数据库一直在用,甚至有段时间同事间自我调侃就是精通SQL,然而仔细一想,似乎一直也没有用明白,很多操作都是凭经验去做的……到了最后一问还是什么都不懂,那么,什么是索引呢?
先从SQL说起吧,SQL是用于访问和处理数据库的标准的计算机语言,应用于MySQL、SQL Server、Access、Oracle、Sybase、DB2等等经典的关系型数据库。
SQL语言综合统一,集定义语言DDL、数据操纵语言DML、数据控制语言DCL的功能于一体,可以进行数据定义、数据查询和数据更新。
在其数据定义语句包含数据库的、模式、表、视图、索引、同义词等的定义,以下我只列出来别人整理过的部分以及添加一些我感兴趣的知识点:
| 操作对象 | 操作方式 | |||
|---|---|---|---|---|
| 创建 | 删除 | 修改 | ||
| 模式 | CREATE SCHEMA | DROP SCHEMA | ||
| 表 | CREATE TABLE | DROP TABLE | ALTEB TABLE | |
| 视图 | CREATE VIEW | DROP VIEW | ||
| 索引 | CREATE INDEX | DROP INDEX | ALTEB INDEX |
1.1 模式(SCHEMA)
--定义 CREATE SCHEMA <模式名> AUTHORIZATION <用户名> [<表定义子句>|<视图定义子句>|<授权定义子句>]; --删除 DROP SCHEMA <模式名><CASCADE|RESTRICT> /* CASCADE(级联): 表示在删除模式的同时把该模式中所有的数据库对象全部删除 RESTRICT(限制): 表示如果该模式中已定义了下属的数据库对象,则拒绝该删除语句的执行 */
模式(SCHEMA)我接触的比较少,而且去查找资料的时候似乎也比较缺少讨论。在某个博文中的解释是“Create Schema语句是SQL99的一个特性。ORACLE中描述其作用是在你自己的schema内在单个事务里完成多个表和视图的创建以及多个授权(Use the CREATE SCHEMA statement to create multiple tables and views and perform. multiple grants in your own schema in a single transaction.)”。

1.2 基本表(TABLE)
--定义 CREATE TABLE <表名> (<列名><数据类型>[列级完整性约束条件]...[,<表级完整性约束条件>]); --修改 ALTER TABLE <表名> [ADD <新列名> <数据类型> [完整性约束]] [ADD <表级完整性约束>] [DROP [COLUMN] <列名> [CASCADE|RESTRICT]] [DROP CONSTRAINT <完整性约束名> [CASCADE|RESTRICT]] [ALTER COLUMN <列名> <数据类型>]; --删除 DROP TABLE<表名>[CASCADE|RESTRICT];
SQL通用数据类型
| 数据类型 | 描述 |
|---|---|
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
| VARCHAR(n) 或 | 字符/字符串。可变长度。最大长度 n。 |
| CHARACTER VARYING(n) | |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 | 二进制串。可变长度。最大长度 n。 |
| BINARY VARYING(n) | |
| INTEGER(p) | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT(p) | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
不同数据库中SQL数据类型快速参考手册
| 数据类型 | ACCESS | SQLSERVER | ORACLE | MYSQL | POSTGRESQL |
|---|---|---|---|---|---|
| boolean | Yes/No | Bit | Byte | N/A | Boolean |
| integer | Number (integer) | Int | Number | Int Integer | Int Integer |
| float | Number (single) | Float Real | Number | Float | Numeric |
| currency | Currency | Money | N/A | N/A | Money |
| string (fixed) | N/A | Char | Char | Char | Char |
| string (variable) | Text (<256) Memo (65k+) | Varchar | Varchar Varchar2 | Varchar | Varchar |
| binary object | OLE Object Memo | Binary (fixed up to 8K) Varbinary (<8K) Image (<2GB) | Long Raw | Blob Text | Binary Varbinary |
关于数据类型的一些讨论:char(n)、varchar2(n)和varchar2(n char)
首先是关于char(n)、varchar2(n)的对比,char(n)是固定长度的,若是存入字符串长度不够,则会使用空格补上,varchar2(n)的长度则是变化的,按其字符串的实际字节数进行存储,更加节省空间。
不过char(n)的效率比varchar2(n)的效率稍高,有时候想要获得效率,就必须牺牲一定的空间,也就是在数据库设计上常说的“以空间换效率”。
而且,如果一个varchar2(n)列经常被修改,而且每次被修改的数据的长度不同,这会引起“行迁移”(Row Migration)现象,而造成多余的I/O,是数据库设计和调整中要尽力避免的,这种情况下用char来替代会更好。
varchar2(n char)则是限制长度为n个字符,与字节无关。
1.3 视图(VIEW)
--建立 CREATE VIEW <视图名> [(<列名> [,<列名>]...)] AS <子查询> [WITH CHECK OPTION]; /*WITH CHECK OPTION: 表示对视图进行 增删改 操作时要保证更新、插入或删除的行满足视图定义中的谓词条件 */ --删除 DROP VIEW <视图名> [CASCADE] --修改 ALTER VIEW <视图名> AS 查询语句 --查看 DESC <视图名>; 或 SHOW CREATE VIEW <视图名>;
视图是指从一个或几个基本表导出的表,本身不独立存储在数据库中,是一个虚表,但概念上与基本表等同。
其作用包含:简化用户操作;使用户能以多种角度看待同一数据;对重构数据库提供了一定程度的逻辑独立性;能够对机密数据提供安全保护;适当利用视图可更清晰的表达查询。
而视图是否可更新呢?部分视图可更新。视图是不实际存储数据的虚表对视图的更新最终要转换为对基本表的更新。但是不是所有视图都能唯一有意义地转换成对应基本表的更新,只有基本表的行列子集视图可更新。
1.4 索引(INDEX)
--建立 CREATE [UNIQUE][CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>]...); /* UNIQUE: 表明此索引的每一个索引值之对应唯一的数据记录 CLUSTER: 表示要建立的索引是聚簇索引 */ --修改 ALTER INDEX <旧索引名> RENAME TO <新索引名>; --删除 DROP INDEX <索引名>;
2、什么是索引
索引是定义在table基础之上,有助于无需检查所有记录而快速定位所需记录的一种辅助存储结构,由一系列存储在磁盘上的索引项组成,每一种索引项由索引字段和行指针构成。
2.1 索引的好处和坏处
索引的好处:
-
通过创建索引,可以在查询的过程中,提高系统的性能。
-
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-
在使用分组和排序自居进行数据检索时,可以减少查询中分组和排序的时间。
索引的坏处:
-
创建索引和维护索引要耗费时间,而且时间随着数据量的增加而增大。
-
索引需要占用物理空间,如果要建立聚簇索引,所需要的空间会更大。
-
在对表中的数据进行增删改时需要耗费较多的时间,因为索引也要动态地维护。
2.2 索引的类型
然而,单单去查询网络资料,似乎在这一块有些混乱,有一些不同的叫法指向同一个概念,以及在不同数据库中也有不同的说法等等,大佬们各自心里清楚,只有我自己在困扰。
所以会从普通索引、唯一索引、主键索引(主索引)、候选索引、聚簇索引(cluster index,也有翻译为聚集索引)、稠密/稀疏索引、主索引/辅助索引这个几个开始讲讲。
2.2.1普通索引
属于最基本的索引类型,没有唯一性之类的限制。可通过以下三种方法创建。
--创建索引 CREATE INDEX <索引名> ON tablename(字段名1[,字段名2,...]) --修改表添加索引 ALTER TABLE tanlename ADD INDEX [索引名](字段名1[,字段名2,...]) --创建表时指定索引 CREATE TABLE tablename([...],INDEX[索引名](字段名1[,字段名2,...]))
2.2.2 唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。
对某个列建立UNIQUE索引后,插入新纪录时,数据库管理系统会自动检查新纪录在该列上是否取了重复值,在CREATE TABLE命令中的UNIQUE约束将隐式创建UNIQUE索引。
--创建索引 CREATE UNIQUE INDEX <索引名> ON tablename(字段名1[,字段名2,...]) --修改表添加索引 ALTER TABLE tanlename ADD UNIQUE INDEX [索引名](字段名1[,字段名2,...]) --创建表时指定索引 CREATE TABLE tablename([...],UNIQUE INDEX[索引名](字段名1[,字段名2,...]))
或者可以定义为unique key(具体见主键索引部分)。
2.2.3 主键索引(主索引)
表的主键是指数据库表中唯一标识表中每一行的一列或列组合(字段)。
当数据库关系图为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在长训中使用主键索引时,它还允许对数据的快速访问。尽管唯一索引有助于定位信息,但为了获得最佳性能效果,建议改用主键索引。
我们使用primary key来定义主键。
key是数据库的物理结构,它包含两层意义和作用,一是约束(偏重于约束和规范数据库的结构完整性),二是索引(辅助查询用的)。包括primary key,unique key,foreign key(不过在Oracle上建立外键,不会自动建立index)等。
2.2.4 候选索引
与主索引一样要求字段值的唯一性,并决定了处理记录的顺序。在数据库和自由表中,可以为每个表建立多个候选索引。
2.2.5 主索引/辅助索引
主索引:
-
主索引将主文件分块,每一块对应一个索引项。每个存储块的第一条记录又称为锚记录。
-
主索引是按照索引字段值进行排序的一个有序文件,通常建立在有序文件的基于主码的排序字段上。
-
主索引是稀疏索引。
辅助索引:
-
辅助索引的定义是:定义在主文件的任一一个或者多个非排序字段上的辅助存储结构。
-
辅助索引通常对字段(该字段非排序)的每一个不同值有一个索引项。字段值不唯一,引入中间桶保存指针列表。
-
辅助索引是稠密索引。
主索引和辅助索引的区别在于:一个主文件仅有一个主索引,但可以有多个辅助索引;主索引通常建立在主码/排序码上面;可以利用主索引重新组织主文件数据,辅助索引不可以。
2.2.6 稠密/稀疏索引
在前面主索引和辅助索引有提到过稠密索引和稀疏索引,主要区别是存储在磁盘的索引项指向的数据记录结构不同。
稠密索引:每个索引键值都对应有一个索引项,指向一条数据记录。

稀疏索引:相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的搜索码值的索引项,然后从该记录向后顺序查询直到找到为止。
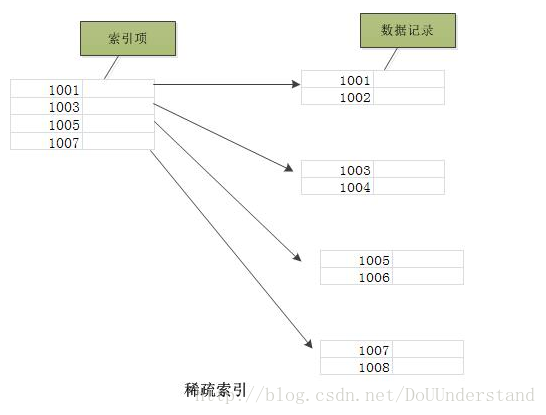
稠密索引能够比稀疏索引更快地定位一条记录。但是,稀疏索引相比于稠密索引的优点是:它所占空间更小,且插入和删除时的维护开销也小。
一个表只能建立一个稠密索引,但是可以有多个稀疏索引。
2.2.7 聚簇索引(聚集索引)/非聚簇索引(非聚集索引)/覆盖索引
SQL SERVER提供了两种索引:聚集索引和非聚集索引。其中聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但随数据更新影响比较大。非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置,非聚集检索效率比聚集索引低,但对数据更新影响比较小。
一个表只能有一个聚集索引,可以有多个非聚集索引。
聚集索引中键值的逻辑顺序决定了表中相应行的物理顺序,所以一个表只能有一个聚集索引。
在mysql中,如果没有设定,聚簇索引默认是主键,如果表中没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。而主键的作用就是把[表]的数据格式转换成[索引(平衡数)]的格式放置。

所以在查询数据的时候能极大地提升其查询性能。
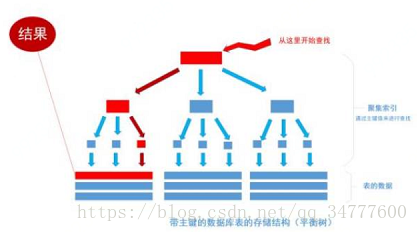
而非聚集索引指的是数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据存储的位置。

非聚集索引和聚集索引的区别在于,通过聚集索引可以查到需要查找的数据,而通过非聚集索引可以查到记录对应的主键值,再使用主键的值通过聚集索引查找到需要的数据。聚集索引是通往真是数据所在的唯一路径。
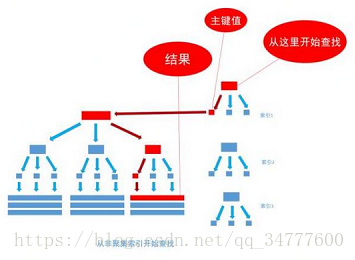
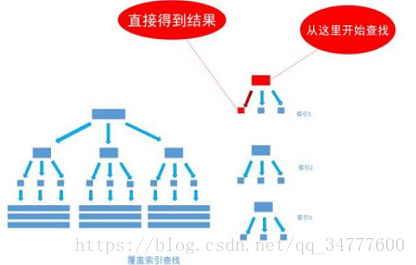
覆盖索引:然而,有一种例外可以不使用聚集索引就能查询出所需要的数据,这种非主流的方法,称之为覆盖索引查询,也即复合索引或者多字段索引查询。
当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
例:我们把birthday字段上的索引写成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为: 通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_info表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。
通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图
2.3 索引的一些要点
2.3.1 key和index的区别
前面有提到过,key是数据库的物理结构,它包含两层意义和作用:一是约束(偏重于约束和规范数据库的结构完整性),二是索引(辅助查询用的)。mysql的key是同时具有constraint和index的意义,这点和其他数据库表现的可能有区别。
index是数据库的物理结构,它只是辅助查询的,它创建时会在另外的表空间(如mysql的innodb表空间)以一个类似目录的结构存储。因此索引只是索引,它不会去约束索引的字段的行为(那是key要做的事情)。索引要分类的话,分为前缀索引、全文本索引等。
2.3.2 主键是否应当作为聚集索引
聚集索引的约束是唯一性,是否要求字段也是惟一的?
之前描述默认情况下主键是表的聚集索引,但是理论上聚集索引可以创建在任何一列你想创建的字段上,但实际上也并不能随便指定,否则在性能上会是噩梦。
那么如果聚集索引并不限于创建在主键上,如果在有重复行的字段上创建是否会违背其唯一性呢?如果未使用UNIQUE属性创建聚集索引,数据库引擎将向表自动添加一个四字节uniqueifier列,使每个键唯一。此列和列值共内部使用,用户不能查看或访问。
同时,虽然默认是在主键上建立聚集索引,但是主键就是聚集索引这是对聚集索引的一种浪费。
一个表只能有一个聚集索引,同时使用聚集索引的最大好处就是能够根据查询要求,迅速缩小查询范围。如果仅仅将聚集索引放在主键,甚至来说自增ID上,对于用户查询并无太大意义,应当按照数据查询要求灵活配置。例如一个获取近30天的邮件记录的系统,将日期设置为聚集索引明显更能提升查询性能。而且,日期列不会因为有分秒的输入而减慢查询速度。
但是到底要不要使用自增主键作为聚集索引还是有着争议的。聚集索引唯一,并且好处也很明显,而自增主键除了作为标识外毫无意义。但是也有人说“在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。”
因为从数据库索引优化角度来看,使用InnoDB引擎而不是用自增主键绝对是一个糟糕的主意。因为聚集索引决定了数据的物理结构,在数据插入的时候,需要维护索引及其物理结构,如果使用自增主键,新纪录插入时可以顺序添加到当前索引节点的后续位置,不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。如果使用其他主键,由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页的中间某个位置,需要移动位置,增加了很多的开销,同时频繁的移动、分页操作造成了大量的碎片。
两个说法,一个出于业务的考虑,一个出于数据库索引优化的角度,只能说具体问题具体分析。
2.3.3 在主键上创建聚集索引的表在数据插入上为什么比主键上创建非聚集索引表速度要慢?
在有主键的表中插入数据行,由于有主键唯一性的约束,所以需要保证插入的数据没有重复。
在主键作为聚集索引情况下查找,由于索引叶节点上已经包含了主键值,所以查找主键的唯一性,需要遍历所有数据节点。
在主键作为非聚集索引时,非聚集索引上已经包含了主键值,所以查找主键唯一性,只需要遍历所有的索引页就行(索引的存储空间比实际数据要少)。
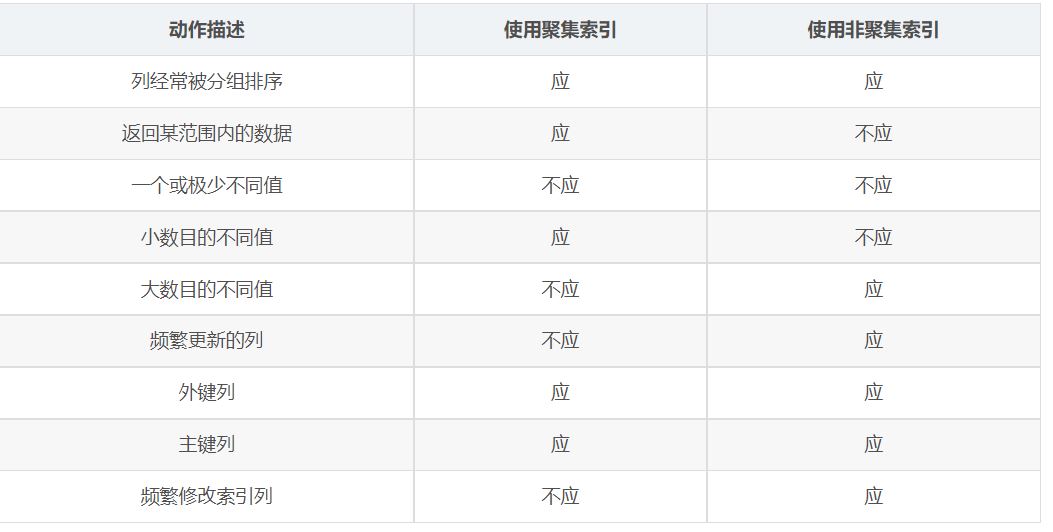
2.3.3 何时应该使用聚集索引和非聚集索引
2.3.4 使用索引的注意事项
建立索引的时机是什么?在where和join中出现的列需要建立索引,但也不完全如此,因为MySQL只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE(以通配符%和_开头作查询时,MYSQL不会使用索引)才会使用索引。
索引不会包含有NULL值的列。只要列中包含有NULL值都将不会被包含在索引中,符合索引中只要有一列含有NULL值,那么这一列对于此符合索引就是无效的。所以我们在数据库涉及时不要让字段的默认值为NULL。
索引列排序。MySQL查询只使用一个索引,一次如果where子句中已经使用了索引的话,那么order by 中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建符合索引。
like语句 操作。一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like "%aaa%"不会使用索引,而like "aaa%"可以使用索引。
-
不要在列上进行运算
-
不使用not in 和<>操作。
3、索引的本质
这部分主要参考
索引是帮助MySQL高效获取数据的数据结构。
数据库查询时数据库的主要功能之一,我们都希望查询数据的速度尽量能地快。从查询算法的角度进行优化,最基本的查询算法是顺序查找(linear search),但是其复杂度为O(n),在数据量很大的时候会表现得很糟糕。所以可以考虑更加优秀的查找算法,例如二分查找(binary search)和二叉树查找(binary tree search),但是这两种算法都只能应用在特定的数据结构之上,二分查找要求被检索的数据有序,二叉树查找只能应用于二叉查找数上,而数据库的数据本身的组织结构不可能完全满足各种数据结构。
所以,在数据库的数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据库的数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构,就是索引。

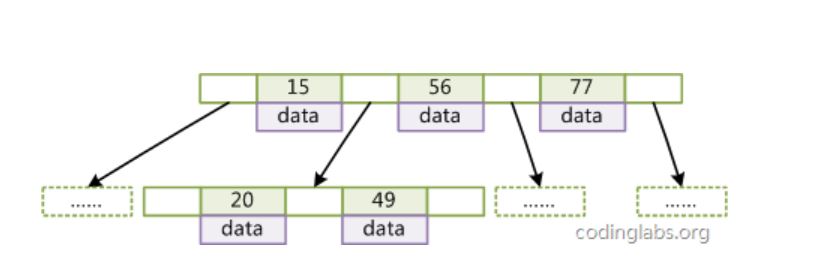
如上图就展示了一种可能的索引方式。右边则是指向左边数据表的一种二叉查找数结构的数据结构,这样就可以运用二叉查找在O(log2n)的复杂度内取到响应的数据。
不过实际的数据库系统几乎没有使用二叉查找数或其进化品种红黑树(red-black tree)实现的,目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
3.1 B树(B-树)
在之前先简单提一下二叉查找数和平衡二叉树、红黑树。简单来说,二叉查找数中要求二叉树每个节点的左节点的值小于当前节点的值,右节点的值大于当前节点的值,就是采用二分法的思维组装成的树形结构。但是二叉查找树可能会出现极端的情况,导致查询效率与顺序查找无异,由此引入平衡二叉树和红黑树的概念。
而B树属于多叉树又名平衡多路查找树。B树有以下几个特点:
-
B树中定义了一个二元组[key,data],key作为排序用的关键字,而data则是其他数据。
-
子节点中关键字是按照递增次序排列的。
-
非叶子节点的子节点数大于1且小于等于M(M>=2,一般称呼为M阶B树)

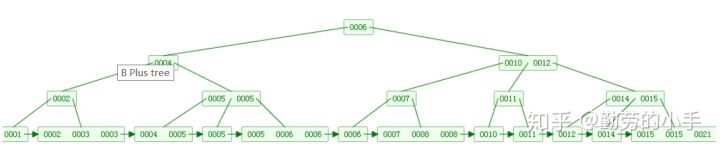
3.2 B+树
B+树是B树的一个变种,相对于B树来说,B+树更充分地利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分查找。
-
B+树跟B树不同,B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加。
-
B+树所有关键字记录的指向数据的指针都保存在叶子节点,所有的数据必须要到叶子节点才能获取,所以每次数据查询的次数都一样。
-
B+树叶子节点的关键字递增排序,左边结尾数据都会保存右边节点开始数据的指针,在叶子节点维持了一个顺序列表,方便范围查询。
-
子节点包含了全部关键字及数据。

B+树作为B-树的变种,两者有以下的几个区别:
-
B+树单一节点存储更多的关键字,使得查询的IO次数更少。
-
B+树的查询都要到达叶子节点查询性能稳定,当然B-树在某些情况下查询速度更快。
-
所有的叶子节点形成有序链表,便于范围查询。
B+树比B-树更适合实现外存储索引结构。
B+Tree、带有顺序访问指针的B+Tree、B*Tree
其实我上面描述的就是带有顺序访问指针的B+树了,我看到不少人直接将其视为B+树。也有人会提及,B+树还存在一叶子节点个不带顺序指针的经典形式,带有顺序访问指针的B+树是经典B+树的变体。“一般在数据库系统或文件系统中使用的B+ Tree结构都在经典B+ Tree的基础上进行了优化,增加了顺序访问指针”。
我曾一度将这两个跟B*树(其非叶子节点末尾也包含指向兄弟节点的指针)搞混。
不过问题不大,这些并不是重点。
3.3 为什么使用B-树和B+树?
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-树和B+树作为索引结构。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘i/O操作次数的渐进复杂度。即,素银的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是内存的几百分分之一,因此为了提高效率,要尽量减少磁盘IO。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理“当一个数据被用到时,其附近的数据也通常会被马上使用。”,程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需要很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整数倍,也是计算机管理存储器的逻辑块。
所以,因为B+树和B-树检索一次最多需要访问h(树高)个节点,所以可以利用磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。
4、总结
似乎想要深入了解索引还是差了些,后面看情况再继续延伸吧
参考