目录
第10章 TensorFlow高层封装
目前比较流行的TensorFlow高层封装主要有4个,分别是TensorFlow-Slim、TFLearn、Keras和Estimator。
TensorFlow-Slim是Google官方给出的相对较早的TensorFlow高层封装,Google通过TensorFlow-Slim开源了一些已经训练好的图像分析模型,所以目前在图像识别问题中TensorFlow-Slim仍被较多地使用。
与TesorFlow-Slim相比,TFLearn是一个更加简洁的TensorFlow高层封装。通过TFLearn可以更加容易地完成模型定义、模型训练以及模型评测的全过程。以下给出使用TFLearn在MNIST数据集上实现LeNet-5模型:
import tflearn from tflearn.layers.core import input_data, dropout, fully_connected from tflearn.layers.conv import conv_2d, max_pool_2d from tflearn.layers.estimator import regression import tflearn.datasets.mnist as mnist trainX, trainY, testX, testY = mnist.load_data( data_dir="./MNIST_data", one_hot=True) # 将图像数据resize成卷积卷积神经网络输入的格式。 trainX = trainX.reshape([-1, 28, 28, 1]) testX = testX.reshape([-1, 28, 28, 1]) # 构建神经网络。 net = input_data(shape=[None, 28, 28, 1], name='input') net = conv_2d(net, 32, 5, activation='relu') net = max_pool_2d(net, 2) net = conv_2d(net, 64, 5, activation='relu') net = max_pool_2d(net, 2) net = fully_connected(net, 500, activation='relu') net = fully_connected(net, 10, activation='softmax') # 定义学习任务。指定优化器为sgd,学习率为0.01,损失函数为交叉熵。 net = regression(net, optimizer='sgd', learning_rate=0.01, loss='categorical_crossentropy') # 通过定义的网络结构训练模型,并在指定的验证数据上验证模型的效果。 model = tflearn.DNN(net, tensorboard_verbose=0) model.fit(trainX, trainY, n_epoch=10, validation_set=([testX, testY]), show_metric=True)
运行结果:
Training Step: 8599 | total loss: 0.16579 | time: 29.478s | SGD | epoch: 010 | loss: 0.16579 - acc: 0.9785 -- iter: 54976/55000 Training Step: 8600 | total loss: 0.14981 | time: 31.360s | SGD | epoch: 010 | loss: 0.14981 - acc: 0.9806 | val_loss: 0.04016 - val_acc: 0.9857 -- iter: 55000/55000 --
Keras是目前使用最为广泛的深度学习工具之一,它的底层可以支持TensorFlow、MXNet、CNTK和Theano。Keras API训练模型可以先定义一个Sequential类,然后在Sequential实例中通过add函数添加网络层。Keras把卷积层、池化层、RNN结构(LSTM、GRN)、全连接层等常用的神经网络结构都做了封装,可以很方便地实现深层神经网络。
除了能够还跟方便地处理图像问题,Keras对于循环神经网络的支持也是非常出色。有了Keras API,循环神经网络的循环体结构也可以通过一句命令完成。原生态的Keras API对训练数据的处理流程支持得不太好,基本上需要一次性将数据全部加载到内存;其次,原生态Keras API无法支持分布式训练。为了解决这两个问题,Keras提供了一种与原生态TensorFlow结合得更加紧密得方式,以下代码显示了如何将Keras和原生态TensorFlow API联合起来解决MNIST问题。
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist_data = input_data.read_data_sets('./MNIST_data', one_hot=True) # 通过TensorFlow中的placeholder定义输入。 x = tf.placeholder(tf.float32, shape=(None, 784)) y_ = tf.placeholder(tf.float32, shape=(None, 10)) net = tf.keras.layers.Dense(500, activation='relu')(x) y = tf.keras.layers.Dense(10, activation='softmax')(net) acc_value = tf.reduce_mean( tf.keras.metrics.categorical_accuracy(y_, y)) loss = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_, y)) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss) with tf.Session() as sess: tf.global_variables_initializer().run() for i in range(3000): xs, ys = mnist_data.train.next_batch(100) _, loss_value = sess.run([train_step, loss], feed_dict={x: xs, y_: ys}) if i % 1000 == 0: print("After %d training step(s), loss on training batch is " "%g." % (i, loss_value)) print (acc_value.eval(feed_dict={x: mnist_data.test.images, y_: mnist_data.test.labels}))
运行结果:
Extracting ./MNIST_data/train-images-idx3-ubyte.gz Extracting ./MNIST_data/train-labels-idx1-ubyte.gz Extracting ./MNIST_data/t10k-images-idx3-ubyte.gz Extracting ./MNIST_data/t10k-labels-idx1-ubyte.gz After 0 training step(s), loss on training batch is 2.3884. After 1000 training step(s), loss on training batch is 0.0444334. After 2000 training step(s), loss on training batch is 0.0692529. 0.9781
Estimator是TensorFlow官方提供的高层API,所以它更好地整合了原生态TensorFlow提供的功能。预先定义好的Estimator功能有限,比如无法很好地实现卷积神经网络或者循环神经网络,也没有办法支持自定义的损失函数,所以一般推荐使用Estimator自定义模型。除此之外,Estimator可以原生地支持TensorFlow中数据处理流程的接口。
第11章 TensorBoard可视化
TensorBoard是TensorFlow的可视化工具,它可以通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态。TensorBoard和TensorFlow程序跑在不同的进程中,TensorBoard会自动读取最新的TensorFlow日志文件,并呈现当前TensorFlow程序运行的最新状态。以下代码示例完成TensorFlow日志输出功能:
import tensorflow as tf input1 = tf.constant([1.0, 2.0, 3.0], name="input1") input2 = tf.Variable(tf.random_uniform([3]), name="input2") output = tf.add_n([input1, input2], name="add") writer = tf.summary.FileWriter("./tf_log", tf.get_default_graph()) writer.close()
运行结果:

然后,使用TensorBoard进行可视化,运行以下命令:
tensorboard --logdir=./tf_log
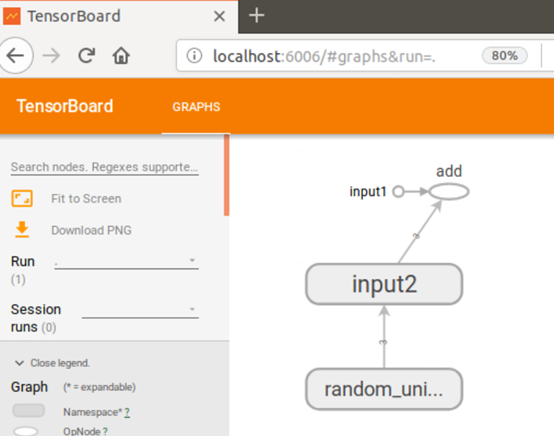
为了更好地组织可视化效果图中的计算节点,TensorBoard支持通过TensorFlow命名空间来整理可视化效果图上的节点。变量的命名空间有tf.variable_scope和tf.name_scope函数。TensorBoard除了展示TensorFlow计算图的结构,还可以展示TensorFlow计算图上每个节点的基本信息以及运行时消耗的时间和空间。
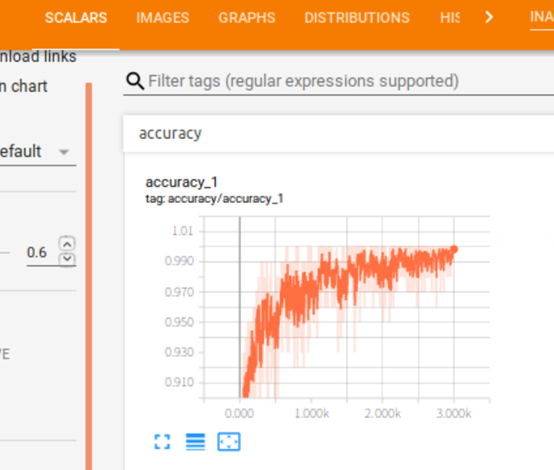
TensorBoard可以依据程序运行的过程对其相关的结果进行可视化,分别有SCALARS、IMAGES、AUDIO、TEXT、HISTOGRAMS和DISRIBUTIONS栏。下图是其中SCALARS栏对MNIST数据集进行训练的可视化结果:
TensorBoard提供了PROJECTOR界面来可视化高维向量之间的关系,PROJECTOR界面可以非常方便地可视化多个高维向量之间的关系。比如在图像迁移学习中可以将一组目标问题的图片通过训练好的卷积层得到瓶颈层,这些瓶颈层向量就是多个高维向量。如果在目标问题图像数据集上同一种类的图片在经过卷积层之后得到的瓶颈层向量在空间中比较接近,那么这样迁移学习得到的记过就有可能会更好。
第12章 TensorFlow计算加速
在配置好GPU环境的TensorFlow中,如果操作没有明确地指定运行设备,那么TensorFlow会优先选择GPU。不同版本的TensorFlow对GPU的支持不一样,如果程序中全部使用强制指定设备的方式会降低程序的可移植性。虽然GPU可以加速TensorFlow的计算,但一般来说不会把所有的操作全部放在GPU上。一个比较好的实践是将计算密集型的运行放在GPU上,而把其他操作放到CPU上。
常用的并行化深度学习模型训练方式有两种,分别是同步模式和异步模式。在并行化地训练深度学习模型时,不同设备(GPU或CPU)可以在不同训练数据上运行这个迭代过程,而不同并行模式的区别在于不同的参数更新方式。
异步模式:在每一轮迭代时,不同设备会读取参数最新的取值,但因为不同设备读取参数取值的时间不一样,所以得到的值也有可能不一样。根据当前参数的取值和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程并独立地更新参数。可以简单地认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。在异步模式下,不同设备之间是完全独立的。
同步模式:在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再同一更新参数。