Swarm介绍
Swarm是Docker公司在2014年12月初发布的一套较为简单的工具,用来管理Docker集群,它将一群Docker宿主机变成一个单一的,虚拟的主机。Swarm使用标准的Docker API接口作为其前端访问入口,换言之,各种形式的Docker Client(docker client in Go, docker_py, docker等)均可以直接与Swarm通信。Swarm几乎全部用Go语言来完成开发,Swarm0.2版本增加了一个新的策略来调度集群中的容器,使得在可用的节点上传播它们,以及支持更多的Docker命令以及集群驱动。Swarm deamon只是一个调度器(Scheduler)加路由器(router),Swarm自己不运行容器,它只是接受docker客户端发送过来的请求,调度适合的节点来运行容器,这意味着,即使Swarm由于某些原因挂掉了,集群中的节点也会照常运行,当Swarm重新恢复运行之后,它会收集重建集群信息。
Docker的Swarm(集群)模式,集成很多工具和特性,比如:跨主机上快速部署服务,服务的快速扩展,集群的管理整合到docker引擎,这意味着可以不可以不使用第三方管理工具。分散设计,声明式的服务模型,可扩展,状态协调处理,多主机网络,分布式的服务发现,负载均衡,滚动更新,安全(通信的加密)等等,下面就来认识下Swarm(对于Swarm管理的详细操作可以参考:https://www.centos.bz/tag/swarm/page/3/)
Swarm架构
Swarm作为一个管理Docker集群的工具,首先需要将其部署起来,可以单独将Swarm部署于一个节点。另外,自然需要一个Docker集群,集群上每一个节点均安装有Docker。具体的Swarm架构图可以参照下图:
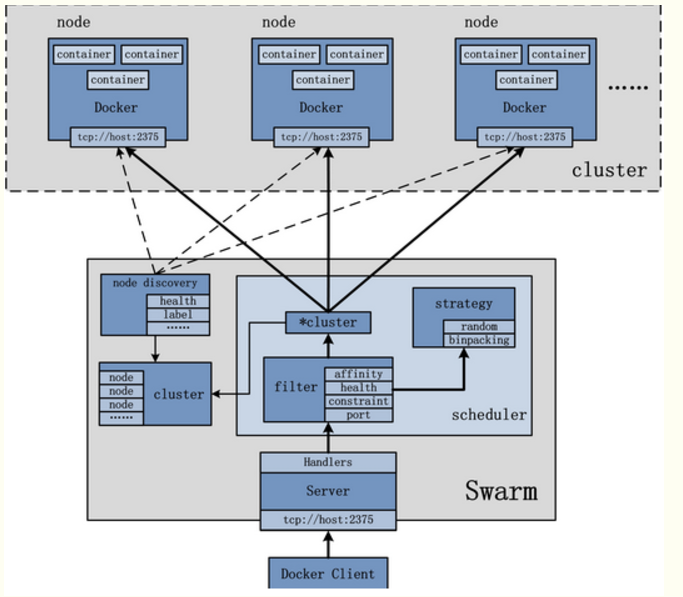
Swarm架构中最主要的处理部分自然是Swarm节点,Swarm管理的对象自然是Docker Cluster,Docker Cluster由多个Docker Node组成,而负责给Swarm发送请求的是Docker Client。
Swarm关键概念
1)Swarm 集群的管理和编排是使用嵌入到docker引擎的SwarmKit,可以在docker初始化时启动swarm模式或者加入已存在的swarm 2)Node 一个节点(node)是已加入到swarm的Docker引擎的实例 当部署应用到集群,你将会提交服务定义到管理节点,接着Manager 管理节点调度任务到worker节点,manager节点还执行维护集群的状态的编排和群集管理功能,worker节点接收并执行来自 manager节点的任务。通常,manager节点也可以是worker节点,worker节点会报告当前状态给manager节点 3)服务(Service) 服务是要在worker节点上要执行任务的定义,它在工作者节点上执行,当你创建服务的时,你需要指定容器镜像 4)任务(Task) 任务是在docekr容器中执行的命令,Manager节点根据指定数量的任务副本分配任务给worker节点 -------------------------------------------------------------------------------------------------------- docker swarm:集群管理,子命令有init, join, leave, update。(docker swarm --help查看帮助) docker service:服务创建,子命令有create, inspect, update, remove, tasks。(docker service--help查看帮助) docker node:节点管理,子命令有accept, promote, demote, inspect, update, tasks, ls, rm。(docker node --help查看帮助) node是加入到swarm集群中的一个docker引擎实体,可以在一台物理机上运行多个node,node分为: manager nodes,也就是管理节点 worker nodes,也就是工作节点 1)manager node管理节点:执行集群的管理功能,维护集群的状态,选举一个leader节点去执行调度任务。 2)worker node工作节点:接收和执行任务。参与容器集群负载调度,仅用于承载task。 3)service服务:一个服务是工作节点上执行任务的定义。创建一个服务,指定了容器所使用的镜像和容器运行的命令。 service是运行在worker nodes上的task的描述,service的描述包括使用哪个docker 镜像,以及在使用该镜像的容器中执行什么命令。 4)task任务:一个任务包含了一个容器及其运行的命令。task是service的执行实体,task启动docker容器并在容器中执行任务。
Swarm工作方式
1)Node
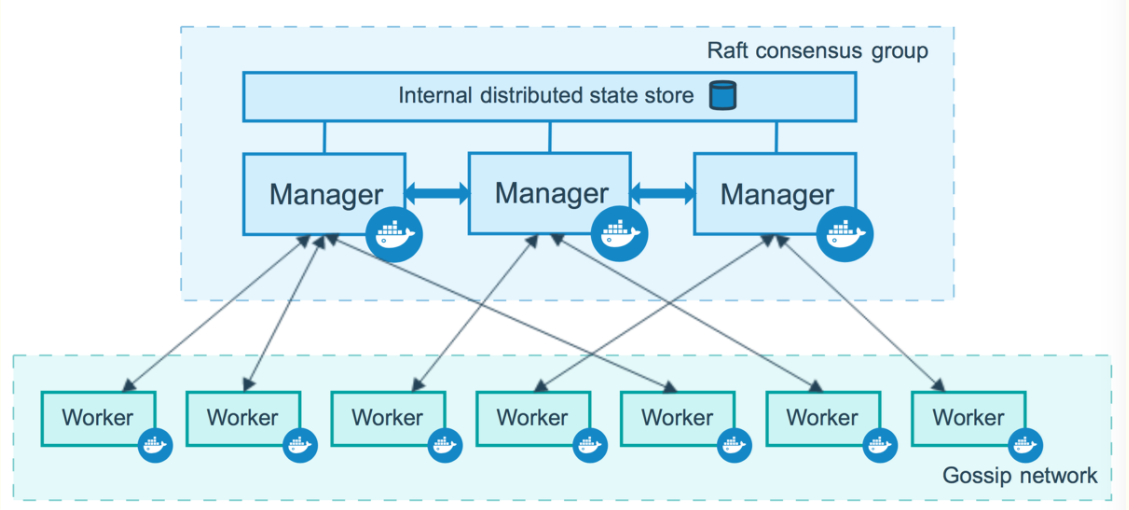
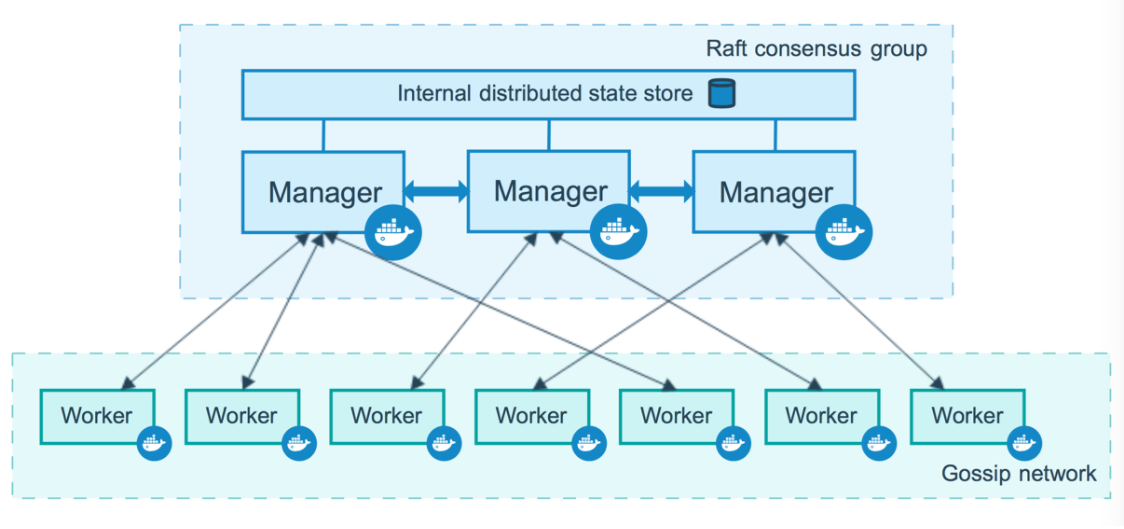
2)Service(服务, 任务, 容器)

3)任务与调度
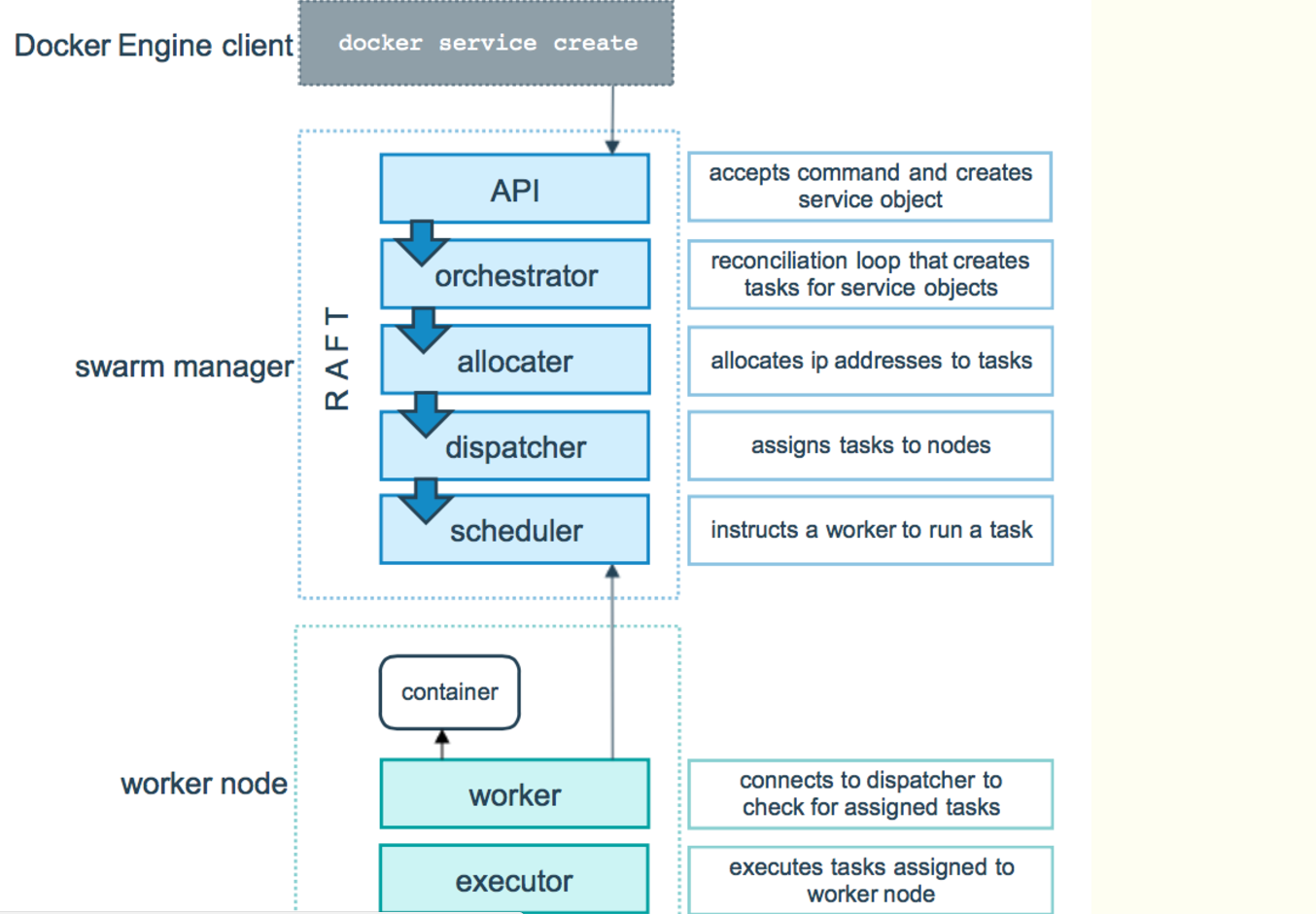
4)服务副本与全局服务
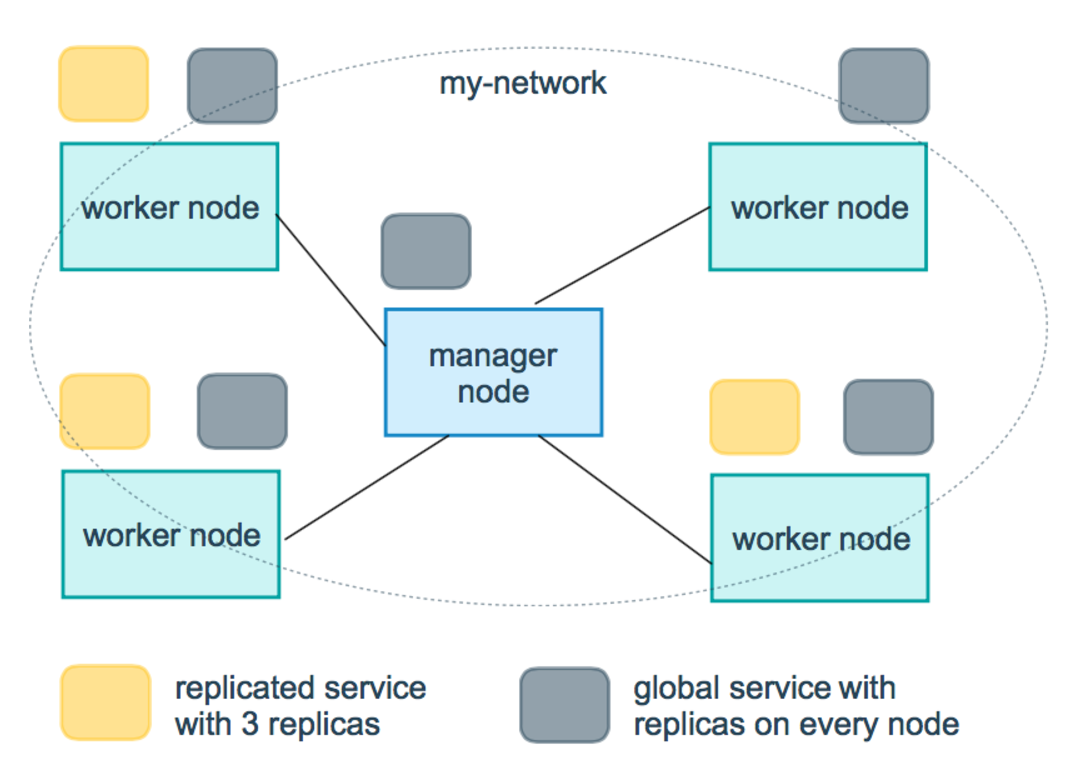
Swarm调度策略
Swarm在scheduler节点(leader节点)运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random. 1)Random 顾名思义,就是随机选择一个Node来运行容器,一般用作调试用,spread和binpack策略会根据各个节点的可用的CPU, RAM以及正在运 行的容器的数量来计算应该运行容器的节点。 2)Spread 在同等条件下,Spread策略会选择运行容器最少的那台节点来运行新的容器,binpack策略会选择运行容器最集中的那台机器来运行新的节点。 使用Spread策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。 3)Binpack Binpack策略最大化的避免容器碎片化,就是说binpack策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在 一个节点上面。
Swarm Cluster模式的特性
1)批量创建服务 建立容器之前先创建一个overlay的网络,用来保证在不同主机上的容器网络互通的网络模式 2)强大的集群的容错性 当容器副本中的其中某一个或某几个节点宕机后,cluster会根据自己的服务注册发现机制,以及之前设定的值--replicas n, 在集群中剩余的空闲节点上,重新拉起容器副本。整个副本迁移的过程无需人工干预,迁移后原本的集群的load balance依旧好使! 不难看出,docker service其实不仅仅是批量启动服务这么简单,而是在集群中定义了一种状态。Cluster会持续检测服务的健康状态 并维护集群的高可用性。 3)服务节点的可扩展性 Swarm Cluster不光只是提供了优秀的高可用性,同时也提供了节点弹性扩展或缩减的功能。当容器组想动态扩展时,只需通过scale 参数即可复制出新的副本出来。 仔细观察的话,可以发现所有扩展出来的容器副本都run在原先的节点下面,如果有需求想在每台节点上都run一个相同的副本,方法 其实很简单,只需要在命令中将"--replicas n"更换成"--mode=global"即可! 复制服务(--replicas n) 将一系列复制任务分发至各节点当中,具体取决于您所需要的设置状态,例如“--replicas 3”。 全局服务(--mode=global) 适用于集群内全部可用节点上的服务任务,例如“--mode global”。如果大家在 Swarm 集群中设有 7 台 Docker 节点,则全部节点之上都将存在对应容器。 4. 调度机制 所谓的调度其主要功能是cluster的server端去选择在哪个服务器节点上创建并启动一个容器实例的动作。它是由一个装箱算法和过滤器 组合而成。每次通过过滤器(constraint)启动容器的时候,swarm cluster 都会调用调度机制筛选出匹配约束条件的服务器,并在这上面运行容器。 ------------------Swarm cluster的创建过程包含以下三个步骤---------------------- 1)发现Docker集群中的各个节点,收集节点状态、角色信息,并监视节点状态的变化 2)初始化内部调度(scheduler)模块 3)创建并启动API监听服务模块 一旦创建好这个cluster,就可以用命令docker service批量对集群内的容器进行操作,非常方便! 在启动容器后,docker 会根据当前每个swarm节点的负载判断,在负载最优的节点运行这个task任务,用"docker service ls" 和"docker service ps + taskID" 可以看到任务运行在哪个节点上。容器启动后,有时需要等待一段时间才能完成容器创建。
Swarm集群部署实例(Swarm Cluster)
1)机器环境(均是centos7.2)
182.48.115.237 swarm的manager节点 manager-node 182.48.115.238 swarm的node节点 node1 182.48.115.239 swarm的node节点 node2 设置主机名 在manager节点上 [root@manager-node ~]# hostnamectl --static set-hostname manager-node 在node1节点上 [root@node1 ~]# hostnamectl --static set-hostname node1 在node2节点上 [root@node2 ~]# hostnamectl --static set-hostname node2 在三台机器上都要设置hosts,均执行如下命令: [root@manager-node ~]# vim /etc/hosts ...... 182.48.115.237 manager-node 182.48.115.238 node1 182.48.115.239 node2 关闭三台机器上的防火墙。如果开启防火墙,则需要在所有节点的防火墙上依次放行2377/tcp(管理端口)、7946/udp(节点间通信端口)、4789/udp(overlay 网络端口)端口。 [root@manager-node ~]# systemctl disable firewalld.service [root@manager-node ~]# systemctl stop firewalld.service
2)分别在manager节点和node节点上安装docker,并下载swarm镜像
[root@manager-node ~]# yum install -y docker 配置docker [root@manager-node ~]# vim /etc/sysconfig/docker ...... OPTIONS='-H 0.0.0.0:2375 -H unix:///var/run/docker.sock' //在OPTIONS参数项后面的''里添加内容 [root@manager-node ~]# systemctl restart docker 下载swarm镜像 [root@manager-node ~]# docker pull swarm [root@manager-node ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/swarm latest 36b1e23becab 4 months ago 15.85 MB
3)创建swarm(要保存初始化后token,因为在节点加入时要使用token作为通讯的密钥)
[root@manager-node ~]# docker swarm init --advertise-addr 182.48.115.237 Swarm initialized: current node (1gi8utvhu4rxy8oxar2g7h6gr) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-4roc8fx10cyfgj1w1td8m0pkyim08mve578wvl03eqcg5ll3ig-f0apd81qfdwv27rnx4a4y9jej 182.48.115.237:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions. 上面命令执行后,该机器自动加入到swarm集群。这个会创建一个集群token,获取全球唯一的 token,作为集群唯一标识。后续将其他节点加入集群都会用到这个token值。 其中,--advertise-addr参数表示其它swarm中的worker节点使用此ip地址与manager联系。命令的输出包含了其它节点如何加入集群的命令。 ------------------------------------------------------------------------------------------------------------------- 温馨提示: 如果再次执行上面启动swarm集群的命令,会报错说这个节点已经在集群中了 Error response from daemon: This node is already part of a swarm. Use "docker swarm leave" to leave this swarm and join another one. 解决办法: [root@manager-node ~]# docker swarm leave --help //查看帮助 [root@manager-node ~]# docker swarm leave --force ------------------------------------------------------------------------------------------------------------------- 使用docker info 或 docker node ls 查看集群中的相关信息 [root@manager-node ~]# docker info ....... Swarm: active NodeID: 1gi8utvhu4rxy8oxar2g7h6gr Is Manager: true ClusterID: a88a9j6nwcbn31oz6zp9oc0f7 Managers: 1 Nodes: 1 Orchestration: Task History Retention Limit: 5 ....... [root@manager-node ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS 1gi8utvhu4rxy8oxar2g7h6gr * manager-node Ready Active Leader 注意上面node ID旁边那个*号表示现在连接到这个节点上。
4)添加节点到swarm集群中
在docker swarm init 完了之后,会提示如何加入新机器到集群,如果当时没有注意到,也可以通过下面的命令来获知 如何加入新机器到集群。 登录到node1节点上,执行前面创建swarm集群时输出的命令: [root@node1 ~]# docker swarm join --token SWMTKN-1-4roc8fx10cyfgj1w1td8m0pkyim08mve578wvl03eqcg5ll3ig-f0apd81qfdwv27rnx4a4y9jej 182.48.115.237:2377 This node joined a swarm as a worker. 同理在node2节点上,也执行这个命令 [root@node2 ~]# docker swarm join --token SWMTKN-1-4roc8fx10cyfgj1w1td8m0pkyim08mve578wvl03eqcg5ll3ig-f0apd81qfdwv27rnx4a4y9jej 182.48.115.237:2377 This node joined a swarm as a worker. 如果想要将其他更多的节点添加到这个swarm集群中,添加方法如上一致! 然后在manager-node管理节点上看一下集群节点的状态: [root@manager-node ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS 1gi8utvhu4rxy8oxar2g7h6gr * manager-node Ready Active Leader ei53e7o7jf0g36329r3szu4fi node1 Ready Active f1obgtudnykg51xzyj5fs1aev node2 Ready Active -------------------------------------------------------------------------------------------------------------------- 温馨提示:更改节点的availablity状态 swarm集群中node的availability状态可以为 active或者drain,其中: active状态下,node可以接受来自manager节点的任务分派; drain状态下,node节点会结束task,且不再接受来自manager节点的任务分派(也就是下线节点)。 [root@manager-node ~]# docker node update --availability drain node1 //将node1节点下线。如果要删除node1节点,命令是"docker node rm --force node1" [root@manager-node ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS 1gi8utvhu4rxy8oxar2g7h6gr * manager-node Ready Active Leader ei53e7o7jf0g36329r3szu4fi node1 Ready drain f1obgtudnykg51xzyj5fs1aev node2 Ready Active 如上,当node1的状态改为drain后,那么该节点就不会接受task任务分发,就算之前已经接受的任务也会转移到别的节点上。 再次修改为active状态(及将下线的节点再次上线) [root@manager-node ~]# docker node update --availability drain node1
5)在Swarm中部署服务(这里以nginx服务为例)
Docker 1.12版本提供服务的Scaling、health check、滚动升级等功能,并提供了内置的dns、vip机制,实现service的服务发现和负载均衡能力。 在启动容器之前,先来创建一个覆盖网络,用来保证在不同主机上的容器网络互通的网络模式 [root@manager-node ~]# docker network create -d overlay ngx_net [root@manager-node ~]# docker network ls NETWORK ID NAME DRIVER SCOPE 8bbd1b7302a3 bridge bridge local 9e637a97a3b9 docker_gwbridge bridge local b5a41c8c71e7 host host local 1x45zepuysip ingress overlay swarm 3ye6vfp996i6 ngx_net overlay swarm 0808a5c72a0a none null local 在manager-node节点上使用上面这个覆盖网络创建nginx服务: 其中,--replicas 参数指定服务由几个实例组成。 注意:不需要提前在节点上下载nginx镜像,这个命令执行后会自动下载这个容器镜像(比如此处创建tomcat容器,就将下面命令中的镜像改为tomcat镜像)。 [root@manager-node ~]# docker service create --replicas 1 --network ngx_net --name my-test -p 80:80 nginx 就创建了一个具有一个副本(--replicas 1 )的nginx服务,使用镜像nginx 使用 docker service ls 查看正在运行服务的列表 [root@manager-node ~]# docker service ls ID NAME REPLICAS IMAGE COMMAND 0jb5eebo8j9q my-test 1/1 nginx 查询Swarm中服务的信息 -pretty 使命令输出格式化为可读的格式,不加 --pretty 可以输出更详细的信息: [root@manager-node ~]# docker service inspect --pretty my-test ID: 0jb5eebo8j9qb1zc795vx3py3 Name: my-test Mode: Replicated Replicas: 1 Placement: UpdateConfig: Parallelism: 1 On failure: pause ContainerSpec: Image: nginx Resources: Networks: 3ye6vfp996i6eq17tue0c2jv9 Ports: Protocol = tcp TargetPort = 80 PublishedPort = 80 查询到哪个节点正在运行该服务。如下该容器被调度到manager-node节点上启动了,然后访问http://182.48.115.237即可访问这个容器应用(如果调度到其他节点,访问也是如此) [root@manager-node ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 2m8qqpoa0dpeua5jbgz1infuy my-test.1 nginx manager-node Running Running 3 minutes ago 注意,如果上面命令执行后,上面的 STATE 字段中刚开始的服务状态为 Preparing,需要等一会才能变为 Running 状态,其中最费时间的应该是下载镜像的过程。 有上面命令可知,该服务在manager-node节点上运行。登陆该节点,可以查看到nginx容器在运行中 [root@manager-node ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1ea1d72007da nginx:latest "nginx -g 'daemon off" 4 minutes ago Up 4 minutes 80/tcp my-test.1.2m8qqpoa0dpeua5jbgz1infuy -----------------------------------------------------------在Swarm中动态扩展服务(scale)----------------------------------------------------------- 当然,如果只是通过service启动容器,swarm也算不上什么新鲜东西了。Service还提供了复制(类似kubernetes里的副本)功能。可以通过 docker service scale 命令来设置服务中容器的副本数: 比如将上面的my-test容器动态扩展到5个,命令如下: [root@manager-node ~]# docker service scale my-test=5 和创建服务一样,增加scale数之后,将会创建新的容器,这些新启动的容器也会经历从准备到运行的过程,过一分钟左右,服务应该就会启动完成,这时候可以再来看一下 nginx 服务中的容器 [root@manager-node ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 2m8qqpoa0dpeua5jbgz1infuy my-test.1 nginx manager-node Running Running 9 minutes ago aqko8yhmdj53gmzs8gqhoylc2 my-test.2 nginx node2 Running Running 2 minutes ago erqk394hd4ay7nfwgaz4zp3s0 my-test.3 nginx node1 Running Running 2 minutes ago 2dslg6w16wzcgboa2hxw1c6k1 my-test.4 nginx node1 Running Running 2 minutes ago bmyddndlx6xi18hx4yinpakf3 my-test.5 nginx manager-node Running Running 2 minutes ago 可以看到,之前my-test容器只在manager-node节点上有一个实例,而现在又增加了4个实例。 这5个副本的my-test容器分别运行在这三个节点上,登陆这三个节点,就会发现已经存在运行着的my-test容器。 ----------------------------------------------------------------------------------------------------- 特别需要清楚的一点: 如果一个节点宕机了(即该节点就会从swarm集群中被踢出),则Docker应该会将在该节点运行的容器,调度到其他节点,以满足指定数量的副本保持运行状态。 比如: 将node1宕机后或将node1的docker服务关闭,那么它上面的task实例就会转移到别的节点上。当node1节点恢复后,它转移出去的task实例不会主动转移回来, 只能等别的节点出现故障后转移task实例到它的上面。使用命令"docker node ls",发现node1节点已不在swarm集群中了。 然后过一会查询服务的状态列表 [root@manager-node ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 2m8qqpoa0dpeua5jbgz1infuy my-test.1 docker.io/nginx manager-node Running Running 33 minutes ago aqko8yhmdj53gmzs8gqhoylc2 my-test.2 docker.io/nginx node2 Running Running 26 minutes ago di99oj7l9x6firw1ai25sewwc my-test.3 docker.io/nginx node2 Running Running 6 minutes ago erqk394hd4ay7nfwgaz4zp3s0 \_ my-test.3 docker.io/nginx node1 Shutdown Complete 5 minutes ago aibl3u3pph3fartub0mhwxvzr my-test.4 docker.io/nginx node2 Running Running 6 minutes ago 2dslg6w16wzcgboa2hxw1c6k1 \_ my-test.4 docker.io/nginx node1 Shutdown Complete 5 minutes ago bmyddndlx6xi18hx4yinpakf3 my-test.5 docker.io/nginx manager-node Running Running 26 minutes ago 发现,node1节点出现故障后,它上面之前的两个task任务已经转移到node2节点上了。 登陆到node2节点上,可以看到这两个运行的task任务。当访问182.48.115.239节点的80端口,swarm的负载均衡会把请求路由到一个任意节点的可用的容器上。 [root@node2 ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 216abf6bebea docker.io/nginx:latest "nginx -g 'daemon off" 7 minutes ago Up 7 minutes 80/tcp my-test.3.di99oj7l9x6firw1ai25sewwc 1afd12cc9140 docker.io/nginx:latest "nginx -g 'daemon off" 7 minutes ago Up 7 minutes 80/tcp my-test.4.aibl3u3pph3fartub0mhwxvzr cc90da57c25e docker.io/nginx:latest "nginx -g 'daemon off" 27 minutes ago Up 27 minutes 80/tcp my-test.2.aqko8yhmdj53gmzs8gqhoylc2 再次在node2节点上将从node1上转移过来的两个task关闭 [root@node2 ~]# docker stop my-test.3.di99oj7l9x6firw1ai25sewwc my-test.4.aibl3u3pph3fartub0mhwxvzr my-test.3.di99oj7l9x6firw1ai25sewwc my-test.4.aibl3u3pph3fartub0mhwxvzr 再次查询服务的状态列表,发现这两个task又转移到node1上了(即在swarm cluster集群中启动的容器,在worker node节点上删除或停用后,该容器会自动转移到其他的worker node节点上) [root@manager-node ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 2m8qqpoa0dpeua5jbgz1infuy my-test.1 docker.io/nginx manager-node Running Running 38 minutes ago aqko8yhmdj53gmzs8gqhoylc2 my-test.2 docker.io/nginx node2 Running Running 31 minutes ago 7dhmc63rk0bc8ngt59ix38l44 my-test.3 docker.io/nginx node1 Running Running about a minute ago di99oj7l9x6firw1ai25sewwc \_ my-test.3 docker.io/nginx node2 Shutdown Complete about a minute ago erqk394hd4ay7nfwgaz4zp3s0 \_ my-test.3 docker.io/nginx node1 Shutdown Complete 9 minutes ago 607tyjv6foc0ztjjvdo3l3lge my-test.4 docker.io/nginx node1 Running Running about a minute ago aibl3u3pph3fartub0mhwxvzr \_ my-test.4 docker.io/nginx node2 Shutdown Complete about a minute ago 2dslg6w16wzcgboa2hxw1c6k1 \_ my-test.4 docker.io/nginx node1 Shutdown Complete 9 minutes ago bmyddndlx6xi18hx4yinpakf3 my-test.5 docker.io/nginx manager-node Running Running 31 minutes ago ---------------------------------------------------------------------------------------------------- 同理,swarm还可以缩容,如下,将my-test容器变为1个。 [root@manager-node ~]# docker service scale my-test=1 [root@manager-node ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 2m8qqpoa0dpeuasdfsdfdfsdf my-test.1 nginx manager-node Running Running 3 minutes ago 登录node2节点,使用docker ps查看,会发现容器被stop而非rm --------------------------------------------------------------------------------------------------- 删除容器服务 [root@manager-node ~]# docker service --help //查看帮助 [root@manager-node ~]# docker service rm my-test //这样就会把所有节点上的所有容器(task任务实例)全部删除了 my-nginx --------------------------------------------------------------------------------------------------- 除了上面使用scale进行容器的扩容或缩容之外,还可以使用docker service update 命令。 可对 服务的启动 参数 进行 更新/修改。 [root@manager-node ~]# docker service update --replicas 3 my-test my-test 更新完毕以后,可以查看到REPLICAS已经变成3/3 [root@manager-node ~]# docker service ls ID NAME REPLICAS IMAGE COMMAND d7cygmer0yy5 my-test 3/3 nginx /bin/bash [root@manager-node ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR ddkidkz0jgor751ffst55kvx4 my-test.1 nginx node1 Running Preparing 4 seconds ago 1aucul1b3qwlmu6ocu312nyst \_ my-test.1 nginx manager-node Shutdown Complete 5 seconds ago 4w9xof53f0falej9nqgq064jz \_ my-test.1 nginx manager-node Shutdown Complete 19 seconds ago 0e9szyfbimaow9tffxfeymci2 \_ my-test.1 nginx manager-node Shutdown Complete 30 seconds ago 27aqnlclp0capnp1us1wuiaxm my-test.2 nginx manager-node Running Preparing 1 seconds ago 7dmmmle29uuiz8ey3tq06ebb8 my-test.3 nginx manager-node Running Preparing 1 seconds ago docker service update 命令,也可用于直接 升级 镜像等。 [root@manager-node ~]# docker service update --image nginx:new my-test [root@manager-node ~]# docker service ls ID NAME REPLICAS IMAGE COMMAND d7cygmer0yy5 my-test 3/3 nginx:new /bin/bash
6)Swarm中使用Volume(挂在目录,mount)
查看docker volume的帮助信息 [root@manager-node ~]# docker volume --help Usage: docker volume COMMAND Manage Docker volumes Options: --help Print usage Commands: create Create a volume inspect Display detailed information on one or more volumes ls List volumes rm Remove one or more volumes Run 'docker volume COMMAND --help' for more information on a command. [root@manager-node ~]# docker volume create --name myvolume myvolume [root@manager-node ~]# docker volume ls DRIVER VOLUME NAME local 11b68dce3fff0d57172e18bc4e4cfc252b984354485d747bf24abc9b11688171 local 1cd106ed7416f52d6c77ed19ee7e954df4fa810493bb7e6cf01775da8f9c475f local myvolume 参数src写成source也可以;dst表示容器内的路径,也可以写成target [root@manager-node ~]# docker service create --replicas 2 --mount type=volume,src=myvolume,dst=/wangshibo --name test-nginx nginx [root@manager-node ~]# docker service ls ID NAME REPLICAS IMAGE COMMAND 8s9m0okwlhvl test-nginx 2/2 nginx [root@manager-node ~]# docker service ps test-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 32bqjjhqcl1k5z74ijjli35z3 test-nginx.1 nginx node1 Running Running 23 seconds ago 48xoypunb3g401jkn690lx7xt test-nginx.2 nginx node2 Running Running 23 seconds ago 登录node1节点的test-nginx容器查看 [root@node1 ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d471569629b2 nginx:latest "nginx -g 'daemon off" 2 minutes ago Up 2 minutes 80/tcp test-nginx.1.32bqjjhqcl1k5z74ijjli35z3 [root@node1 ~]# docker exec -ti d471569629b2 /bin/bash root@d471569629b2:/# cd /wangshibo/ root@d471569629b2:/wangshibo# ls root@d471569629b2:/wangshibo# echo "ahahha" > test root@d471569629b2:/wangshibo# ls test [root@node1 ~]# docker volume inspect myvolume [ { "Name": "myvolume", "Driver": "local", "Mountpoint": "/var/lib/docker/volumes/myvolume/_data", "Labels": null, "Scope": "local" } ] [root@node1 ~]# cd /var/lib/docker/volumes/myvolume/_data/ [root@node1 _data]# ls test [root@node1 _data]# cat test ahahha [root@node1 _data]# echo "12313" > 123 [root@node1 _data]# ls 123 test root@d471569629b2:/wangshibo# ls 123 test root@d471569629b2:/wangshibo# cat test ahahha 还可以将node11节点机上的volume数据目录做成阮链接 [root@node1 ~]# ln -s /var/lib/docker/volumes/myvolume/_data /wangshibo [root@node1 ~]# cd /wangshibo [root@node1 wangshibo]# ls 123 test [root@node1 wangshibo]# rm -f test [root@node1 wangshibo]# echo "5555" > haha root@d471569629b2:/wangshibo# ls 123 haha root@d471569629b2:/wangshibo# cat haha 5555 --------------------------------------------------------------------------------- 第二种方法: 命令格式: docker service create --mount type=bind,target=/container_data/,source=/host_data/ 其中,参数target表示容器里面的路径,source表示本地硬盘路径 [root@manager-node ~]# docker service create --replicas 1 --mount type=bind,target=/usr/share/nginx/html/,source=/opt/web/ --network ngx_net --name haha-nginx -p 8880:80 nginx [root@manager-node ~]# docker service ls ID NAME REPLICAS IMAGE COMMAND 9t9d58b5bq4u haha-nginx 1/1 nginx [root@manager-node ~]# docker service ps haha-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR bji4f5tikhvm7nf5ief3jk2is haha-nginx.1 nginx node2 Running Running 18 seconds ago 登录node2节点,在挂载目录/opt/web下写测试数据 [root@node2 _data]# cd /opt/web/ [root@node2 web]# ls [root@node2 web]# cat wang.html sdfasdf 登录容器查看,发现已经实现数据同步 [root@node2 ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3618e3d1b966 nginx:latest "nginx -g 'daemon off" 28 seconds ago Up 24 seconds 80/tcp haha-nginx.1.bji4f5tikhvm7nf5ief3jk2is [root@node2 ~]# docker exec -ti 3618e3d1b966 /bin/bash root@3618e3d1b966:/# cd /usr/share/nginx/html root@3618e3d1b966:/usr/share/nginx/html# ls wang.html root@3618e3d1b966:/usr/share/nginx/html# cat wang.html sdfasdf root@3618e3d1b966:/usr/share/nginx/html# touch test touch: cannot touch 'test': Permission denied 由此可见,以上设置后,在容器里的同步目录下没有写权限,更新内容时只要放到宿主机的挂在目录下即可!
总之,Swarm上手很简单,Docker swarm可以非常方便的创建类似kubernetes那样带有副本的服务,确保一定数量的容器运行,保证服务的高可用。
然而,光从官方文档来说,功能似乎又有些简单;
swarm、kubernetes、messos总体比较而言:
1)Swarm的优点和缺点都是使用标准的Docker接口,使用简单,容易集成到现有系统,但是更困难支持更复杂的调度,比如以定制接口方式定义的调度。
2)Kubernetes 是自成体系的管理工具,有自己的服务发现和复制,需要对现有应用的重新设计,但是能支持失败冗余和扩展系统。
3)Mesos是低级别 battle-hardened调度器,支持几种容器管理框架如Marathon, Kubernetes, and Swarm,现在Kubernetes和Mesos稳定性超过Swarm,在扩展性方面,Mesos已经被证明支持超大规模的系统,比如数百数千台主机,但是,如果你需要小的集群,比如少于一打数量的节点服务器数量,Mesos也许过于复杂了。
转载本文连接:
http://www.cnblogs.com/kevingrace/p/6870359.html
docker集群管理工具-Kubernetes部署记录:
http://www.cnblogs.com/kevingrace/p/5575666.html
Mesos+Zookeeper+Marathon的docker管理平台部署记录(1):
http://www.cnblogs.com/kevingrace/p/5685313.html
Mesos+Zookeeper+Marathon的docker管理平台部署记录(2)--负载均衡marathon-lb:
http://www.cnblogs.com/kevingrace/p/6845980.html