度会比较快。
不过对like 'XX%'和前缀索引还是有些疑惑。
创建索引前: select id from a_table where time like '2021083115%' Cost: 0.55ms select id from a_table where time = '20210831152405120' Cost: 0.383ms select id from a_table where time = '11111111111111111' Cost: 0.189ms 索引:CREATE INDEX a_time ON a_table (time) select id from a_table where time like '2021083115%' Cost: 0.686ms select id from a_table where time = '20210831152405120' Cost: 0.001ms select id from a_table where time = '11111111111111111' Cost: 0.001ms 前缀索引:alter table a_table drop index a_time;CREATE INDEX a_time ON a_table (time(10)) select id from a_table where time like '2021083115%' Cost: 0.484ms select id from a_table where time = '20210831152405120' Cost: 2.542ms select id from a_table where time = '11111111111111111' Cost: 0.001ms