Self-distillation with Batch Knowledge Ensembling Improves ImageNet Classification
- 2021.5.13
- Project Page: https://geyixiao.com/projects/bake
- https://arxiv.org/abs/2104.13298
Introduction
- 主要目标在于给batch内的每一个作为anchor的图片通过传播同一个batch内其他样本的知识生成细化的软标签refined soft label,所传播的知识为batch内样本之间的相似度
- 该方法基于这样的假设:外观相似的样本应有更一致的类别预测
- 实际中对于每个样本,将batch内别的样本的预测结果或通过加权传播的方式形成软目标
- 知识的传播是经过迭代处理的,直到其收敛
- 折是第一个没有用多个网络或额外的分支来生成 ensembled soft target的自蒸馏方法
- 所提出的batch knowledge ensembling使用样本之间的知识生成惊喜的蒸馏目标
Method
-
具体的实现方法其实通过伪代码可以非常清晰的理解,这边还是介绍一下具体过程,整体框架图如下
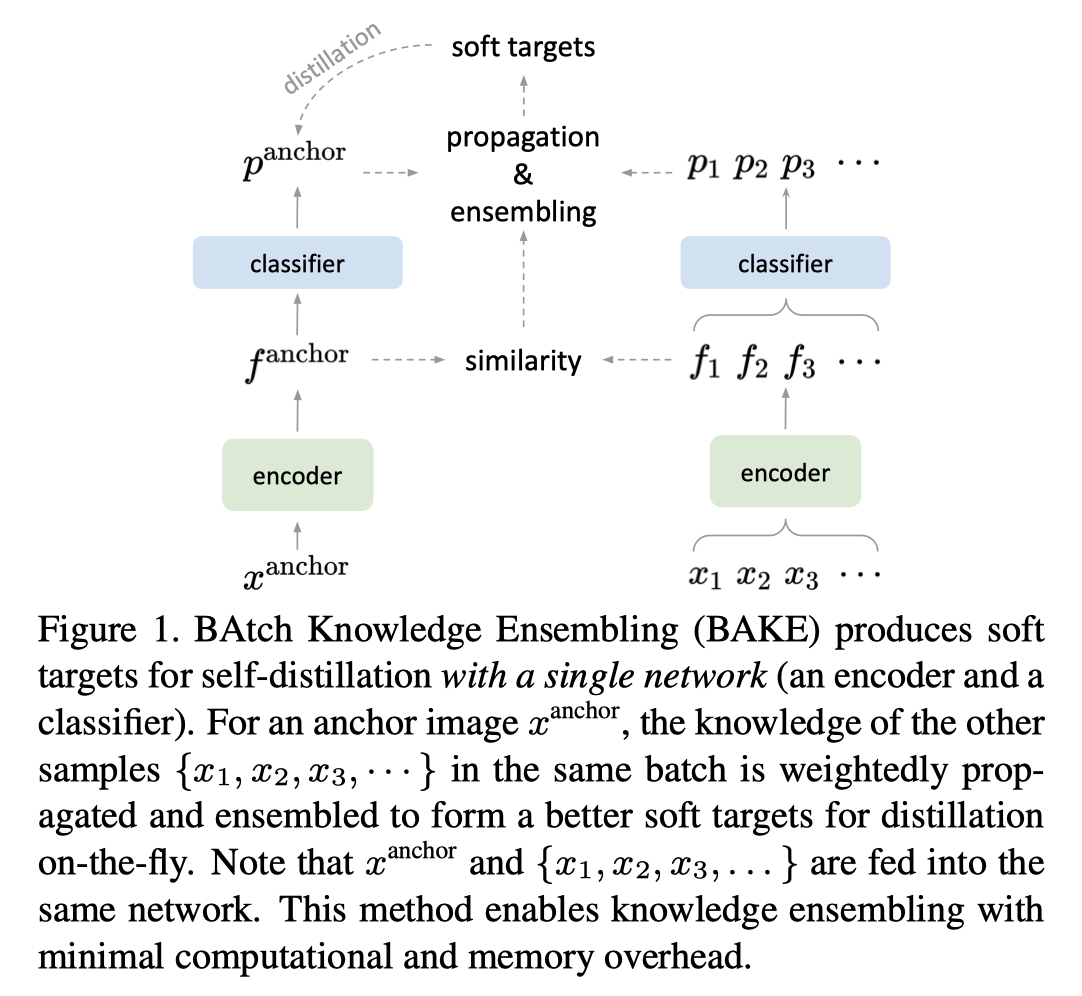
-
对于我们要传播的label知识,首先是要对batch内所有的样本进行相似性计算,生成相似性矩阵(Ain mathbb{R}^{N imes N}),相似性计算后,去除对角线删去自己与自己的相似性,然后进行一个归一化,对于每一个样本的相似性向量和各元素和为1,记作(hat{A})
-
将原先所预测出每个样本所对应的logit记作(P^{ au}),然后将上一步计算出的相似性矩阵与之相乘,相当于利用相似性作一个加权(hat{P^{ au}}=hat{A}P^{ au})
-
对于相似性传播过来的label,我们也要进行一个加权,相当于是得到了我们想要的细化的logit:
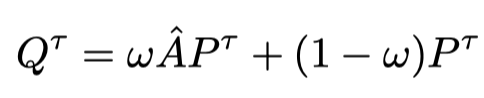
-
这样的知识传播需要进行数次,直到收敛,这时候公式中t表示第t次传播与迭代

- 当我们t趋于无穷大时,我们对此求极限,相当于是一个等比级数的极限,证明也很简单,值得注意的是上式中第一项极限为0
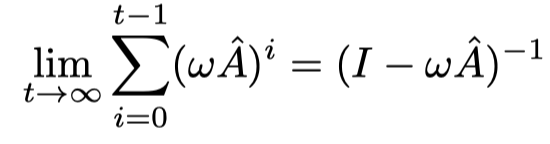
- 所以最后我们的知识加权传播模块最终可以表示成如下,该公式在下面的代码中也有所体现,算是真正得到了我们想要的吸取了batch内所有其他样本后的logit,值得注意的是对于每一个样本的refined logit和刚好为1,所以可以直接用:
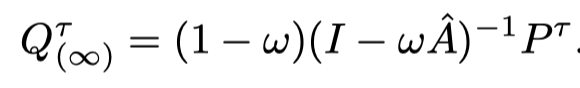
- 最后就对于原本的logit和我们细化的logit之间做一次KL loss,加上一定的权重后和原本的CE loss成为本自蒸馏项目全部的loss
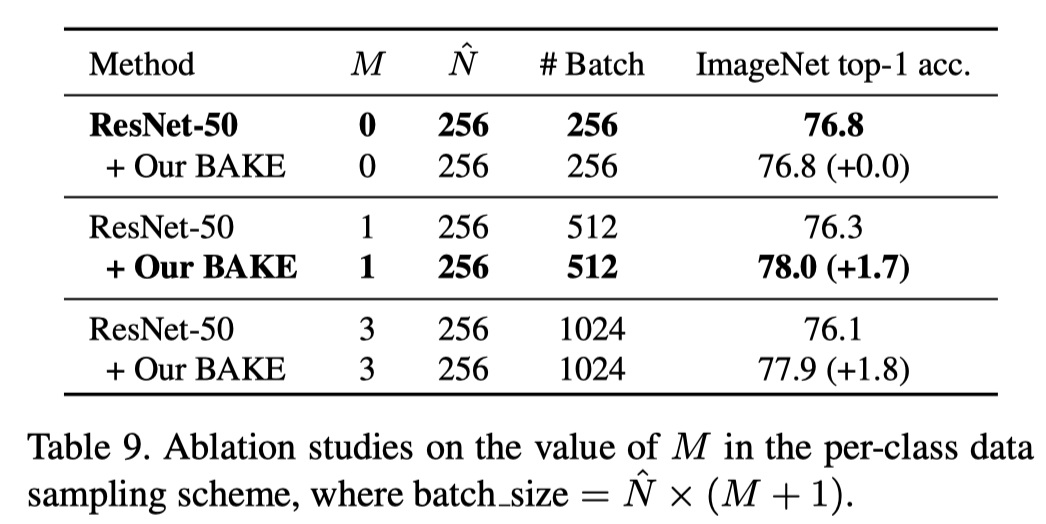
- 值得注意的是,在这个工作中有非常重要的一点,因为logit的细化蒸馏主要依赖于相似性,在一个batch内如果没有相似的样本其实是本方法是无效的,所以我们引入了一个对每类都采样的机制,对于batch大小为(N)内有一张图片后随机选取同类的(M)张图放入同一个batch中,组成新的batch,这时新的batch大小为(N imes (M+1))
# w: ensembling weight
# t: temperature
# r: loss weight
for (x, gt_labels) in loader:
# features: N×D, logits: N×K 分别是embedding特征和logit
f, logits = net.forward(x)
# classification loss with ground-truth labels
loss = CrossEntropyLoss(logits, gt labels)
# produce soft targets
f = normalize(f)
# 计算batch内各样本之间的相似度并去除中间的自己与自己,进行一个softmax变成0-1之间,得到公式中的A
A = softmax(mm(f, f.t())-eye(N)*1e-9) # row-wise normalization of affinity matrix with zero diagonal
# 最后求过极限之后得到的公式 得到soft_target
soft_targets = mm((1-w)·inv(eye(N)-w·A),softmax(logits/t)) # approximate inference for propagation and ensembling
soft_targets = soft_targets.detach() # no gradient
# distillation loss with soft targets 两个target之间的KL loss
loss += KLDivLoss(log_softmax(logits/t), soft_targets)*t^2*r
# SGD update
loss.backward()
update(net.params)
Experiments & Result
-
做了很多实验来证明其有效性,首先给出了训练的细节,如(N=256,M=1,lr = base\_lr×batch\_size/256)
-
首先是不同架构下与原baseline之间的差距和别的label regularzation方法和别的self-distillation之间的区别,常规实验对比

-
和别的ensembel distillation方法之间的对比
-
和别的label refinery方法之间的对比
-
Transfer learning下游任务上目标检测结果
-
鲁棒性测量实验结果
-
每类数据采样方法的实验,这个实验很重要,因为它证明了BAKE方法效果好的原因还是在于knowledge ensemble而不是采样方法,因为可以看到在正常情况下采用这种采样方法反而会使效果下降,可能是因为这导致了同一个batch内多样性下降,而且也并不是同一batch内相同样本越多越好
-
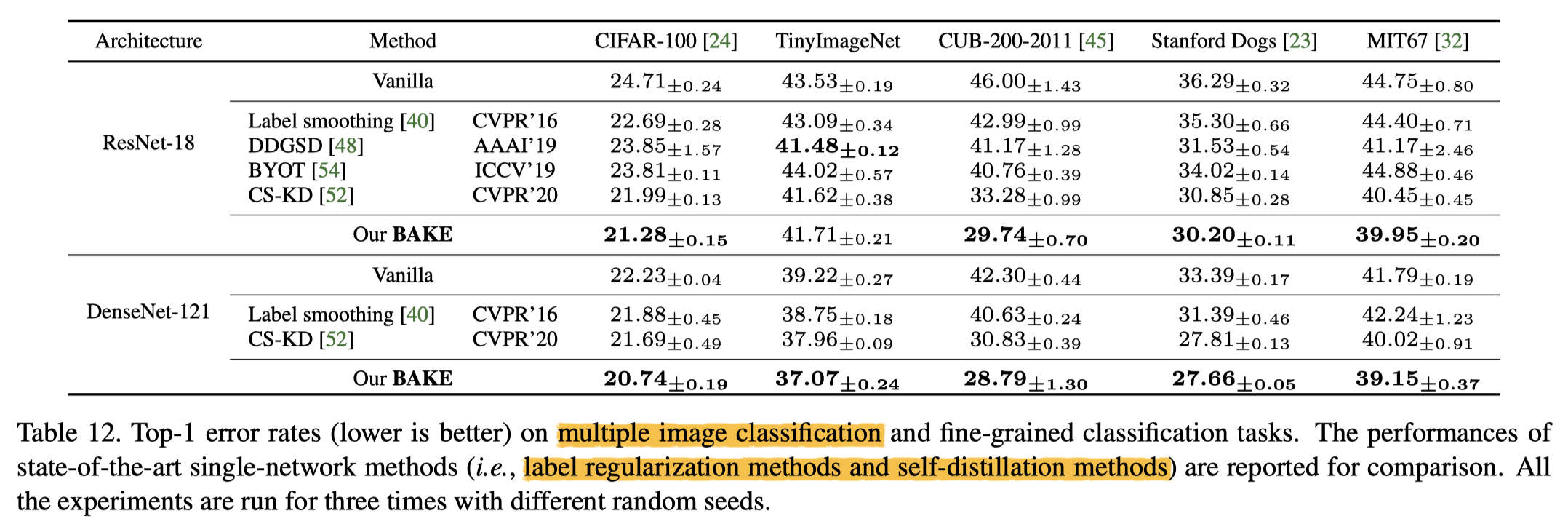
小数据集上的实验结果
Conclusion
- 一种全新的batch knowledge ensemble方法,为自蒸馏生成了refined soft target,不过这也是建立在一定的采样方法基础之上的,虽然该方法还挺有意思的,但受限于这个条件显得就没有那么厉害了,因为蒸馏中利用batch之内样本的相似性来作文章真的挺多了,但这个工作是用来生成新的logit,所以我个人感觉还是挺有意思的,而且这篇文章的算法过程描述的非常清楚了很容易就懂。但目前还并不知道这篇文章中了没有,其实其对比的自蒸馏方法还是相对来说比较少的,不知道最后结果如何,感谢作者的工作给我带来的启发。