问题描述
PDF格式文件一般分为文字版和图片版:文字版文件较小,方便搜索,可以方便地转换成其他格式;而图片版文件较大,可防止他们直接复制。而今天要说的文字版本却无法搜索,这给文件使用带来了极大的不便。主要表现为:
(1)文件较小,文字可选择;
(2)文字可复制,复制的结果为乱码,如下图的"基础"二字,粘贴的结果是"!"";
(3)无法复制,很急人;
(4)编辑时,格式中的字体是显示"乱码";

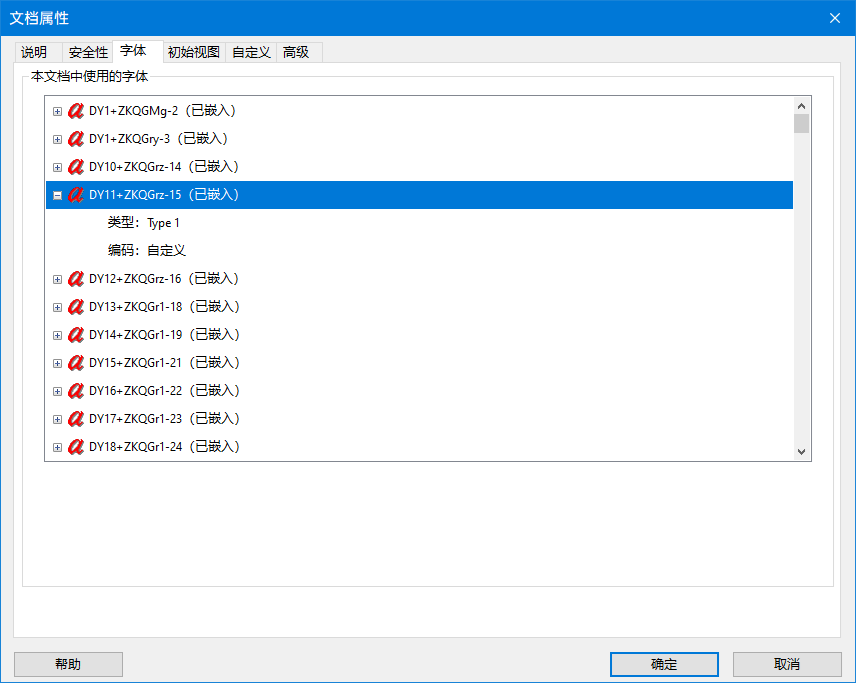
在菜单栏[文档]-[属性]-[字体]中,可以看到有较多已嵌入了自定义编码字体,这是发布者处理的,以防止复制和搜索,一般是一种不可逆的操作。
解决方案
网络上大多的解决方案是使用ABBYY OCR来识别,重新编排一份文档,但这样的效率还是很慢,特别是当文件分辨率并不高的情况下。通过测试发了一种方案。具体操作如下:
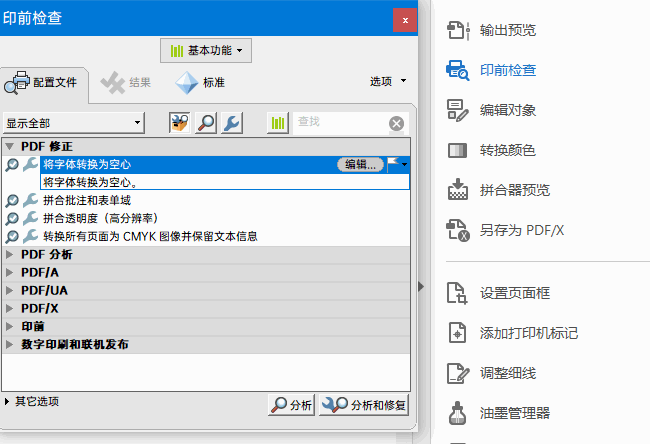
先用Adobe Acrobat打开文件,使用印刷制作工具

打开印前检查进行PDF修正,通过分析和处理,将字体转为空心。
修正后,使用扫描和OCR工具"增强",进行识别处理后,保存即可。这样的操作方法简单,速度较快,结果正确,无需进行核查。
