1.官网下载hadoop安装包
下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
下载后解压到本地文件夹。
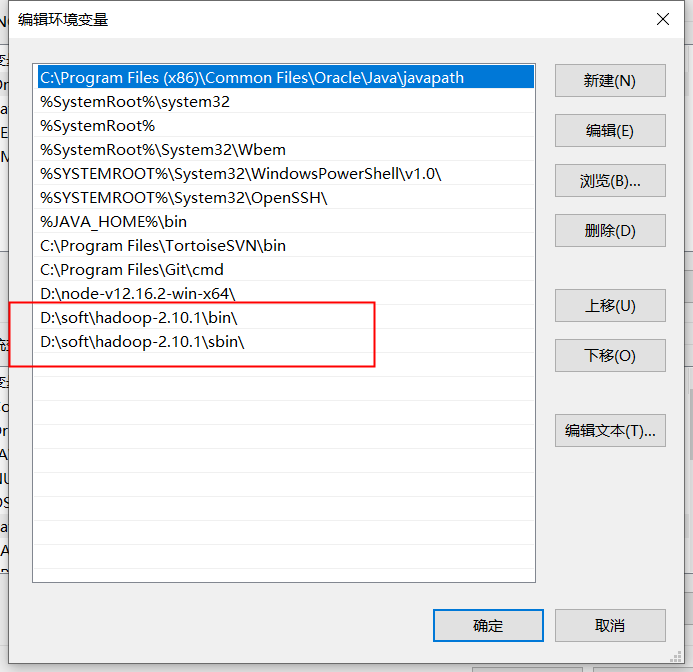
2.配置hadoop环境变量
3.修改配置文件
3.1 hdfs-site.xml文件配置
<configuration>
<!-- 配置 HDFS 的备份文件数量, 默认数量是3, 伪分布式, 配置1就行 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///D://soft//hadoop//hadoop-2.10.1//dfs</value>
</property>
</configuration>

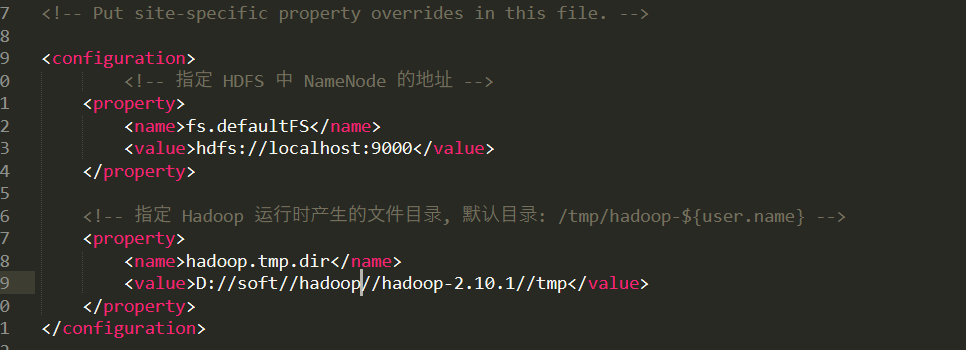
3.2 core-site.xml文件配置
<configuration>
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定 Hadoop 运行时产生的文件目录, 默认目录: /tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>D://soft//hadoop//hadoop-2.10.1//tmp</value>
</property>
</configuration>
4.执行命令 hadoop namenode -format
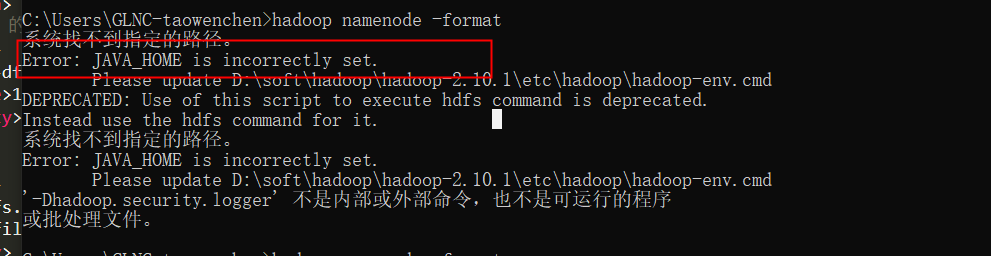
执行后报错--原因已经列出需要设置JAVA-HOME

配置后依旧报错。原因是路径中包含空无法通过。java安装在无空格目录下即可。或者安装在Program Files 的同学可以 配置为
C:PROGRA~1Javajdk1.8.0_261。配置后问题解决。无报错信息即为通过。
5.启动hadoop
执行 start-all 命令。
查看日志 发现启动失败
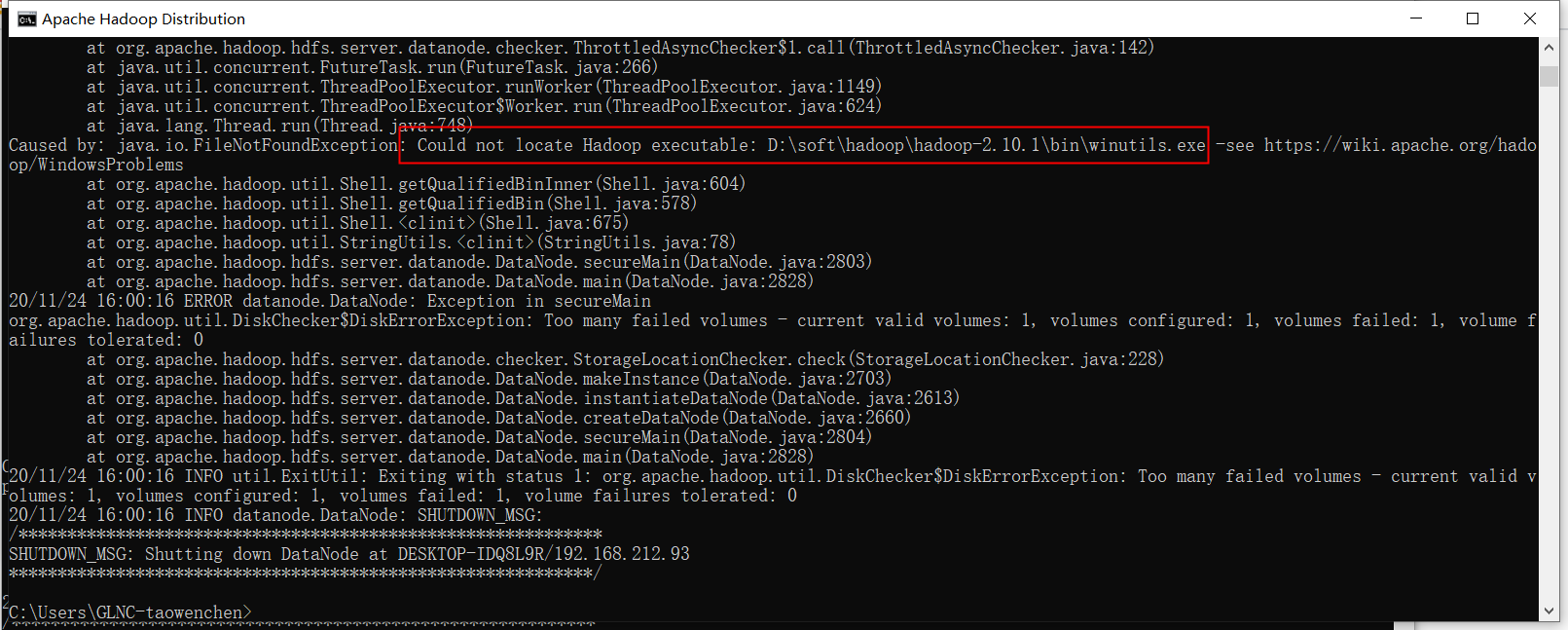
原因是缺少文件。
解决方案 -去github上下载对应文件放在对应目录 。https://github.com/cdarlint/winutils
重新执行start-all后。依旧报错。。。。。
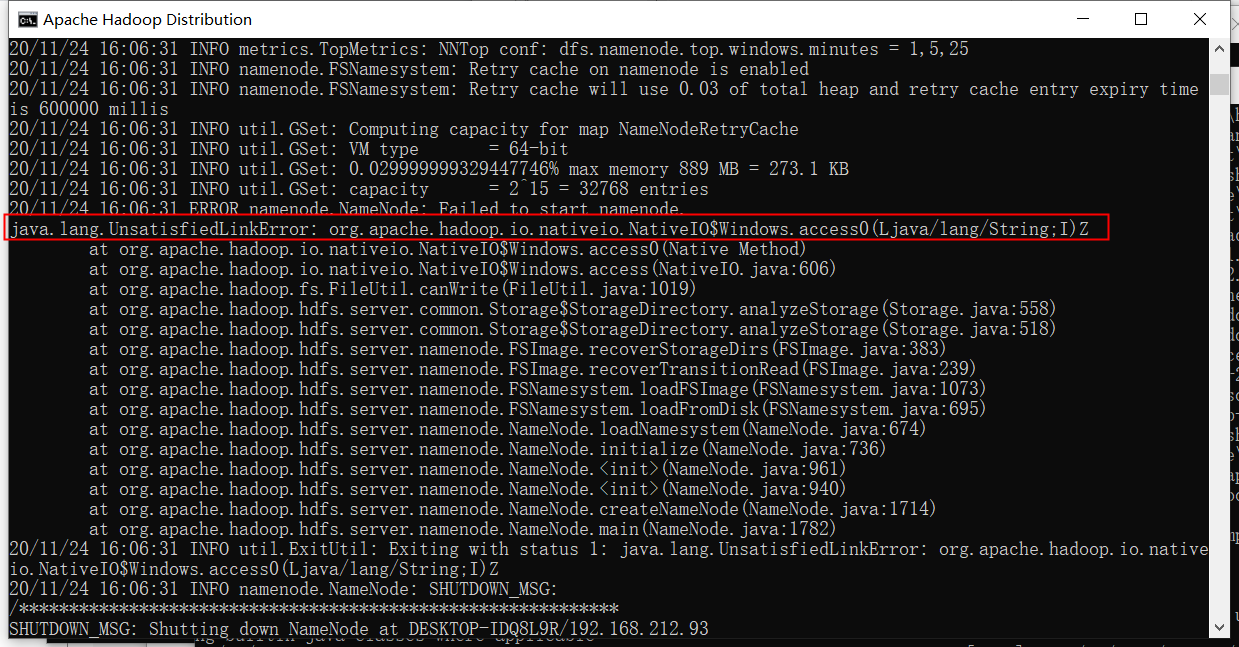
还需要copy hadoop.dll至 bin目录下。如不行 在C://windows/System32 目录也添加文件 hadoop.dll。
启动后 会有四个dos窗口。至此hadoop启动成功。
6.查看web管理页面
http://localhost:50070/ -hdfs页面
http://localhost:8088/ -yarn任务页面
7.执行mapReduce任务。
1. 新建txt文件
2.上传至hdfs
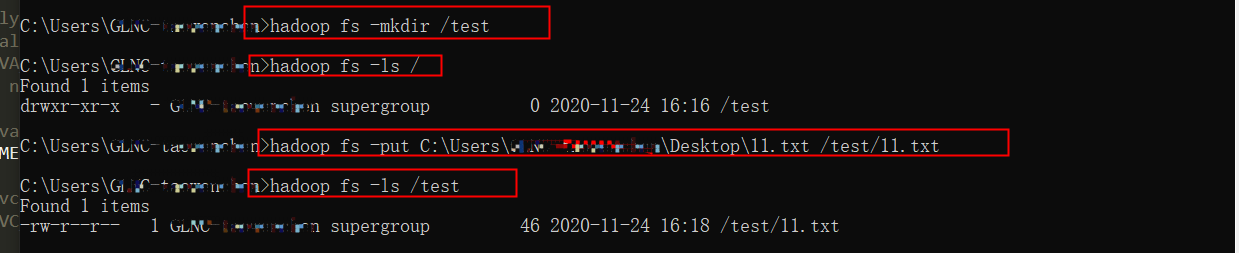
1.建立test目录
hadoop fs -mkdir /test
2. 上传文件
hadoop fs -put C:UsersGLNC-taowenchenDesktop11.txt /test/11.txt
3.执行wordcount
hadoop jar D:softhadoophadoop-2.10.1sharehadoopmapreducehadoop-mapreduce-examples-2.10.1.jar wordcount /test /result
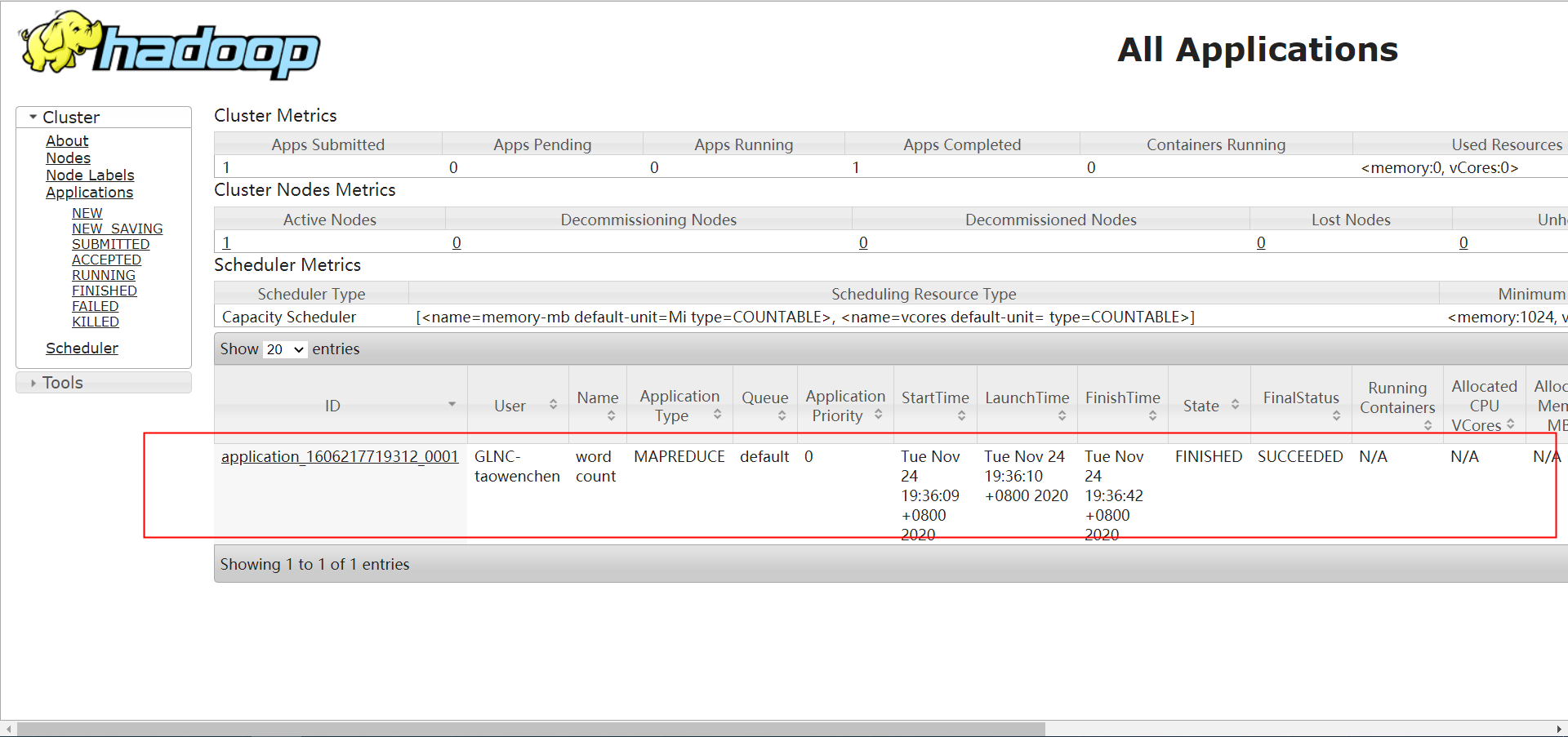
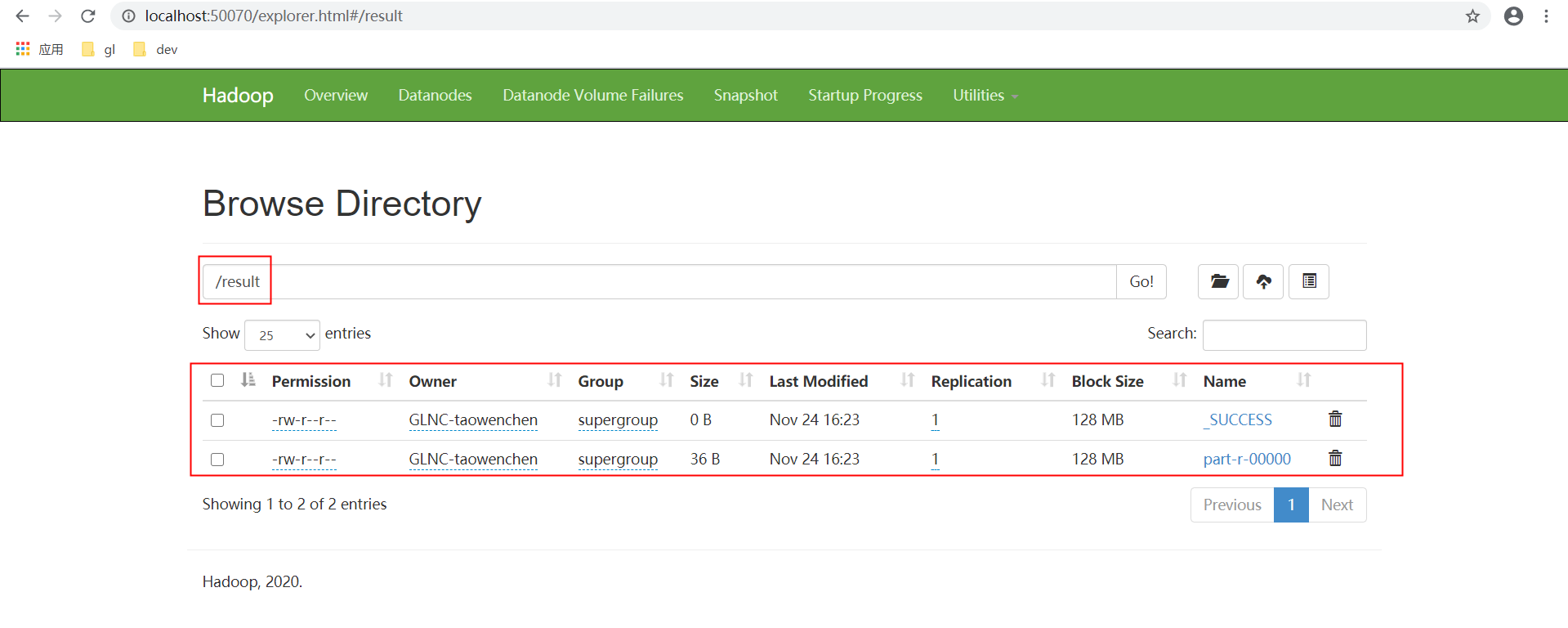
执行成功后 。在web管理页面可以看到已经输出结果文件了
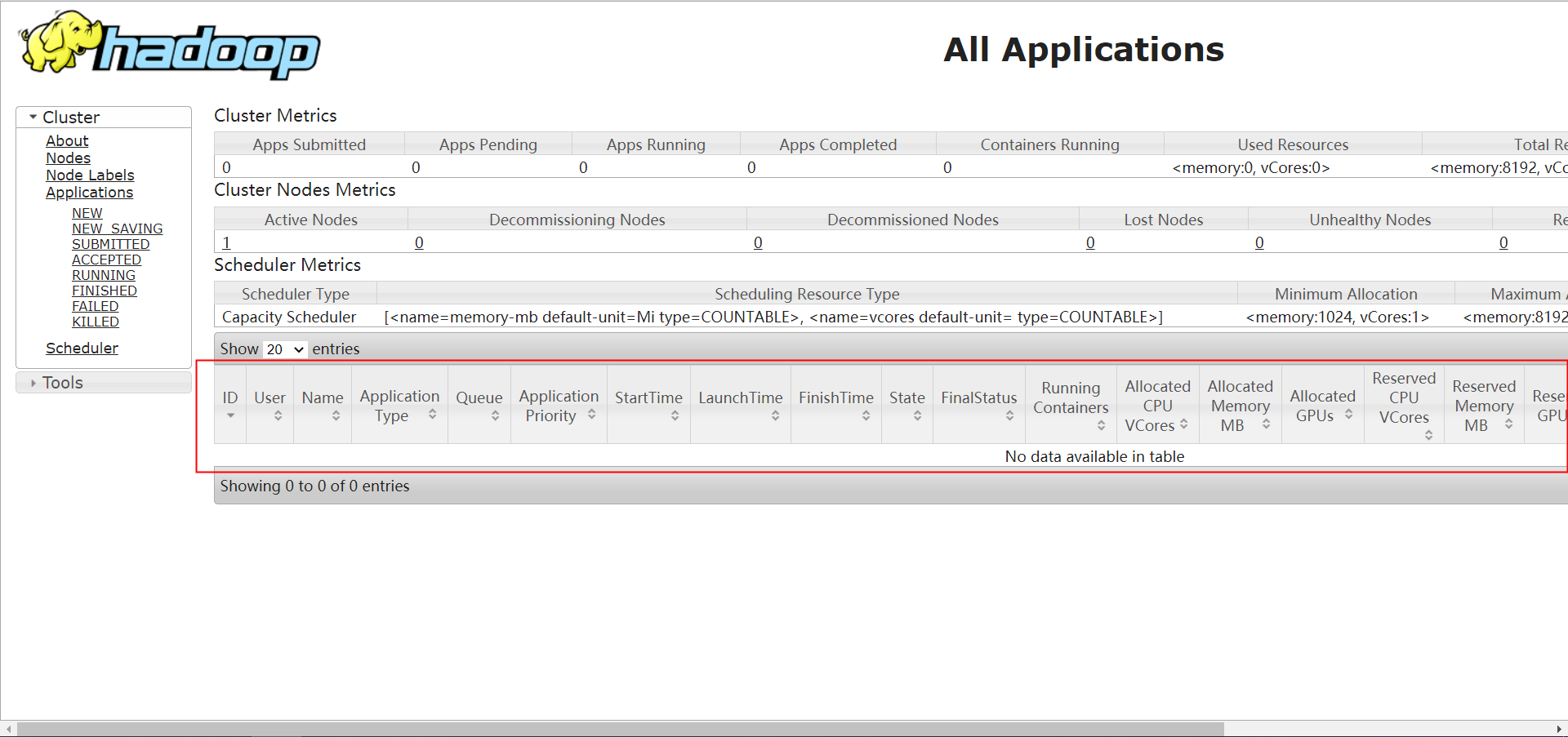
可是在yarn任务管理页面无法查看到任务。
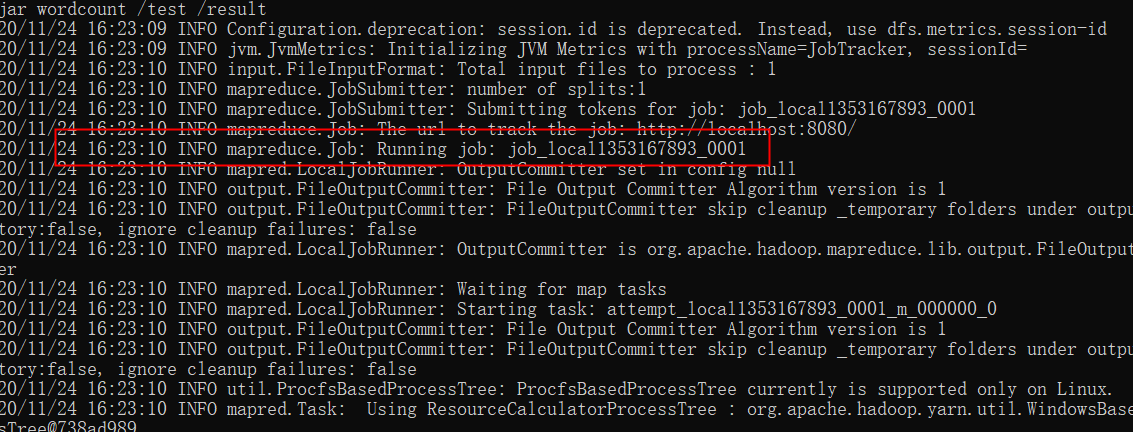
原因是以上job是以本地模式启动的(通过jobId可以区别。jobId中带了local关键字)。在yarn管理页面无法查看。
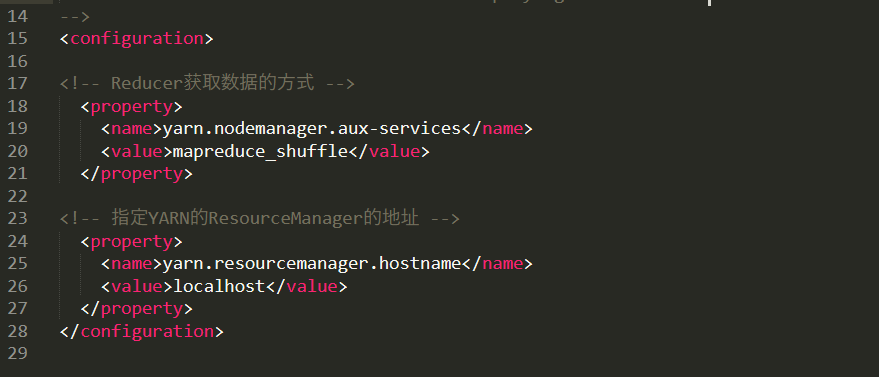
8.继续修改配置,在yarn上运行MapReduce Job。
1.yarn-site.xml配置
<configuration>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
2.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

3.重启hadoop,在执行wordcount MapReduce Job .可以在yarn 管理页面查看任务记录。