1、关系型数据库和非关系型数据库
当前数据库分为关系型数据库和非关系型数据库。这部分主要是参考
1.1 关系型数据库
1.1.1 关系型数据库的概念
关系型数据库是指采用了关系模型来组织数据的数据库。关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的练习所组成的一个数据组织。
| 关系模型中常用的概念 | |
|---|---|
| 关系 | 一张二维表,每个关系都具有一个关系名,也就是表名 |
| 元组 | 二维表中的一行,在数据库中被称为记录 |
| 属性 | 二维表中的一列,在数据库中被称为字段 |
| 域 | 属性的取值范围,也就是数据库中某一列的取值限制 |
| 关键字 | 一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成 |
| 关系模式 | 指对关系的描述。其格式为:关系名(属性1,属性2,……,属性N),在数据库中成为表结构 |
1.1.2 关系型数据库存在的优点
-
容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解。
-
使用方便:通用的
SQL语言使得操作关系型数据库非常方便。 -
易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率。
-
支持
SQL,可用于复杂的查询。
1.1.3 关系型数据库存在的问题
-
网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
-
网站每天产生的数据量是巨大的,对于关系型数据库,在一张包含海量数据的表中查询,效率是非常低的。
-
在基于web的结构当中,数据库是最难进行横向拓展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像
web server和app server那样简单的通过添加更多的硬件和服务节点来拓展性能和负载能力。当需要对数据库系统进行升级和拓展时,往往需要停机维护和数据迁移。 -
性能欠佳:在关系型数据库中,导致性能欠佳最主要的原因是多表的关联查询,以及复杂的数据分析类型的复杂
SQL报表查询。为了保证数据库的ACID特性,必须尽量按照其要求的范式进行涉及,关系型数据库中的表都是存储一个格式化的数据结构。
数据库事务必须具备ACID特性,ACID分别是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
数据库的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库。
1.1.4 当前比较主流的关系型数据库
1.2 非关系型数据库
1.2.1 非关系型数据库的概念
非关系型数据库是指非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。
非关系型数据库以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些时间和空间的开销。
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
1.2.2 非关系型数据库的优点
-
无需经过sql层的解析,读写性能很高;
-
基于键值对,数据没有耦合性,容易拓展。
-
存储数据的格式:
nosql的存储格式是key,value形式、文档形式、图片形式等等,而关系型数据库则只支持基础数据类型。
1.2.3 非关系型数据库存在的问题
-
不提供sql支持,学习和使用成本较高
-
无事务处理,附加功能bi和报表等支持也不好。
1.2.4 非关系型数据库的分类
非关系型数据库都是针对某些特定的应用需求出现的,因此,对于该类应用,具有极高的性能。依据结构化方法以及应用场合的不同,主要分为以下几类。
面向高性能并发读写的key-value数据库
key-value数据库的主要特点是具有极高的并发读写性能。
key-value数据库是一种以键值对存储数据的一种数据库,类似于MAP的结构。可以将整个数据库理解为一个大的MAP,每个键都会对应一个唯一的值。
包括:
面向海量数据访问的面向文档数据库
这类数据库的主要特点是在海量的数据中可以快速的查询数据。
文档存储通常使用内部表示法,可以直接在应用程序中处理,主要是JSON。JSON文档也可以作为纯文本存储在键值存储或关系数据库系统中。
包括
面向搜索数据内容的搜索引擎
搜索引擎是专门用于搜索数据内容的NoSQL数据库管理系统。
主要是用于对海量数据进行实时的处理和分析处理,可用于机器学习和数据挖掘。
包括
面向可拓展性的分布式数据库
这类数据库的主要特点是具有很强的可拓展性。
普通的关系型数据库都是以行为单位来存储数据的,擅长以行为单位的读入处理,比如特定条件数据的获取。因此,关系型数据库也被称为面向行的数据库。相反,面向列的数据库是以列为单位来存储数据的,擅长以列为单位读入数据。
这类数据库想解决的问题就是传统数据库在可拓展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化,将数据存储在记录中,能够容纳大量动态列。由于列名和记录键不是固定的,并且由于记录可能有数十亿列,因此可拓展性存储可以看做是二维键值存储。
包括
1.3 事务机制ACID和 CAP理论
事务机制ACID和CAP理论是数据管理与分布式系统的两个重要的概念。
1.3.1 事务机制ACID
事务的定义和实现一直随着数据管理的发展在演进,当计算机越来越强大,它们就能够被用来管理越来越多数据,最终,多个用户可以在一台计算机上共享数据,这就导致了一个问题,当一个用户修改了数据而另外一个还在使用旧数据进行计算过程中,这里就需要一些机制来保证这种情况不会发生。
ACID规则原来是在1970倍Jim Gray定义,ACID事务解决了很多问题,但是仍然需要和性能做平衡协调,事务越强,性能可能越低,安全可靠性和高性能是一对矛盾。
一个事务是指对数据库状态进行改变的一系列操作编程一个单个序列逻辑元操作,数据库一般在启动时会提供事务机制,包括事务启动、停止、取消或回滚。
但是上述事务机制并不真的实现“事务”,一个真正事务应该遵循ACID属性,ACID事务才真正解决事务,包括并发用户访问同一个数据表记录的头疼问题。
ACID的定义为:
-
Atomic原子性:一个事务的所有系列操作步骤被看成是一个动作,所有的步骤要么全部完成要么一个也不会完成,如果事务过程中任何一点失败,将要被改变的数据库记录就不会真正被改变。
-
Consistent一致性:数据库的约束、级联和触发机制Trigger都必须满足事务的一致性。也就是说,通过各种途径包括外键约束等任何写入数据库的数据都是有效的,不能发生表与表之间存在外检约束,但是有数据却违背这种约束性的情况。所有改变数据库数据的动作事务必须完成,没有事务会创建一个无效数据状态,这是不同于CAP理论的一致性"consistency"的。
-
Isolated隔离性:主要用于实现并发控制。隔离能够确保并发执行的事务能够顺序一个接一个执行,通过隔离,一个未完成事务不会影响另外一个未完成事务。
-
Durable持久性:一旦一个事务被提交,它应该持久保存,不会因为和其他操作冲突而取消这个事务。很多人认为这意味着事务是持久在磁盘上,但是规范没有特别定义这点。
1.3.2 CAP理论
CAP理论是分布式系统中进行平衡的理论,它由Eric Brewer发布在2000年。
-
Consistency一致性:同样数据在分布式系统中所有地方都是被复制成相同的。
-
Available可用性:所有在分布式系统活跃的节点都能够处理操作且能响应查询。
-
Partition Tolerant分区容错性:在两个复制系统之间,如果发生了计划之外的网络连接问题,譬如说某节点或者网络分区故障时,有一种容错性涉及来保证仍然能够对外提供满足一致性和可用性的服务。
一般情况下,CAP理论认为你不能同时拥有上述三种,只能同时选择两种,这是一个实践总结。当有网络分区情况下,也就是分布系统中,其基本需求就是支持分布式存储,严格一致性和可用性需要互相取舍。
1.3.3 CAP和ACID一致性区别
ACID一致性是有关数据库规则,如果数据表结构定义一个字段值是唯一的,那么一致性系统将会解决所有操作中导致这个字段值非唯一性的情况,如果带有一个外键的一行记录被删除,那么其外键相关记录也应该被删除,这就是ACID一致性意思。
CAP理论的一致性是保证同样一个数据在所有不同服务器上的拷贝都是相同的,这是一种逻辑保证,而不是物理,因为光速限制,在不同服务器上这种复制是需要时间的,集群通过阻止客户端查看不同节点上还未同步的数据维持逻辑视图。
当跨分布式系统提供ACID时,这两个概念会混淆在一起。
1.4 关系型与非关系型数据库的比较
-
成本:非关系型数据库简单部署,基本都是开源软件,不需要像使用Oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
-
查询速度:非关系型数据库将数据存储于缓存之中,而且不需要经过SQL层的解析,关系型数据库将数据存储在硬盘中,自然查询速度远不及非关系型数据。
-
存储数据的格式:非关系型数据库的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
-
拓展性:关系型数据库有类似join这样的多表查询机制的限制导致拓展很艰难。非关系型数据库基于键值对,数据之间没有耦合性,所以非常容易水平拓展。
-
持久存储:非关系型数据库不适用于持久存储,海量数据的持久存储,还是需要关系型数据库。
-
数据一致性:非关系型数据库一般强调的是数据最终一致性,不像关系型数据库一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据。
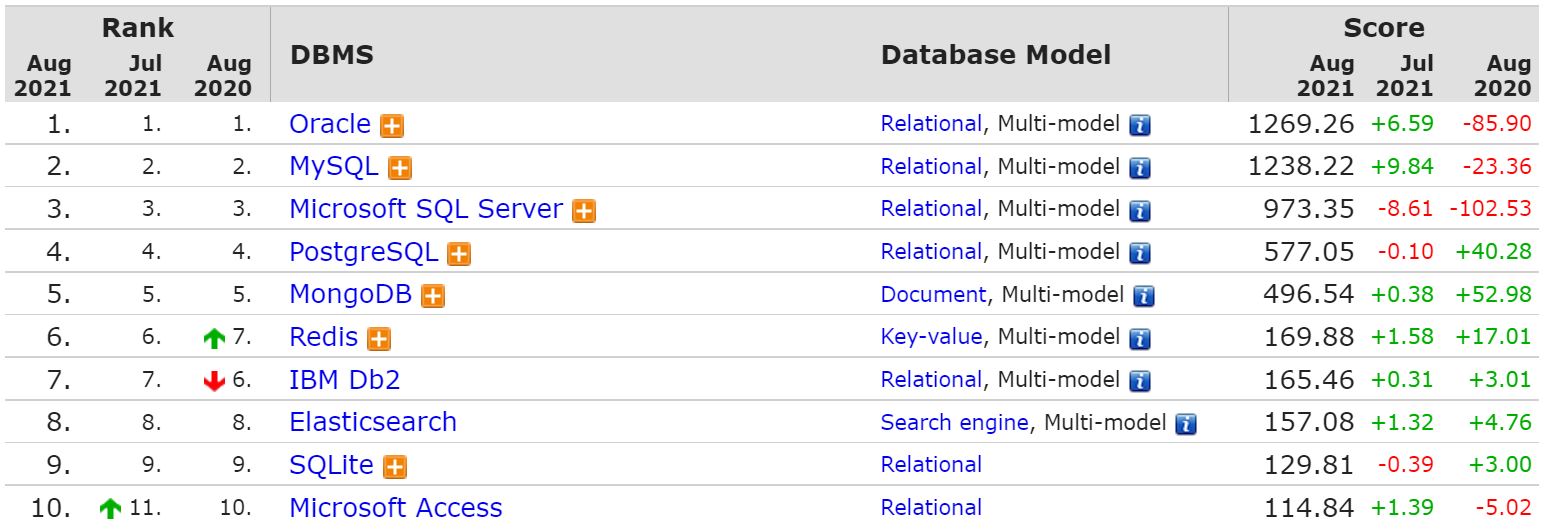
最近的数据库排名:https://db-engines.com/en/ranking
2、经典数据库简单了解
2.1 Oralce
Oracle Database,又名Oracle RDBMS,简称Oracle。Oracle数据库系统是美国Oracle(甲骨文)公司提供的以分布式数据库为核心的一组软件产品,是目前最流行的B/S体系结构的数据库之一。
2.1.1 数据库和实例
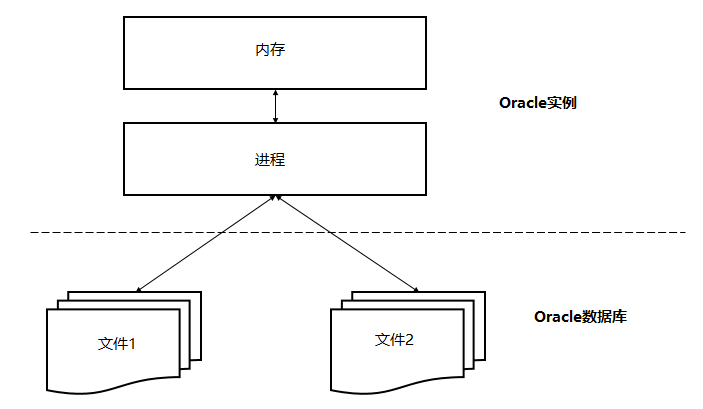
Oracle数据库服务器由一个数据库和至少一个数据库实例组成。数据库是一组存储数据的文件,而数据库实例则是管理数据库文件的内存结构。此外,数据库是由后台进程组成。数据库和实例是紧密相连的,所以一般说的Oralce数据库,通常指的就是实例和数据库。
在这种体系机构中,Oracle数据库服务器包括两个主要部分:文件(Oracle数据库)和内存(Oracle实例)。
2.1.2 Oracle数据库
Oracle数据库的一个基本任务就是存储数据,其主要概念包含Oracle数据库的物理和逻辑存储结构。
物理存储结构是存储数据的纯文件,当执行一个create database语句来创建一个新的数据库时,将创建下列文件:
-
数据文件(dbf):数据文件是数据库的物理存储单位,包含真实数据,逻辑数据库结构(如表和索引)的数据被物理存储在数据文件中。
-
控制文件(ctl):每个Oracle数据库都有一个包含元数据的控制文件。元数据用来描述包括数据库名称和数据文件位置的数据库物理结构。
-
联机重做日志文件(log):每个Oracle数据库都有一个联机重做日志,里面包含两个或者多个联机重做文件。联机重做日志由重做条目组成,能够记录下所有对数据所做的更改。
除这些文件外,Oracle 数据库还包括如参数文件(ora)、网络文件、备份文件以及用于备份和恢复的归档重做日志文件等重要文件。
而Oracle数据库使用逻辑存储结构对磁盘空间使用情况进行精细控制。
-
数据块(Data blocks):Oracle将数据存储在数据块中。数据块也称为逻辑块,Oracle块或页,对应于磁盘上的字节数。
-
范围(Extents):范围是用于存储特定类型信息的逻辑连续数据块的具体数据量。
-
段(Segments):段是分配用于存储用户对象(例如表或索引)的一组范围。
-
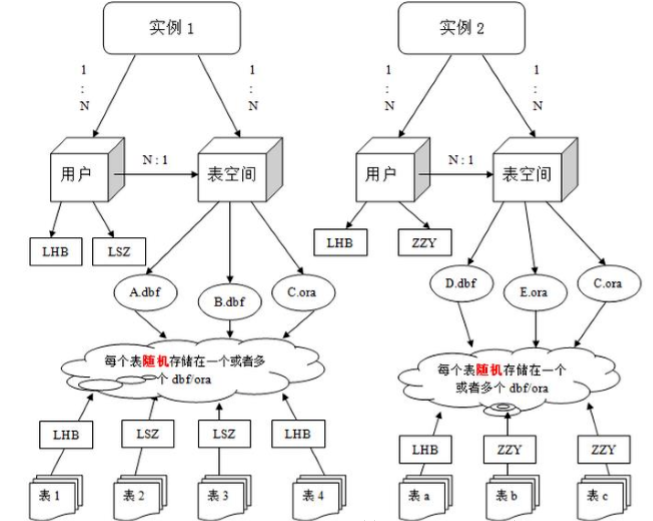
表空间(Tablespaces):表空间是段的逻辑容器,Oracle对物理数据库上相关数据文件(ORA或者DBF文件)的逻辑映射。每个数据库至少有一个表空间(称之为system表空间)。
2.1.3 Oracle实例
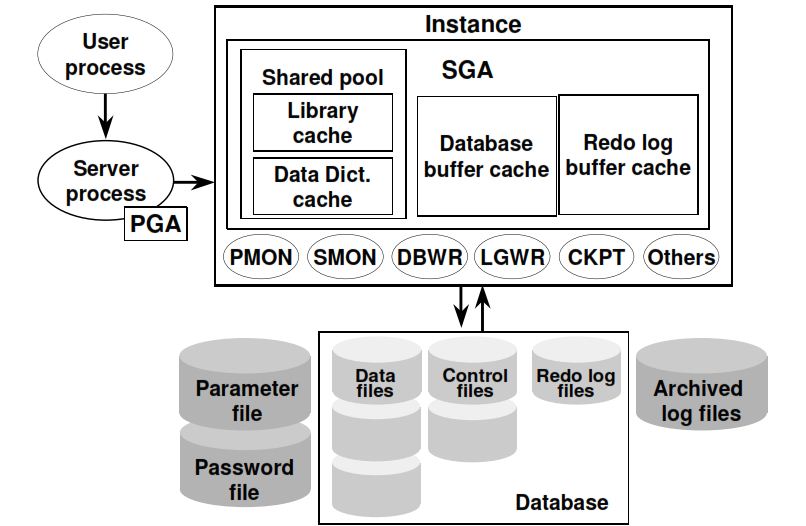
Oracle实例是客户端应用程序(用户)和数据库之间的接口。Oracle实例由三个主要部分组成:系统全局区(SGA),程序全局区(PGA)和后台进程。
更加具体的信息可以看:
2.2 MySQL
MySQL目前属于Oracle公司,是一个免费开源的关系型数据库管理系统,但也不意味着该数据库是完全免费的,其包含两个版本MySQL Community Server(社区版)和MySQL Enterprise Server(企业版),其中企业版是收费且不能下载的,但是企业版拥有官方的电话技术支持。
MySQL适合中小型软件,被个人用户以及中小企业青睐。
MySQL的命名机制如mysql-5.7.20,其中后面三个数字分别为:主版本号,发行级别和此发行系列的版本号。现在,MySQL 5.7是最新开发的稳定(GA)发布系列。
MySQL的特点与优势有如下几点:
-
MySQL是开放源代码的数据库:开源,并不仅仅意味着免费,而且源代码开放,任何人都可以下载其源码进行个性化的优化更改。
-
MySQL的跨平台性:MySQL不仅可以在Windows系列操作系统上运行,还可以在Unix、Linux和Mac OS等操作系统上运行。对比与微软公司的SQL Server数据库来说,这是MySQL的一个很大的优势。
-
价格优势:MySQL数据库是一个自由软件,任何人都可以从MySQL的官方网站上下载该软件。
-
功能强大且使用方便:MySQL是一个真正的多用户、多线程SQL数据库服务器。它能够快速、有效和安全地处理大量的数据。相对于Oracle等数据库来说,MySQL的使用时非常简单的。MySQL主要目标是快速、健壮和易用。
MySQL与常用的驻留数据库Oracle、SQL Server相比,主要特点就是免费,并且在任何平台上都能使用,占用的空间相对较小。但是对于大型项目来说,MySQL的容量和安全性就略逊于Oracle数据库。
更加具体的信息可以看:
2.3 Microsoft SQL Server
对比于Oracle和MySQL,微软公司的SQL Server接触的就更少了。
SQL Server是Microsoft公司推出的关系型数据库管理系统。具有使用方便可伸缩性好与相关软件继承程度高等有点,可跨越从运行Microsoft Windows 98的膝上型电脑到运行Microsoft Windows 2012的大型处理器的服务器等多种平台使用。Microsoft SQL Server是一个全面的数据库平台,使用继承的商业智能(BI)工具提供了企业级的数据管理。Microsoft SQL Server数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使您可以构建和管理用于业务的高可用和高性能的数据库应用程序。
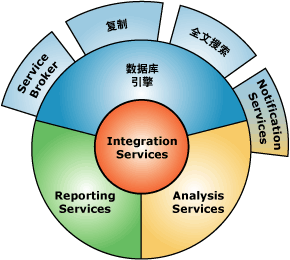
MySQL Server 2005的组件包含:数据库引擎、Reporting Services、Analysis Services、Notification Services、Integration Services、全文搜索、复制、Service Broker。
具体信息在:
2.4 PostgreSQL
PostgreSQL是以加州大学伯克利分校计算机系开发的
PostgreSQL是最初的伯克利代码的开源继承者,它支持大部分SQL标准并且提供了许多现代特性:复杂查询、外键、触发器、可更新视图、事务完整性、多版本并发控制。
同样,PostgreSQL可以用许多方法拓展,比如,通过增加新的:数据类型、函数、操作符、聚集函数、索引方法、过程语言。
而且PostgreSQL是开源的,任何人都可以以任何目的免费试用、修改和分发PostgreSQL,不管是私用、商用还是学术研究目的。
PostgreSQL 10.1 手册 在线手册:
2.5 MongoDB
MongoDB是一个由C++语言编写的基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB旨在为WEB应用提供可拓展的高性能数据存储解决方案。
MongoDB将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB文档类似于JSON对象。字段值可以包含其他文档、数组及文档数组。
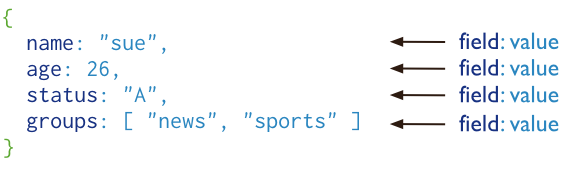
更多:
2.6 Redis
Redis是完全开源的,遵守BSD协议,是一个高性能的key-value数据库。
Redis包含以下特点:
-
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启时可以再次加载使用。
-
Redis不仅仅支持简单的key-value类型的数据,同样还提供list、set、zset、hash等数据结构的存储。
-
Redis支持数据的备份,即master-slave模式的数据备份。
更多:
3、数据库引擎浅谈
数据库引擎时用于存储、处理和保护数据的核心服务。利用数据库引擎可控制访问权限并快速处理事务,从而满足企业内要求极高而且需要处理大量数据的应用需要。
没有找到比较确切的说法,对数据库引擎大概有两种说法:查询引擎和存储引擎。(以下说法可能不够准确,仅仅用于了解一下)。
3.1 SQL 引擎(查询引擎)
参考
SQL引擎的内容涵盖6个开源领导者:Hive、Impala、Spark SQL、Drill、HAWQ以及Presto,还加上Calcite、Kylin、Phoenix、Tajo和Trafodion。以及2个商业化选择Orale Big Data SQL和IBM Big SQL,IBM尚未将后者更名为“Watson SQL”。
但是,这里仅仅了解Hive、Impala、Spark SQL。
3.1.1 背景介绍
不像关系型数据库,SQL引擎独立于数据存储系统。关系型数据库将查询引擎和存储引擎绑定到一个单独的紧耦合系统中,这允许某些类型的优化。而SQL引擎的存在,拆分了它们,提供了更大的灵活性,同时也存在潜在的性能损失。
但是以SQL引擎来作为称呼是有点随意的,比如说,Hive不是一个引擎,它的框架使用MapReduce、TeZ或者Spark引擎去执行查询,而且它并不运行SQL,而是HiveQL,一种类似SQL的语言,非常接近SQL。而统称为"SQL-in-Hadoop"也不适用,虽然Hive和Impala主要使用Hadoop,但是Spark、Drill、HAWQ和Presto还可以和各种其他的数据存储系统配合使用。
Hive、Impala、Spark SQL、Drill、HAWQ以及Presto这几个开源SQL引擎中,虽然Impala、Spark SQL、Drill、HAWQ以及Presto一直在运行性能、并发量和吞吐量上击败Hive,但是Hive仍然是最流行的。
3.1.2 Apache Hive
Apache Hive是Hadoop生态系统中的第一个SQL框架。Facebook的工程师在2007年介绍了Hive,并在2008年将代码捐赠给Apache软件基金会。2010年9月,Hive毕业成为Apache顶级项目。Hadoop生态系统中的每个主要参与者都分布和支持Hive,包括Cloudera、MapR、Hortonworks和IBM。Amazon Web Services在Elastic MapReduce(EMR)中提供了Hive的修改版作为云服务。
早期发布的Hive使用MapReduce运行查询。复杂查询需要多次传递数据,这会降低性能。所以Hive不适合交互式分析。由Hortonworks领导的Stinger明显提高了Hive的性能,尤其是通过使用Apache Tez,衣蛾经典MapReduce代码的应用框架。Tez和ORCfile,一种新的存储格式,对Hive的查询产生了明显的提速。
Cloudera实验室带领了一个并行项目重新设计Hive的后端,使其运行在Apache Spark上。经过长期测试后,Cloudera在2016年初发布了Hive-on-Sprak的正式版本。
在2016年,Hive有100多人的贡献者。该团队在2月份发布了Hive 2.0,并在6月份发布了Hie 2.1。Hive 2.0的改进包括了对Hive-on-Spark的多个改进,以及性能、可用性、可支持性和稳定性增强。Hive 2.1包括了Hive LLAP(Live Long and Process),它结合持久化的查询服务器和优化后的内存缓存,来实现高性能。
2012年,Cloudera推出了Impala,一个开源的MPP SQL引擎,作为Hive的高性能替代品。Impala使用HDFS和HBase,并利用了Hive元数据。但是它绕开了使用MapReduce运行查询。
3.1.4 Spark SQL
Spark SQL是Spark用于结构化数据处理的组件。Apache Spark团队在2014年发布了Spark SQL,并吸收了一个叫Spark的早期的Hive-on-Spark项目,它迅速称为最广泛使用的Spark模块。
Spark SQL用户可以运行SQL查询,从Hive中读取数据,或者使用它来创建Spark Dataset和DataFrame(Dataset是分布式的数据集合,DataFrame是同一命名的Dataset列)。Spark SQL的接口向Spark提供了数据结构和执行操作的信息,Spark的Catalyst优化器使用这些信息来构造一个高效的查询。
3.2 MySQL引擎(存储引擎)
存储引擎是数据库的发动机,决定数据库提供的功能和性能。
在Oracle和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而作为开源数据库,MySQL数据库提供了多种存储引擎。用户可以根据不同的需求选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
相对而言,讨论的比较多的也就是Mysql相关的这些引擎。
3.2.1 show ENGINES
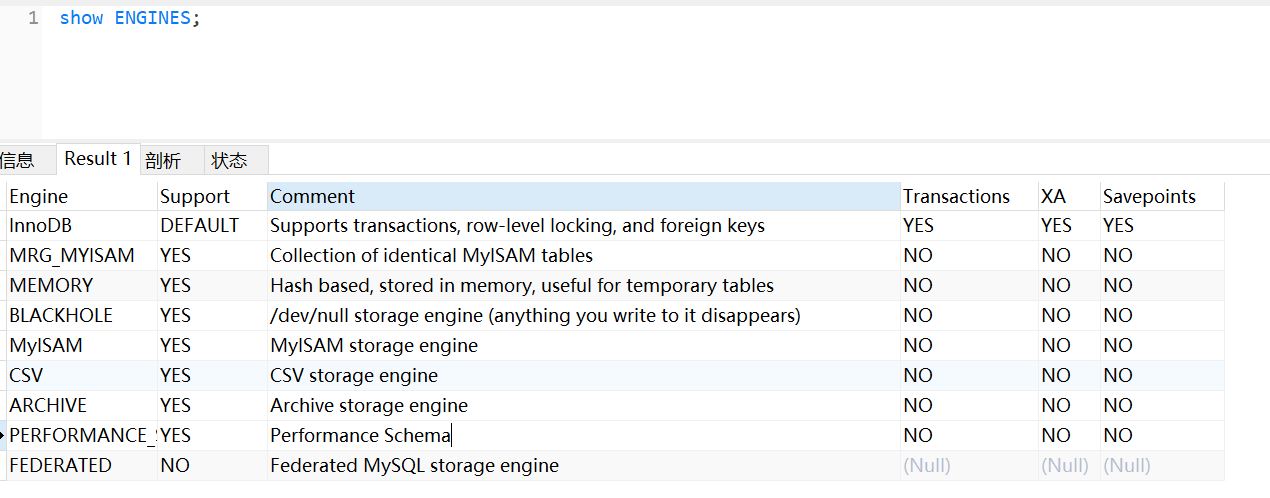
使用show ENGINES 查看MySQL中的引擎,可以看到包含:
-
INNODB:用于事务处理应用程序,具有众多特性,包括ACID事务支持(提供行级锁)。 -
MRG_MYISAM:存储引擎,可用于水平分表。要求关联的子表都是MYISAM类型。 -
MEMORY/HEAP:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。 -
BLACKHOLE:用于临时禁止对数据库的应用程序输入。 -
MYISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。注意:通过更改STORAGE_ENGINE配置变量,能够方便地更改MySQL服务器的默认存储引擎。 -
CSV:引用由逗号隔开的用作数据库表的文件。 -
ARCHIVE:为大量很少引用的历史、归档或安全审计信息的存储和检索提供了完美的解决方案。 -
PERFORMANCE_SCHEMA:用于监控MySQL server在一个较低级别的运行过程中的资源消耗、资源等待等情况。 -
Federated:能够将多个分离的MySQL服务器链接起来,从多个物理服务器创建一个逻辑服务器。十分适合于分布式环境或数据集市环境。
除此之外还有:
-
BDB:可替代INNODB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性。 -
Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合. -
Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性。 -
Example引擎:可为快速创建定制的插件式存储引擎提供帮助。
MySQL数据库引擎取决于MySQL在安装的时候是如何被编译的,要添加一个心的引擎,就必须重新编译MySQL。在缺省情况下,MySQL支持:ISAM、MYISAM和HEAP,以及INNODB、BERKLEY(BDB),还可以使用MySQL+API自己做一个引擎。
3.2.2 ISAM/MYISAM
ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之初就考虑到数据库被查询的次数要远大于更新的次数。因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源,其不足之处在于,它不支持事务处理,也不能够容错。如果你的硬盘崩溃了,那么数据文件就无法恢复了。
MyISAM则是MySQL的ISAM拓展格式和缺省的数据库引擎。除了提供ISAM里所没有的索引和字段管理的大量功能,MyISAM还使用一种表格锁定的机制来优化多个并发的读写操作,其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间。MyISAM还有一些有用的拓展,例如用来修复数据库文件的MyIAMCHK工具和用来恢复浪费空间的MyISAMPACK工具。MyISAM强调了快速读取操作,这可能就是为什么MySQL收到了WEB开发如此青睐的主要原因(在WEB开发中你所进行的大量数据操作都是读取操作)。所以,大多数虚拟主机提供商和INTERNET平台提供商只允许使用MyISAM格式。MyISAM格式的一个重要缺陷就是不能在表损坏后恢复数据。
3.2.3 INNODB
InnoDB数据库引擎都是造就MySQL灵活性技术的直接产品,这项技术就是MYSQL+API。在使用MySQL的时候,你所面对的每一个挑战几乎都源于ISAM和MyISAM数据库引擎不支持事务处理(transaction process),也不支持外来键。尽管要比ISAM和MyISAM引擎慢很多,但是InnoDB包括了对事务处理的外来键的支持,这两点都是前两个引擎所没有的。
3.2.4 MEMORY/HEAP
HEAP允许创建只驻留在内存里的临时表格。驻留在内存里让HEAP比ISAM和MyISAM都快,但是它所管理的数据是不稳定的,而且如果在关机之前没有进行保存,那么所有的数据都会丢失。在数据行被删除的时候,HEAP也不会浪费大量的空间。HEAP表格在你需要使用SELECT表达式来选择和操控数据的时候非常有空。要记住在用完表格之后就删除表格。
3.2.5 存储引擎的选择
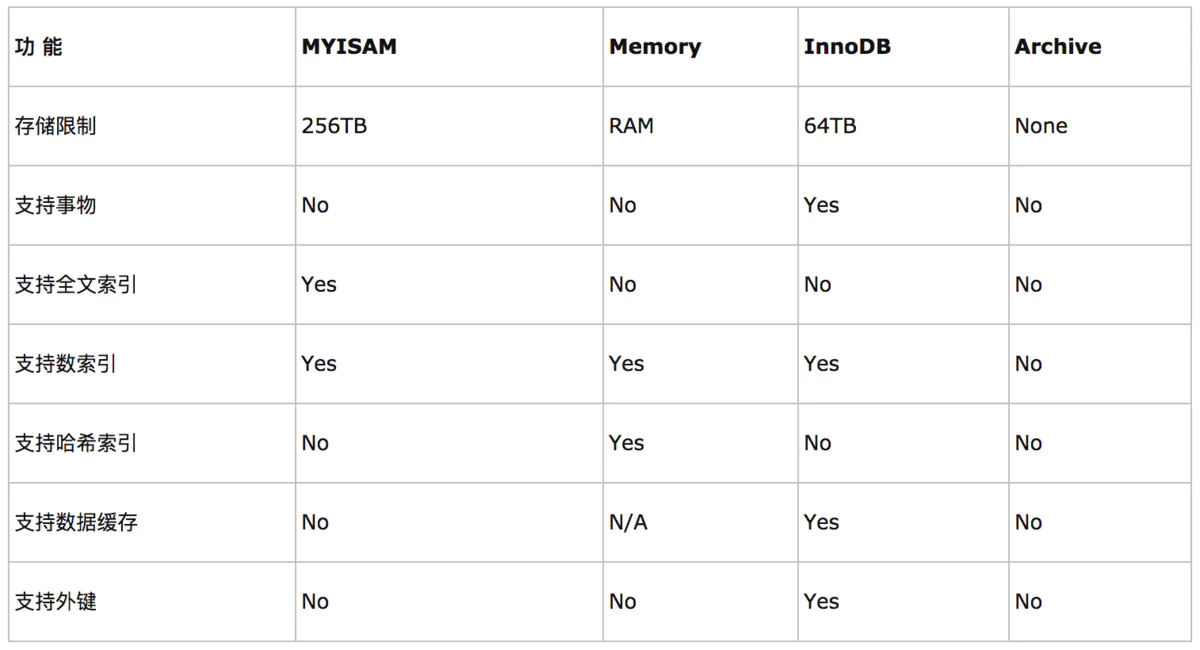
Memory:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求比较低,可以选择Memory。它对表的大小有要求,不能建立太大的表,所以这类数据库只使用在相对较小的数据库表。
MyISAM:插入数据块,空间和内存使用比较低。如果表主要是用于插入新纪录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比较低,也可以使用。
InnoDB:支持事务处理,支持外键,支持奔溃修复能力和并发控制。如果对事务的完整性要求比较高(如银行),要求实现并发控制(如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB。InnoDB是事务型数据库的首选引擎。
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive。
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求
参考