1.sed1:
1.工作原理 # 因此不建议对大文件进行操作,日志最好做分割
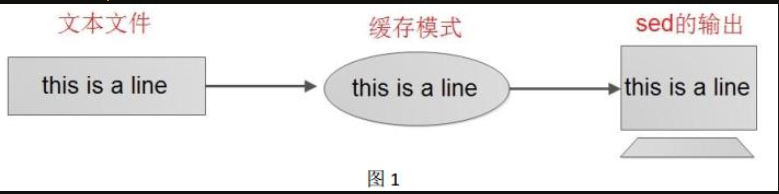
sed 编辑器逐行处理文件(或输入),并将输出结果发送到屏幕。 sed 的命令就是在 vi和 ed/ex 编辑器中见到的那些。 sed 把当前正在处理的行保存在一个临时缓存区中,这个缓存区称为模式空间或临时缓冲。sed 处理完模式空间中的行后(即在该行上执行 sed 命令后),就把改行发送到屏幕上(除非之前有命令删除这一行或取消打印操作)。 sed 每处理完输入文件的最后一行后, sed 便结束运行。 sed 把每一行都存在临时缓存区中,对这个副本进行编辑,所以不会修改或破坏源文件。如图 1: sed 处理过程。
sed 命令行格式为: sed [选项] ‘ command’ 输入文本
2.Sed 定位
Sed 命令在没有给定的位置时,默认会处理所有行;
Sed 支持一下几种地址类型:
1、 first~step
这两个单词的意思: first 指起始匹配行, step 指步长,例如: sed -n 2~5p 含义:从第二行开始匹配,隔 5 行匹配一次,即 2,7,12.......。
2、 $ 这个$符表示匹配最后一行。
3、 /REGEXP/ 这个是表示匹配正则那一行,通过//之间的正则来匹配。
4、 cREGEXPc 这个是表示匹配正则那一行,通过c 和 c 之间的正则来匹配,c 可以是任一字符
5、 addr1, add2
定址 addr1, add2 决定用于对哪些行进行编辑。地址的形式可以是数字、正则表达式或二者的结合。如果没有指定地址, sed 将处理输入文件中的所有行。如果定址是一个数字,则这个数字代表行号,如果是逗号分隔的两个行号,那么需要处理的定址就是两行之间的范围(包括两行在内)。范围可以是数字,正则或二者组合。
6、 addr1, +N
从 addr1 这行到往下 N 行匹配,总共匹配 N+1 行
7、 addr1, ~N
Will match addr1 and the lines following addr1 until the next line whose input line number is a multiple of N.【没有看懂是什么意思】
3.Sed 的正则表达式:
表 1: sed 的正则表达式元字符
| 元字符 |
功 能 |
示 例 |
示例的匹配对象 |
| ^ |
行首定位符 |
/^love/ |
匹配所有以 love 开头的行 |
| $ |
行尾定位符 |
/love$/ |
匹配所有以 love 结尾的行 |
| . |
匹配除换行外的单 个字符 |
/l..e/ |
匹配包含字符 l、后跟两个任意 字符、再跟字母 e 的行 |
| * |
匹配零个或多个前 导字符 |
/*love/ |
匹配在零个或多个空格紧跟着 模式 love 的行 |
| [] |
匹配指定字符组内 任一字符 |
/[Ll]ove/ |
匹配包含 love 和 Love 的行 |
| [^] |
匹配不在指定字符 组内任一字符 |
/[^A-KM-Z]ove/ |
匹配包含 ove,但 ove 之前的那 个字符不在 A 至 K 或 M 至 Z 间 的行 |
| (..) |
保存已匹配的字符 |
|
|
| & |
保存查找串以便在 替换串中引用 |
s/love/&/ |
符号&代表查找串。字符串 love 将替换前后各加了两个的引 用,即 love 变成love** |
| < |
词首定位符 |
/<love/ |
匹配包含以 love 开头的单词的 行 |
| > |
词尾定位符 |
/love>/ |
匹配包含以 love 结尾的单词的 行 |
| x{m} |
连续 m 个 x |
/o{5}/ |
分别匹配出现连续 5 个字母 o、 至少 5 个连续的 o、或 5~10 个 连续的 o 的行 |
| x{m,} |
至少 m 个 x |
/o{5,}/ |
|
| x{m,n} |
至少 m 个 x,但不 超过 n 个 x |
/o{5,10}/ |
|
4.sed的常用选项
表 2.sed 的常用选项
| 选项 |
说明 |
| -n |
使用安静模式,在一般情况所有的 STDIN 都会输出到屏幕上,加入-n 后只打印 被 sed 特殊处理的行 |
| -e |
多重编辑,且命令顺序会影响结果 |
| -f |
指定一个 sed 脚本文件到命令行执行, |
| -r |
Sed 使用扩展正则 |
| -i |
直接修改文档读取的内容,不在屏幕上输出 |
5.Sed 操作命令
sed 操作命令告诉 sed 如何处理由地址指定的各输入行。如果没有指定地址, sed 就会处理输入的所有的行。
表 3.sed 命令
| 命 令 |
说 明 |
| a |
在当前行后添加一行或多行 |
| c |
用新文本修改(替换)当前行中的文本 |
| d |
删除行 |
| i |
在当前行之前插入文本 |
| h |
把模式空间里的内容复制到暂存缓存区 |
| H |
把模式空间里的内容追加到暂存缓存区 |
| g |
取出暂存缓冲区里的内容,将其复制到模式空间,覆盖该处原有内容 |
| G |
取出暂存缓冲区里的内容,将其复制到模式空间,追加在原有内容后面 |
| l |
列出非打印字符 |
| p |
打印当前模式空间所有内容,追加到默认输出之后 |
| P |
打印当前模式空间开端至
的内容,并追加到默认输出之前 |
| n |
读入下一输入行,并从下一条命令而不是第一条命令开始处理 |
| N |
如果有下一行就加入模式空间, 最后一行没有下一行所以就不加入 |
| q |
结束或退出 sed |
| r |
从文件中读取输入行 |
| w |
将文本写入到一个文件 |
| y |
变换字符 sed 'y/s/S/' sed.txt |
| ! |
对所选行意外的所有行应用命令 |
| s |
用一个字符串替换另一个 |
表 4.替换标志
| g |
在行内进行全局替换 |
| p |
打印行 |
| w |
将行写入文件 |
| x |
交换暂存缓冲区与模式空间的内容 |
| y |
将字符转换为另一字符(不能对正则表达式使用 y 命令) |
5.报错信息和退出信息
遇到语法错误时, sed 会向标准错误输出发送一条相当简单的报错信息。但是,如果 sed判断不出错在何处,它会“断章取义”,给出令人迷惑的报错信息。如果没有语法错误, sed将会返回给 shell 一个退出状态,状态为 0 代表成功,为非 0 整数代表失败。
6.案例
下面给出测试文件作为输入文件:
[root@Gin scripts]# cat ceshi.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
# 命令 p 是打印命令,用于显示模式缓存区的内容。默认情况下, sed 把输入行打印在屏幕上,选项-n 用于取消默认打印操纵。当选项-n 和命令 p 同时出现时, sed 可打印选定的内容
[root@localhost backup]# sed '/north/p' ceshi.txt
rthwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@localhost backup]# sed '/north/p' -n ceshi.txt
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
说明:默认情况下, sed 打印当前模式空间中的输入行。命令 p 指示 sed 将再次打印该行。选项-n 取消 sed 取消默认打印操作。选线-n 和命令配合使用,模式缓冲区内的输入行,只被打印一次。如果不指定-n 选项, sed 就会像上例中那样,打印出重复的行。如果指定了-n,则sed 只打印包含模式 north 的行。 # 简单的说其实就是sed有两个缓存区,模式空间和缓存空间,读取所有行到模式空间,在缓存空间存放满足条件的行.如果指定-n则表示只打印缓存空间中匹配到的行,否则表示将模式和空间中与缓存空间一起打印,以重复行显示.
指定行操作:
创建测试环境:
cat >person.txt<<EOF
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
EOF
01 sed命令查询信息方法
根据文件内容的行号进行查询:
测试1: 显示单行信息
[root@oldboyedu ~]# sed -n '3p' person.txt
103,Alex,COO
测试2: 根据行号信息,输出多行内容(连续)
[root@oldboyedu ~]# sed -n '1,3p' person.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
测试3: 根据行号信息,输出多行内容(不连续)
[root@oldboyedu ~]# sed -n '1p;3p' person.txt
101,oldboy,CEO
103,Alex,COO
根据文件内容的信息进行查询:
测试1: 根据内容信息,输出单行内容
#将有oldboy行的信息找出来
[root@oldboyedu ~]# sed -n '/oldboy/p' person.txt
101,oldboy,CEO
测试2: 根据内容信息,输出多行内容(连续)
#将有oldboy到alex行的信息都输出出来
[root@oldboyedu ~]# sed -n '/oldboy/,/Alex/p' person.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
测试3: 根据内容信息,输出多行内容(不连续)
#将有oldboy和alex行的信息都输出出来
[root@oldboyedu ~]# sed -n '/oldboy/p;/Alex/p' person.txt
101,oldboy,CEO
103,Alex,COO
106,oldboy,CIO
删除:d
6.1删除: d 命令
命令 d 用于删除输入行。sed 先将输入行从文件复制到模式缓存区,然后对该行执行 sed命令,最后将模式缓存区的内容显示在屏幕上。如果发出的是命令 d,当前模式缓存区的输入行会被删除,不被显示。
[root@localhost backup]# sed '3d' ceshi.txt
rthwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
删除第 3 行。默认情况下,其余的行都被打印到屏幕上。
删除从第三行到最后一行内容,剩余各行被打印。地址范围是开始第 3 行,结束最后一行。
[root@localhost backup]# sed '3,$d' ceshi.txt
rthwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
替换:s
替换: s 命令
命令 s 是替换命令。替换和取代文件中的文本可以通过 sed 中的 s 来实现, s 后包含在斜杠中的文本是正则表达式,后面跟着的是需要替换的文本。可以通过 g 标志对行进行全局替换
[root@localhost backup]# sed 's/west/north/g' ceshi.txt
rthnorth NW Charles Main 3.0 .98 3 34
northern WE Sharon Gray 5.3 .97 5 23
southnorth SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:s 命令用于替换。命令末端的 g 表示在行内全局替换;也就是说如果每一行里出现多个west,所有的 west 都会被替换为 north。如果没有 g 命令,则只将每一行的第一个west 替换为 north。
[root@localhost backup]# sed -n 's/^west/north/p' ceshi.txt
northern WE Sharon Gray 5.3 .97 5 23
说明:s 命令用于替换。选线-n 与命令行末尾的标志 p 结合,告诉 sed 只打印发生替换的那些行;也就是说,如果只有在行首找到 west 并替换成 north 时才会打印此行。
[root@localhost backup]# sed 's/[0-9][0-9]$/&.5f/g' ceshi.txt
rthwest NW Charles Main 3.0 .98 3 34.5f
western WE Sharon Gray 5.3 .97 5 23.5f
southwest SW Lewis Dalsass 2.7 .8 2 18.5f
southern SO Suan Chin 5.1 .95 4 15.5f
southeast SE Patricia Hemenway 4.0 .7 4 17.5f
eastern EA TB Savage 4.4 .84 5 20.5f
northeast NE AM Main Jr. 5.1 .94 3 13.5f
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13.5f
当“与”符号( &)用在替换串中时,它代表在查找串中匹配到的内容时。这个示例中所有以 2 位数结尾的行后面都被加上.5。
[root@localhost backup]# sed -n 's/Hemenway/Jones/gp' ceshi.txt
southeast SE Patricia Jones 4.0 .7 4 17
说明:文件中出现的所有的 Hemenway 都被替换为 Jones,只有发生变化的行才会打印出来。选项-n 与命令 p 的组合取消了默认的输出。标志 g 的含义是表示在行内全局替换。
[root@localhost backup]# sed 's/(Mar)got/1linanne/p' ceshi.txt
rthwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Marlinanne Weber 4.5 .89 5 9
north NO Marlinanne Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:包含在圆括号里的模式 Mar 作为标签 1 保存在特定的寄存器中。替换串可以通过1 来引用它。则 Margot 被替换为 Marlinane。
[root@Gin scripts]# sed 's#3#88#g' ceshi.txt
northwest NW Charles Main 88.0 .98 88 884
western WE Sharon Gray 5.88 .97 5 288
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 88 188
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 188
说明:紧跟在 s 命令后的字符就是查找串和替换串之间的分隔符。分隔符默认默认为正斜杠,但可以改变。无论什么字符(换行符,反斜线除外),只要紧跟在 s 命令,就成了新的串分隔符。这个方法在查找包含正斜杠模式时很管用,例如查找路径名或生日。
逗号:
指定行的范围:逗号
行的范围从文件中的一个地址开始,在另一个地址结束。地址范围可以是行号(例如5,10),正则表达式(例如/Dick/和/Joe/),或者两者的结合(例如/north/,$)范围是闭合的——包含开始条件的行,结束条件的行,以及两者之间的行。如果结束条件无法满足,就会一直操作到文件结尾。如果结束条件满足,则继续查找满足开始条件的位置,范围重新开始。
[root@Gin scripts]# sed -n '/west/,/east/p' ceshi.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4
说明:打印模式 west 和 east 之间所有的行。如果 west 出现在 east 之后的某一行,则打印的范围从 west 所在行开始,到下一个出现 east 的行或文件的末尾(如果前者未出现)。图中用箭头表示出了该范围。
[root@Gin scripts]# sed -n '5,/northeast/p' ceshi.txt
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
说明:打印从第 5 行开始第一个以 northeast 开头的行之间的所有行。
[root@Gin scripts]# sed '/west/,/east/s/$/**VACA**/' ceshi.txt
northwest NW Charles Main 3.0 .98 3 34**VACA**
western WE Sharon Gray 5.3 .97 5 23**VACA**
southwest SW Lewis Dalsass 2.7 .8 2 18**VACA**
southern SO Suan Chin 5.1 .95 4 15**VACA**
southeast SE Patricia Hemenway 4.0 .7 4 17**VACA**
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:修改从模式 wast 和 east 之间的所有行,将各行的行尾($)替换为字符串**VACA**。换行符被移到新的字符串后面。
编辑 :e
多重编辑: e 命令
-e 命令是编辑命令,用于 sed 执行多个编辑任务的情况下。在下一行开始编辑前,所有的编辑动作将应用到模式缓存区的行上。
[root@Gin scripts]# sed -e '1,3d' -e 's/Hemenway/Jones/' ceshi.txt
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Jones 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:选项-e 用于进行多重编辑。第一重编辑编辑删除第 1~3 行。第二重编辑将Hemenway 替换为 Jones。因为是逐行进行这两行编辑(即这两个命令都在模式空间的当前行上执行),所以编辑命令的顺序会影响结果。例如,如果两条命令都执行的是替换,前一次替换会影响后一次替换。
[root@localhost backup]# sed -e 's/west/Hemenway/' -e 's/Hemenway/Jones/' ceshi.txt
rthJones NW Charles Main 3.0 .98 3 34
Jonesern WE Sharon Gray 5.3 .97 5 23
southJones SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Jones 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
# 第二次的替换实在第一次的基础上做的再次替换
追加:a
a 命令是追加命令,追加将新文本到文件中当前行(即读入模式的缓存区行)的后面。不管是在命令行中,还是在 sed 脚本中, a 命令总是在反斜杠的后面。
[root@Gin scripts]# sed '/^north/a Hello world!' ceshi.txt # 在匹配行后面添加
northwest NW Charles Main 3.0 .98 3 34
Hello world!
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
Hello world!
north NO Margot Weber 4.5 .89 5 9
Hello world!
central CT Ann Stephens 5.7 .94 5 13
在文件最后一行添加信息:
[root@oldboyedu ~]# sed '$a108,oldgirl,UFO' person.txt
100,oldgirl,UFO
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
106,oldboy,CIO
108,oldgirl,UFO
插入:i
i 命令是插入命令,类似于 a 命令,但不是在当前行后增加文本,而是在当前行前面插入新的文本,即刚读入缓存区模式的行。
[root@localhost backup]# sed '/eastern/i Hello,world! #给匹配到的行前面添加
> ----------------------' ceshi.txt
rthwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
Hello,world!
----------------------
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@localhost backup]#
在文件第一行添加信息:
100,oldgirl,UFO
[root@oldboyedu ~]# sed '1i100,oldgirl,UFO' person.txt
100,oldgirl,UFO
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
106,oldboy,CIO
说明:命令 i 是插入命令。如果在某一行匹配到模式 eastern,i 命令就在该行的上方插入命令中插入反斜杠后面后的文本。除了最后一行,
修改: c
c 命令是修改命令。 sed 使用该命令将已有的文本修改成新的文本。旧文本被覆盖。
[root@Gin scripts]# sed '/eastern/c Hello,world!
> ------------------' ceshi.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
Hello,world!
------------------
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:c 命令是修改命令。该命令将完整地修改在模式缓冲区行的当前行。如果模式 eastern被匹配, c 命令将其后的文本替换包含 eastern 的行。
获取下一行: n 命令
n 命令表示下一条命令。 sed 使用该命令获取输入文件的下一行,并将其读入到模式缓冲区中,任何 sed 命令都将应用到匹配行,紧接着的下一行上。
[root@localhost /backup]# sed '/eastern/{n;s/AM/Archie/p}' ceshi.txt #可以将{}去掉
rthwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE Archie Main Jr. 5.1 .94 3 13 # 这一行和下面的一行重复显示了
northeast NE Archie Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:如果在某一行匹配到模式 eastern, n 命令就指示 sed 用下一个输入行(即包含 AM MainJr 的那行)替换模式空间中的当前行,并用 Archie 替换 AM,然后打印该行,再继续往下处理
转换: y,命令
y 命令表示转换。该命令与 tr 命令相似,字符按照一对一的方式从左到右进行转换。例如 y/abc/ABC/,会把小写字母转换成大写字母, a-->A,b-->B,c-->C。
sed '1,3y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/' ceshi.txt
NORTHWEST NW CHARLES MAIN 3.0 .98 3 34
WESTERN WE SHARON GRAY 5.3 .97 5 23
SOUTHWEST SW LEWIS DALSASS 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
说明:y 命令把 1~3 行中所有的小写命令字母都转换成了大写。正则表达式元字符对 y 命令不起作用。与替分隔符一样,斜杠可以被替换成其他字符。
退出: q 命令
q 命令表示退出命令。该命令将导致 sed 程序退出,且不再进行其他的处理。
[root@Gin scripts]# sed '5q' ceshi.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
说明:打印完第 5 行之后, q 让 sed 程序退出。
# 当只需要替换某一行的时候
[root@Gin scripts]# sed '/Lewis/{ s/Lewis/Joseph/;q; }' ceshi.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Joseph Dalsass 2.7 .8 2 18
说明:在某行匹配到模式 Lewis 时, s 表示先用 Joseph 替换 Lewis,然后 q 命令让 sed 退出。
[root@test /backup]# sed '/today/{N;s/on/onto/p}' sed.txt
1today is nice day
2you can walk out onto the street
1today is nice day
2you can walk out onto the street
3it will be import to you
2.sed案例:
1.在实际生产中,在修改配置文件的时候,有一些空格、空行、带“ #”开头的注释都要删除或替换,下面为大家介绍几个实用的例子
[root@localhost /backup]# cat sed.txt
today is nice day # 首行有空格
you can walk out on the street
it will be import to you
[root@localhost /backup]# sed 's/^[ ]//' sed.txt
today is nice day
you can walk out on the street
it will be import to you
## 注:[ ]里面有个空格
或者:
[root@Gin scripts]# sed 's/^[[:space:]]*//' sed.txt
today is nice day
you can walk out on the street
it will be import to you
2.删除文本中空行和空格组成的行及#号注释的行
[root@localhost /backup]# grep -Ev "^#|^$" /etc/ssh/ssh_config
Host *
GSSAPIAuthentication yes
ForwardX11Trusted yes
SendEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES
SendEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT
SendEnv LC_IDENTIFICATION LC_ALL LANGUAGE
SendEnv XMODIFIERS
3.从 Google 上下载下来的配置文件往往都带有数字,现在需要删除所有行的首数字。
[root@Gin scripts]# cat sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
[root@Gin scripts]# sed 's/^[0-9][0-9]*//g' sed.txt
today is nice day
you can walk out on the street
it will be import to you
4.例子:从aaa文件中取出偶数行
[root@localhost ~]# cat a.txt
This is 1
This is 2
This is 3
This is 4
This is 5
[root@localhost ~]# sed –n ‘n;p’ a.txt
This is 2
This is 4
注释:读取This is 1,执行n命令,此时模式空间为This is 2,执行p,打印模式空间内容This is 2,之后读取This is 3,执行n命令,此时模式空间为This is 4,执行p,打印模式空间内容This is 4,之后读取This is 5,执行n命令,因为没有了,所以退出,并放弃p命令。因此,最终打印出来的就是偶数行。
5.例子:从aaa文件中读取奇数行
[root@localhost ~]# sed –n ‘N;P’ a.txt -----因为读取第5行时,执行N,发现没有第6行,不满足,就退出,放弃P命令
This is 1
This is 3
[root@localhost ~]# sed –n ‘$!N;P’ a.txt
This is 1
This is 3
This is 5
注释中1代表This is 1 2代表This is 2 以此类推
注释:读取1,$!条件满足(不是尾行),执行N命令,得出1
2,执行P,打印得1,读取3,$!条件满足(不是尾行),执行N命令,得出3
4,执行P,打印得3,读取5,$!条件不满足,跳过N,执行P,打印得5
3.sed高级用法
1.简介
sed之所以能以行为单位的编辑或修改文本,其原因在于它使用了两个空间:一个是活动的“模式空间(pattern space)”,另一个是起辅助作用的“保持空间(hold space)这2个空间的使用。
模式空间:可以想成工程里面的流水线,数据之间在它上面进行处理。
保持空间:可以想象成仓库,我们在进行数据处理的时候,作为数据的暂存区域。
正常情况下,如果不显示使用某些高级命令,保持空间不会使用到!
sed在正常情况下,将处理的行读入模式空间,脚本中的“sed command(sed命令)”就一条接着一条进行处理,直到脚本执行完毕。然后该行被输出,模式被清空;接着,在重复执行刚才的动作,文件中的新的一行被读入,直到文件处理完毕。

一般情况下,数据的处理只使用模式空间(pattern space),按照如上的逻辑即可完成主要任务。但是某些时候,通过使用保持空间(hold space),还可以带来意想不到的效果。
sed命令:
+ g:[address[,address]]g 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除。
+ G:[address[,address]]G 将hold space中的内容追加到pattern space
后。
+ h:[address[,address]]h 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除。
+ H:[address[,address]]H 将pattern space中的内容追加到hold space
后。
+ d:[address[,address]]d 删除pattern中的所有行,并读入下一新行到pattern中。
+ D:[address[,address]]D 删除multiline pattern中的第一行,不读入下一行。
+ x:交换保持空间和模式空间的内容。
1. 给每行结尾添加一行空行
[root@test /backup]# cat sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
# 给每一行的后面加上空行
[root@test /backup]# sed 'G' sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
# 除了第一行其他行加上空行
[root@test /backup]# sed '1!G' sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
# 匹配行后面加上空行
[root@test /backup]# sed '/today/G' sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
# 除了第一行之外的行加上空行,并删除除了最后一行的内容
[root@test /backup]# sed '1!G;$!d' sed.txt
3it will be import to you
1.第一行被放入模式空间,同时加上空行,但这个时候继续执行$!d删除命令,由于第一行不是最后一行,所以模式空间被清空
2.第二行被放入模式空间,同时加上空行,但这个时候继续执行$!d删除命令,由于第二行不是最后一行,所以模式空间被清空
3.直到第三行是最后一行,这个时候将模式空间中的内容复制到追加到第三行下面,结束
2.用sed模拟出tac的功能(倒序输出)
# 倒叙输出,实现act功能
[root@test /backup]# sed '1!G;h;$!d' sed.txt
3it will be import to you
2you can walk out on the street
1today is nice day
1.第一行被1!G读入模式空将,因为是第一行所以没有将保持空间中的空行复制,所以只有第一行;h将模式空间中的内容覆盖到保持空间,也只有第一行;$!d将模式空间直接清空
2.第二行,这个时候1!G,发现模式空间是第一行内容,直接追加到第二行下面;h直接将第二行和第一行这种倒序复制进入保持空间;$!d,第二行不是最后一行,所以清空模式空间内容
3.如果有多行继续执行第二行
4.直到最后一行,1!G按照所有行倒序的方式追加到最后一行下面;h将其复制进入保持空间;$!d最后一行不清空模式空间内容,所以输出就是倒序
3.删除空行别,在非空行后面加上空行
[root@test /backup]# cat sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
[root@test /backup]# sed '/^$/d;G' sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
1.第一行读入模式空间,非空,所以后面加上空行
2.第二行,同上
3.第三行读入是空行,删除,同时将第四行读入,非空,加上空行
4.显示奇数行
[root@test /backup]# cat sed.txt
1today is nice day
2you can walk out on the street
3it will be import to you
[root@test /backup]# sed 'n;d' sed.txt
1today is nice day
空行
1.获取第一行的下一行,删除,将第一行加入模式空间
2.第二行被删除了,第三行读入模式空间,并将它的下一行删除,
参考:
https://www.linuxidc.com/Linux/2016-08/134659.htm
https://www.cnblogs.com/ginvip/p/6376049.html