1 基础集群环境准备
1.1修改主机名
root 账户下 vi /etc/sysconfig/network 或者 sudo vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop01
1.2设置系统默认启动级别
root 账号下输入 vi /etc/inittab 将默认的5改为3即可 --最后一行
id:3:initdefault:
1.3配置hadoop用户 sudoer权限
root 账号下,命令终端输入: vi /etc/sudoers
在这一行 root ALL=(ALL) ALL下面添加如下一行:
hadoop ALL=(ALL) ALL
1.4配置IP
具体网上搜索好多种方式
比如命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0 --修改其中内容
1.5关闭防火墙
查看防火墙状态: service iptables status
关闭防火墙: service iptables stop
开启防火墙: service iptables start
重启防火墙: service iptables restart
关闭防火墙开机启动: chkconfig iptables off -----执行这条
开启防火墙开机启动: chkconfig iptables on
1.6添加内网域名映射
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.123.201 hadoop01 192.168.123.202 hadoop02 192.168.123.203 hadoop03 192.168.123.204 hadoop04 192.168.123.205 hadoop05 192.168.123.206 hadoop06 192.168.123.207 hadoop07 192.168.123.208 hadoop08 192.168.123.209 hadoop09 192.168.123.199 hadoop
1.7安装JDK

完以上步骤就开始克隆虚拟机了
二、hadoop集群安装
1、hadoop版本选择
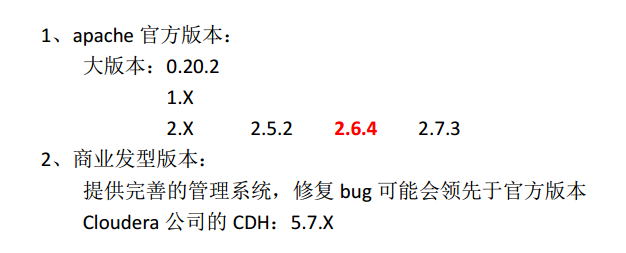
2、同步服务器时间 设置crontab ---这一步最好放在克隆虚拟机前这样克隆后都有了
ntpdate 202.120.2.101 --或者使用这个
ntpdate us.pool.ntp.org --或者使用这个
ntpdate cn.ntp.org.cn --或者使用这个
ntpdate edu.ntp.org.cn --或者使用这个
3、配置免密登录
克隆后需要修改的每台克隆机器的相关配置:
a、vi /etc/udev/rules.d/70-persistent-net.rules --删除eth0的部分,并将eth1部分的NAME改为“eth0”
b、vi /etc/sysconfig/network-scripts/ifcfg-eth0 --删除UUID、HWADDR行删除,修改ip比如hadoop02这台修改为 ...202
c、vi /etc/sysconfig/network --修改主机名
4、hadoop分布式集群安装(伪分布式)
4、hadoop分布式集群安装
总共三个datanode,设置副本数为2,是为了观察数据块分布方便
集群规划:
HDFS YARN
hadoop01 NameNode+DataNode NodeManager
hadoop02 DataNode+SecondaryNameNode NodeManager
hadoop03 DataNode NodeManager+ResourceManager
hadoop01是HDFS的主节点(namenode进程)、hadoop03是Yarn的主节点(ResourceManager进程)
具体安装步骤:


修改环境变量:
vi /home/hadoop/.bash_profile
最后面添加如下两行:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出
然后执行: source .bash_profile


三、集群初步使用
1、hadoop集群启动
DFS 集群启动: sbin/start-dfs.sh
DFS 集群关闭: sbin/stop-dfs.sh
YARN 集群启动: sbin/start-yarn.sh
YARN 集群启动: sbin/stop-yarn.sh
2、HDFS初步使用
查看集群文件: hadoop fs –ls /
上传文件: hadoop fs –put filepath destpath
下载文件: hadoop fs –get destpath
创建文件夹: hadoop fs –mkdir /hadoopdata
查看文件内容: hadoop fs –cat /hadoopdata/mysecret.txt
3、mapreduce 初步使用
