1.ClassCastException
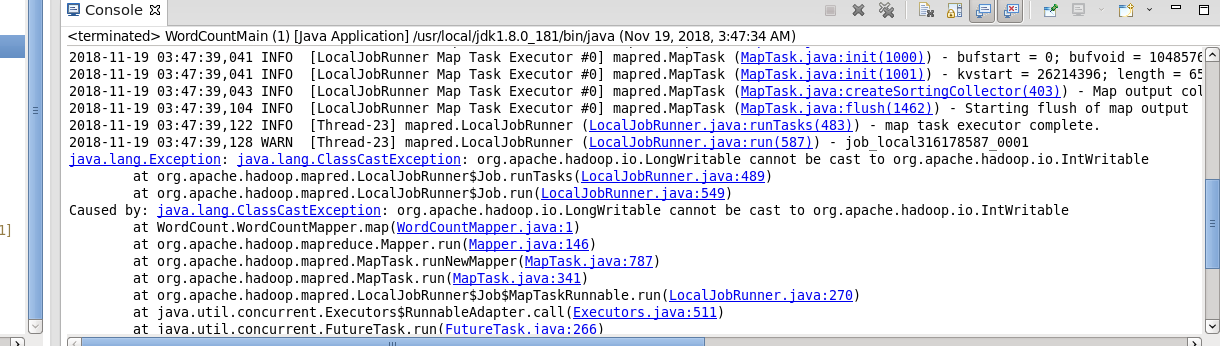
错误代码
/** * */ /** * @author hadoop * */ package WordCount; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN :是map task读取到的数据的key的类型,是一行的起始偏移量Long * VALUEIN:是map task读取到的数据的value的类型,是一行的内容String * * KEYOUT:是用户的自定义map方法要返回的结果kv数据的key的类型,在wordcount逻辑中,我们需要返回的是单词String * VALUEOUT:是用户的自定义map方法要返回的结果kv数据的value的类型,在wordcount逻辑中,我们需要返回的是整数Integer * * * 但是,在mapreduce中,map产生的数据需要传输给reduce,需要进行序列化和反序列化,而jdk中的原生序列化机制产生的数据量比较冗余,就会导致数据在mapreduce运行过程中传输效率低下 * 所以,hadoop专门设计了自己的序列化机制,那么,mapreduce中传输的数据类型就必须实现hadoop自己的序列化接口 * * hadoop为jdk中的常用基本类型Long String Integer Float等数据类型封住了自己的实现了hadoop序列化接口的类型:LongWritable,Text,IntWritable,FloatWritable * * * * * */ public class WordCountMapper extends Mapper<IntWritable, Text, Text, IntWritable> { @Override protected void map(IntWritable index, Text line, org.apache.hadoop.mapreduce.Mapper.Context context) throws IOException, InterruptedException { String str = line.toString(); String[] strList = str.split(" "); for (String word : strList) { context.write(new Text(word), new IntWritable(1)); } } }
正确代码
将第一个泛型修改成LongWritable
/** * */ /** * @author hadoop * */ package WordCount; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN :是map task读取到的数据的key的类型,是一行的起始偏移量Long * VALUEIN:是map task读取到的数据的value的类型,是一行的内容String * * KEYOUT:是用户的自定义map方法要返回的结果kv数据的key的类型,在wordcount逻辑中,我们需要返回的是单词String * VALUEOUT:是用户的自定义map方法要返回的结果kv数据的value的类型,在wordcount逻辑中,我们需要返回的是整数Integer * * * 但是,在mapreduce中,map产生的数据需要传输给reduce,需要进行序列化和反序列化,而jdk中的原生序列化机制产生的数据量比较冗余,就会导致数据在mapreduce运行过程中传输效率低下 * 所以,hadoop专门设计了自己的序列化机制,那么,mapreduce中传输的数据类型就必须实现hadoop自己的序列化接口 * * hadoop为jdk中的常用基本类型Long String Integer Float等数据类型封住了自己的实现了hadoop序列化接口的类型:LongWritable,Text,IntWritable,FloatWritable * * * * * */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable index, Text line, org.apache.hadoop.mapreduce.Mapper.Context context) throws IOException, InterruptedException { String str = line.toString(); String[] strList = str.split(" "); for (String word : strList) { context.write(new Text(word), new IntWritable(1)); } } }