-
-
如何学习?
-
一定要把预习加上!
-
分配比例:
-
2/3 总结,
-
文字总结,格式,1/3 晚上8~9之前 完成总结以及代码练习。
-
8~9之后,写作业。
-
-
-
二.昨日内容回顾作业讲解
-
-
生成器:生成器就是迭代器,生成器是自己用python代码构建的。
-
1,生成器函数
-
2,生成器表达式
-
3,python内部提供的。
-
-
如何判断你函数,还是生成器函数?
-
yield
-
yield return
-
-
吃包子。敲三遍。
-
yield from 将一个可迭代对象,变成一个生成器。
-
列表推导式,生成器表达式。
-
循环模式: [变量(加工后的变量) for 变量 in iterable]
-
筛选模式: [变量(加工后的变量) for 变量 in iterable if 条件]
-
-
内置函数?68.
-
三.具体内容
1.

-
此函数不是没有名字,他是有名字的,他的名字就是你给其设置的变量,比如func.
-
lambda 是定义匿名函数的关键字,相当于函数的def.
-
lambda 后面直接加形参,形参加多少都可以,只要用逗号隔开就行。
-
返回值在冒号之后设置,返回值和正常的函数一样,可以是任意数据类型。
-
匿名函数不管多复杂.只能写一行.且逻辑结束后直接返回数据
课上练习:
def func(a,b): return a + b # 构建匿名函数 func1 = lambda a,b: a + b print(func1(1,2))
- 接收一个可切片的数据,返回索引为0与2的对应的元素(元组形式)。
-
xfunc2 = lambda a: (a[0],a[2]) print(func2([22,33,44,55]))
- 写匿名函数:接收两个int参数,将较大的数据返回。
-
lambda a,b: a if a > b else b
2.内置函数
# # python 提供了68个内置函数。 # # 今天讲的这部分大部分了解即可。 # # eval 剥去字符串的外衣运算里面的代码,有返回值。 ** # s1 = '1 + 3' # # print(s1) # # print(eval(s1)) ** # # s = '{"name": "alex"}' # # print(s,type(s)) # # print(dict(s)) # 不行 # # print(eval(s),type(eval(s))) # # 网络传输的str input 输入的时候,sql注入等等绝对不能使用eval。 # # # exec 与eval几乎一样, 代码流。 # msg = """ # for i in range(10): # print(i) # """ # # print(msg) # # exec(msg) # # hash 哈希值 # # print(hash('fsjkdafsda')) # # # help 帮助 ** # # s1 = 'fjdsls' # # print(help(str)) # # print(help(str.upper)) # # s1 = 'sfsda' # # s1.upper() # # # s1 = 'fdsklfa' # # s1() # def func(): # pass # # func # # # callable 判断一个对象是否可被调用 *** # # print(callable(s1)) # # print(callable(func)) # int # print(int(3.6)) # float # print(type(3.6)) # print(complex(1,2)) # (1+2j) # bin:将十进制转换成二进制并返回。 ** # print(bin(100)) # # oct:将十进制转化成八进制字符串并返回。 ** # print(oct(10)) # # hex:将十进制转化成十六进制字符串并返回。 ** # print(hex(10)) # print(hex(13)) # divmod ** # print(divmod(10,3)) # round:保留浮点数的小数位数 ** # print(round(3.141592653, 2)) # 3.14 # pow:求x**y次幂。(三个参数为x**y的结果对z取余) # print(pow(2,3)) ** # print(pow(2,3,3)) # 2**3 % 3 # bytes *** s1 = '太白' # b = s1.encode('utf-8') # print(b) # b = bytes(s1,encoding='utf-8') # print(b) # ord:输入字符找该字符编码的位置 # ascii Unicode # print(ord('a')) # # print(ord('中')) # 20013 Unicode # # chr:输入位置数字找出其对应的字符 # ** # # print(chr(97)) # print(chr(20013)) # Unicode # repr:返回一个对象的string形式(原形毕露)。 *** # s1 = '存龙' # # # print(s1) # # print(repr(s1)) # # msg = '我叫%s' %(s1) # msg = '我叫%r' %(s1) # print(msg) # all:可迭代对象中,全都是True才是True # l1 = [1, 2, '太白', True, [1,2,3], ''] # print(all(l1)) # any:可迭代对象中,有一个True 就是True # l1 = [ 0, '太白', False, [], '',()] # print(any(l1)) # print(self, *args, sep=' ', end=' ', file=None) # print(1,2,3,4) # print(1,2,3,4,sep='&') # print(1, end=' ') # print(2) # list # l1 = [1,2,3,4] # l2 = list() # l2 = list('fjfdsklagjsflag') # print(l2) # dict 创建字典的几种方式 # 直接创建 # 元组的解构 # dic = dict([(1,'one'),(2,'two'),(3,'three')]) # dic = dict(one=1,two=2) # print(dic) # fromkeys # update # 字典的推导式 # abs() *** # print(abs(-6)) # sum *** # l1 = [i for i in range(10)] # s1 = '12345' # print(sum(l1)) # print(sum(l1,100)) # print(sum(s1)) # 错误 # reversed 返回的是一个翻转的迭代器 *** # l1 = [i for i in range(10)] # # l1.reverse() # 列表的方法 # # print(l1) # l1 = [i for i in range(10)] # obj = reversed(l1) # print(l1) # print(list(obj)) # zip 拉链方法 *** # l1 = [1, 2, 3, 4, 5] # tu1 = ('太白', 'b哥', '德刚') # s1 = 'abcd' # obj = zip(l1,tu1,s1) # # # print(obj) # # for i in obj: # # print(i) # print(list(obj)) # ************* 以下方法最最最重要 # min max l1 = [33, 2, 3, 54, 7, -1, -9] # print(min(l1)) # 以绝对值的方式去最小值 # l2 = [] # func = lambda a: abs(a) # for i in l1: # l2.append(func(i)) # print(min(l2)) # def abss(a): # ''' # 第一次:a = 33 以绝对值取最小值 33 # 第二次:a = 2 以绝对值取最小值 2 # 第三次:a = 3 以绝对值取最小值 2 # ...... # 第六次:a = -1 以绝对值取最小值 1 # # ''' # return abs(a) # print(min(l1,key=abss)) # 凡是可以加key的:它会自动的将可迭代对象中的每个元素按照顺序传入key对应的函数中, # 以返回值比较大小。 dic = {'a': 3, 'b': 2, 'c': 1} # 求出值最小的键 # print(min(dic)) # min默认会按照字典的键去比较大小。 # def func(a): # return dic[a] # func = lambda a:dic[a] print(min(dic,key=lambda a: dic[a])) # l2 = [('太白',18), ('alex', 73), ('wusir', 35), ('口天吴', 41)] # print(min(l2)) # print(min(l2,key=lambda x:x[1])) # max pass # sorted 加key # l1 = [22, 33, 1, 2, 8, 7,6,5] # l2 = sorted(l1) # print(l1) # print(l2) # l2 = [('大壮', 76), ('雪飞', 70), ('纳钦', 94), ('张珵', 98), ('b哥',96)] # print(sorted(l2)) # print(sorted(l2,key= lambda x:x[1])) # 返回的是一个列表,默认从低到高 # print(sorted(l2,key= lambda x:x[1],reverse=True)) # 返回的是一个列表,默认从低到高 # filter 列表推导式的筛选模式 # l1 = [2, 3, 4, 1, 6, 7, 8] # print([i for i in l1 if i > 3]) # 返回的是列表 # ret = filter(lambda x: x > 3,l1) # 返回的是迭代器 # print(ret) # print(list(ret)) # map 列表推导式的循环模式 # l1 = [1, 4, 9, 16, 25] # print([i**2 for i in range(1,6)]) # 返回的是列表 # ret = map(lambda x: x**2,range(1,6)) # 返回的是迭代器 # print(ret) # print(list(ret)) # reduce # from functools import reduce # def func(x,y): # ''' # 第一次:x y : 11 2 x + y = 记录: 13 # 第二次:x = 13 y = 3 x + y = 记录: 16 # 第三次 x = 16 y = 4 ....... # ''' # return x + y # # l = reduce(func,[11,2,3,4]) # print(l)
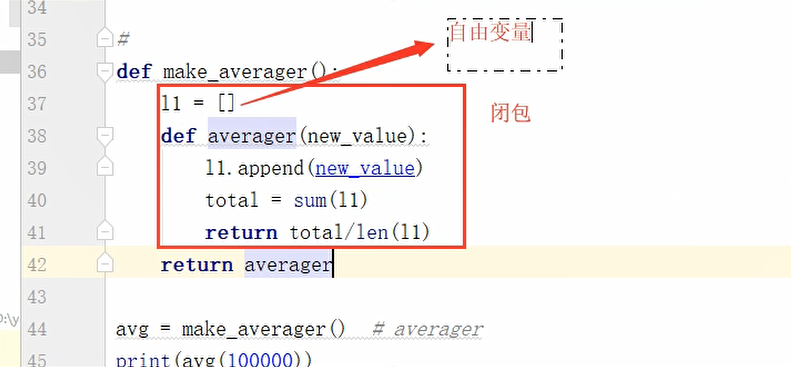
3.闭包:
整个历史中的某个商品的平均收盘价。什么叫平局收盘价呢?就是从这个商品一出现开始,每天记录当天价格,然后计算他的平均值:平均值要考虑直至目前为止所有的价格。
比如大众推出了一款新车:小白轿车。
第一天价格为:100000元,平均收盘价:100000元
第二天价格为:110000元,平均收盘价:(100000 + 110000)/2 元
第三天价格为:120000元,平均收盘价:(100000 + 110000 + 120000)/3 元
# 封闭的东西: 保证数据的安全。 # 方案一: # l1 = [] # 全局变量 数据不安全 # li = [] # def make_averager(new_value): # l1.append(new_value) # total = sum(l1) # averager = total/len(l1) # return averager # print(make_averager(100000)) # print(make_averager(110000)) # # 很多代码..... # l1.append(666) # print(make_averager(120000)) # print(make_averager(90000)) # 方案二: 数据安全,l1不能是全局变量。 # 每次执行的时候,l1列表都会重新赋值成[] # li = [] # def make_averager(new_value): # l1 = [] # l1.append(new_value) # total = sum(l1) # averager = total/len(l1) # return averager # print(make_averager(100000)) # print(make_averager(110000)) # # 很多代码..... # print(make_averager(120000)) # print(make_averager(90000)) # 方案三: 闭包 # def make_averager(): l1 = [] def averager(new_value): l1.append(new_value) print(l1) total = sum(l1) return total/len(l1) return averager # avg = make_averager() # averager # print(avg(100000)) # print(avg(110000)) # print(avg(120000)) # print(avg(190000)) # def func(): # return 666 # # ret = func() # print(globals()) # 闭包: 多用于面试题: 什么是闭包? 闭包有什么作用。 # 1,闭包只能存在嵌套函数中。 # 2, 内层函数对外层函数非全局变量的引用(使用),就会形成闭包。 # 被引用的非全局变量也称作自由变量,这个自由变量会与内层函数产生一个绑定关系, # 自由变量不会在内存中消失。 # 闭包的作用:保证数据的安全。 # 如何判断一个嵌套函数是不是闭包 # 1,闭包只能存在嵌套函数中。 # 2, 内层函数对外层函数非全局变量的引用(使用),就会形成闭包。 # 例一: # def wrapper(): # a = 1 # def inner(): # print(a) # return inner # ret = wrapper() # # # 例二: # a = 2 # def wrapper(): # def inner(): # print(a) # return inner # ret = wrapper() # # 例三: # 也是闭包! # def wrapper(a,b): # def inner(): # print(a) # print(b) # return inner # a = 2 # b = 3 # ret = wrapper(a,b) # print(ret.__code__.co_freevars) # ('a', 'b') # 如何代码判断闭包? def make_averager(): l1 = [] def averager(new_value): l1.append(new_value) print(l1) total = sum(l1) return total/len(l1) return averager avg = make_averager() # averager print(avg.__code__.co_freevars)

四.今日总结
-
-
匿名函数。
-
内置函数。
***一定要记住,敲3遍以上。**尽量记住,2遍。 -
闭包:
闭包: 多用于面试题: 什么是闭包? 闭包有什么作用。
1,闭包只能存在嵌套函数中。
2,内层函数对外层函数非全局变量的引用(使用),就会形成闭包。
被引用的非全局变量也称作自由变量,这个自由变量会与内层函数产生一个绑定关系,
自由变量不会再内存中消失。
闭包的作用:保证数据的安全。
-