目录
第1章 深度学习简介
对于许多机器学习问题来说,特征提取不是一件简单的事情。在一些复杂问题上,要通过人工的方式设计有效的特征集合,需要很多的时间和精力,有时甚至需要整个领域数十年的研究投入。
深度学习解决的核心问题之一就是自动地将简单的特征组合成更加复杂的特征。并使用这些组合特征解决问题。深度学习是机器学习的一个分支,它除了可以学习特征和任务之间的关联,还能自动从简单特征中提取更加复杂的特征。
深度学习在很多领域都有非常出色的表现,例如在计算机视觉、语音识别、自然语言处理和人机博弈等。
第2章 TensorFlow环境搭建
TensorFlow主要依赖两个工具包——Protocol Buffer和Bazel。
Protocol Buffer是谷歌开发的处理结构化数据的工具,和XML或者JSON格式的数据有较大的区别。首先Protocol Buffer序列化之后得到的数据不是可读的字符串,而是二进制流。其次,XML或JSON格式的数据信息都包含在了序列化之后的数据中,不需要任何其他信息就能还原序列化之后的数据。但使用Protocol Buffer时需要先定义数据的格式,还原一个序列化之后的数据将需要使用到这个定义好的数据格式。因为这样的差别,Protocol Buffer序列化出来的数据要比XML格式的数据小3到10倍,解析时间快20到100倍。以下是Protocol Buffer格式的一个定义示例:
message user{
optional string name = 1;
required int32 id = 2;
repeated string email = 3;
}
Bazel是从谷歌开源的自动化构建工具,谷歌内部绝大部分的应用都是通过它来编译的。相比传统的Makefile、Ant或者Maven,Bazel在速度、可伸缩性、灵活性以及对不同程序语言和平台的支持上都要更加出色。TensorFlow本身以及谷歌给出的很多官方样例都是通过Bazel来编译的。
第3章 TensorFlow入门
TensorFlow的名字中已经说明了它最重要的两个概念——Tensor和Flow。Tensor就是张量,可以被简单地理解为多维数组。Flow翻译成中文就是“流”,它直观地表达了张量之间通过计算相互转化的过程。TensorFlow是一个通过计算图的形式来表述计算的编程系统,每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。计算图不仅仅可以用来隔离张量和计算,它还提供了管理张量和计算的机制。
在TensorFlow程序中,所有的数据都可以通过张量的形式来表示。从功能的角度来看,张量可以被简单理解为多维数组。其中零阶张量表示标量(scalar),也就是一个数;第一阶张量为向量(vector),也就是一个一维数组;第n阶张量可以理解为一个n维数组。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。例如以下输出结果:
Tensor("add:0", shape=(2,), dtype=float32)
会话拥有并管理TensorFlow程序运行时的所有资源,所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄露问题。以下代码显示其中一个会话使用模式:
with tf.Session() as sess: print(sess.run(result))
TensorFlow游乐场使用链接:http://playground.tensorflow.org
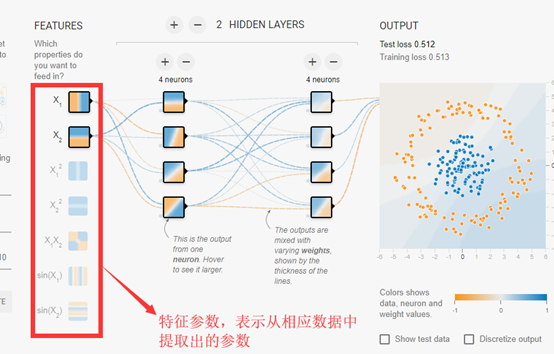
在TensorFlow中,变量(tf.Variable)的作用就是保存和更新神经网络中的参数,和其他编程语言类似,TensorFlow中的变量也需要指定初始值。因为在神经网络中,给参数赋予随机初始值最为常见,所以一般也使用随机数给TensorFlow中的变量初始化。
以下代码给出了一个完整神经网络实现样例,包含一个隐藏层。
import tensorflow as tf from numpy.random import RandomState batch_size = 8 w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input") y_= tf.placeholder(tf.float32, shape=(None, 1), name='y-input') a = tf.matmul(x, w1) y = tf.matmul(a, w2) y = tf.sigmoid(y) cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)) + (1 - y_) * tf.log(tf.clip_by_value(1 - y, 1e-10, 1.0))) train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy) rdm = RandomState(1) X = rdm.rand(128,2) Y = [[int(x1+x2 < 1)] for (x1, x2) in X] with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) # 输出目前(未经训练)的参数取值。 print(sess.run(w1)) print(sess.run(w2)) print(" ") # 训练模型。 STEPS = 5000 for i in range(STEPS): start = (i*batch_size) % 128 end = (i*batch_size) % 128 + batch_size sess.run([train_step, y, y_], feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 1000 == 0: total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y}) print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy)) # 输出训练后的参数取值。 print(" ") print(sess.run(w1)) print(sess.run(w2))
输出结果:
[[-0.8113182 1.4845988 0.06532937] [-2.4427042 0.0992484 0.5912243 ]] [[-0.8113182 ] [ 1.4845988 ] [ 0.06532937]] After 0 training step(s), cross entropy on all data is 1.89805 After 1000 training step(s), cross entropy on all data is 0.655075 After 2000 training step(s), cross entropy on all data is 0.626172 After 3000 training step(s), cross entropy on all data is 0.615096 After 4000 training step(s), cross entropy on all data is 0.610309 [[ 0.02476983 0.56948674 1.6921941 ] [-2.1977348 -0.23668921 1.1143895 ]] [[-0.45544702] [ 0.49110925] [-0.98110336]]
以上程序实现了训练神经网络的全部过程。这段程序可以总结出训练神经网络的过程可以分为以下三个步骤:
(1)定义神经网络的结构和前向传播的输出结果
(2)定义损失函数以及选择反向传播优化的算法
(3)生成会话(tf.Session),并且在训练数据上反复运行反向传播优化算法
无论神经网络的结构如何变化吗,这三个步骤都是不变的。
第4章 深层神经网络
维基百科对深度学习的精度定义为“一类通过多层非线性变换对高复杂性数据建模算法的合集”。因为深层神经网络是实现“多层非线性变换”最常用的一种方法,所以在实际中基本上可以认为深度学习就是深层神经网络的代名词。从维基百科给出的定义可以看出,深度学习有两个非常重要的特性——多层和非线性。
如果在深层神经网络中,前向传播使用线性模型,那么通过线性变换,任意层的全连接神经网络和单层的神经网络并没有区别,而且他们都是线性模型。这就是线性模型最大的局限性,也是为什么深度学习要强调非线性。
分类问题和回归问题是监督学习的两大种类。分类问题希望解决的是将不同的样本分到事先定义好的类别中。交叉熵刻画了两个概率分布之间的距离,它是分类问题中使用比较广泛的一种损失函数。
交叉熵是一个信息论中的概念,它原本是用来估计平均编码长度的。给定两个概率分布p和q,通过q来表示p的交叉熵为:
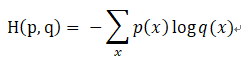
如何将神经网络前向传播得到的结果变成概率分布呢?SOftmax回归是一个非常常用的方法。假设原始的神经网络输出为
,那么经过Softmax回归处理之后的输出为:
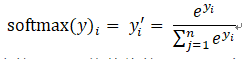
与分类问题不同,回归问题解决的是对具体数值的预测。比如房价预测、销量预测等都是回归问题。对于回归问题,最常用的损失函数是均方误差(MSE,mean squared error)。它的定义如下:
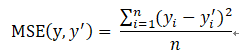
梯度下降算法主要用于优化单个参数的取值,而反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。反向传播算法是训练神经网络的核心算法,它可以根据定义好的损失函数优化神经网络中参数的取值,从而使神经网络模型在训练数据集上的损失函数达到一个较小值。
需要注意的是,梯度下降算法并不能保证被优化的函数达到全局最优解。而且,参数的初始值会很大程度影响最后得到的结果。只有当损失函数为凸函数时,梯度下降算法才能保证达到全局最优解。梯度下降算法另一个问题就是计算时间太长,因为要在全部训练数据上最小化损失,所以损失函数J( )是在所有训练数据上的损失和。
在训练神经网络时,需要设置学习率(learning rate)控制参数更新的速度。如果学习率设置过大,更新的幅度就比那大,那么可能导致参数在极优值的两侧来回移动。如果学习率设置过小,会导致训练的时间变长。为了解决设定学习率的我呢提,TensorFlow提供了一种更加灵活的学习率设置方法——指数衰减法。tf.train.exponential_decay函数实现了指数衰减学习率。以下代码给出了寻找 的最小值,使用梯度下降法来实现:
TRAINING_STEPS = 100 global_step = tf.Variable(0) LEARNING_RATE = tf.train.exponential_decay(0.1, global_step, 1, 0.96, staircase=True) x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x") y = tf.square(x) train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y, global_step=global_step) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(TRAINING_STEPS): sess.run(train_op) if i % 10 == 0: LEARNING_RATE_value = sess.run(LEARNING_RATE) x_value = sess.run(x) print ("After %s iteration(s): x%s is %f, learning rate is %f."% (i+1, i+1, x_value, LEARNING_RATE_value))
运行结果:
After 1 iteration(s): x1 is 4.000000, learning rate is 0.096000. After 11 iteration(s): x11 is 0.690561, learning rate is 0.063824. After 21 iteration(s): x21 is 0.222583, learning rate is 0.042432. After 31 iteration(s): x31 is 0.106405, learning rate is 0.028210. After 41 iteration(s): x41 is 0.065548, learning rate is 0.018755. After 51 iteration(s): x51 is 0.047625, learning rate is 0.012469. After 61 iteration(s): x61 is 0.038558, learning rate is 0.008290. After 71 iteration(s): x71 is 0.033523, learning rate is 0.005511. After 81 iteration(s): x81 is 0.030553, learning rate is 0.003664. After 91 iteration(s): x91 is 0.028727, learning rate is 0.002436.
在真实应用中想要的并不是让模型尽量模拟训练数据的行为,而是希望通过训练出来的模型对未知的数据给出判断。模型在训练数据上的表现并不一定代表了它在未知数据上的表现。过拟合,指的是当一个模型过为复杂之后,它可以很好地”记忆“每一个训练数据中随机噪音的部分而忘记了要去“学习”训练数据中通用的趋势。
为了避免过拟合问题,一个非常常用的方法时正则化(regularization)。正则化的思想就是在损失函数中加入刻画模型复杂程度的指标。常用的刻画模型复杂度的函数R(w)有两种,一种时L1正则化,计算公式是:
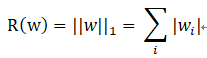
另一种是L2正则化,计算公式是:

无论是哪一种正则化方法,基本的思想都是希望通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪音。但这两种正则化的方法也有很大的区别。首先,L1正则化会让参数变得更稀疏,而L2正则化不会让参数变得稀疏的原因是当参数很小时,例如0.001,这个参数的平方基本上就可以忽略了。
在采用随机梯度下降算法训练神经网络时,使用滑动平均模型在很多应用中都可以在一定程度提高最终模型在测试数据上的表现。在TensorFlow中提供了tf.train.ExponentialMovingAverage来实现滑动平均模型。在初始化ExponentialMovingAverage时,需要提供一个衰减率(decay)。这个衰减率将用于控制模型的更新速度。在实际应用中,decay一般会设置成非常接近1的数(例如0.999或者0.9999)。