刚刚入门model compression领域,这一篇文章比较经典为 ICLR2018 Oral,为Densenet作者所作
paper:https://arxiv.org/abs/1703.09844
code:https://github.com/gaohuang/MSDNet
pytorch版code:https://github.com/kalviny/MSDNet-PyTorch

Introuction
本文的核心主旨在于:在计算资源限制下对不同的图像进行不同的处理,可以理解成对于简单样本采用简单的方式处理,对于复杂样本则尽可能给其分配资源,以避免不必要的资源浪费节省计算量,并且在这种推理的思想上要实现网络对数据的自动适应。所以本文设计了一个新颖的二维多尺度网络结构,根据不同的资源需求训练了多个分类器,为了最大程度地重用分类器之间的计算,我们将它们作为早期出口并入单个深度卷积神经网络,并通过密集连接将它们互连,该构架在整个网络中同时保持粗略和精细的scale,获得了良好的效果。
这样的网络结构在至少这两种关于计算资源的设定下是有有效的,这两种settings也是本文的核心:
- anytime prediction 指的是可以使网络在任何给定的时间内给出预测结果,一个实际应用的例子在于对于手机而言,由于每一个手机的性能不同计算资源不同,为所有的手机训练不同的网络肯定是不可能的,你肯定想要的是设计一个单独的网络可以在所有设备上最大化使用效果。在这里每一个手机就代表的是每一个单个的样本,虽然该方法虽然名字上是时间,但它只是以时间为参照给出每个设备所需要的资源限制条件,所给出的限制仍然是budget,关键在于每一个样本产生限制。相当于对于输入模型的每一张图像都根据计算资源的限制来给出预测结果。
- budgeted batch prediction 指的是对于一个batch中的众多样本来说,共用一个固定的资源限制,可以自适应的在这一个batch中让简单样本使用少一些的资源,让复杂样本使用多一些的资源。例如对于大型公司所需要处理的大量数据来说,如果能再简单样本上节省一点点的时间 对于之后的总体计算花费来说都是划算的。在这样的一个batch中,如果计算资源总限制为B,这个batch中包含M个样本数据,简单样本所分的资源应该小于B/M,复杂样本应该大于B/M
在设计CNN网络架构的过程中,遇到了这样的两个问题:
- 关于特征的提取,直接放进分类器的都是最后一层的特征,前面所提取的特征并没有放进分类器,而且每一层提取不同的特征取决于所在的层数,如何把分类器放进去是一个问题
- 网络中不同层的特征具有不同的scale,前面的几层operate on a fine scale以提取low-level特征,后面的层通过池化或跨步卷积(strided convolution)变成coarse scale,让全部的内容进入分类器,这就说明不同层所提取出的特征具有较大差异希望在前面的几层中也可以有后面的coarse scale。
使用了一系列的中间分类器,问题的解决方案:
- 通过密集连接dense connectivity解决了分类器的内部表示形式,所有的层与所有的分类器相连接,特征不再由早期出口所决定,而且前期和后期分类器之间的权衡可以作为损失函数很好的进行。
- 第二个问题在于早期层缺乏corase scale所提取到的特征,引入了多尺度的网络结构解决,也就是multi-scale,在每一层我们都产生所有scale的特征,有利于分类也有利于提取低层次特征,只有在经过多层处理后才有用。
关于这两个问题后面的部分会进一步详细说明,这也是文章的核心
Network
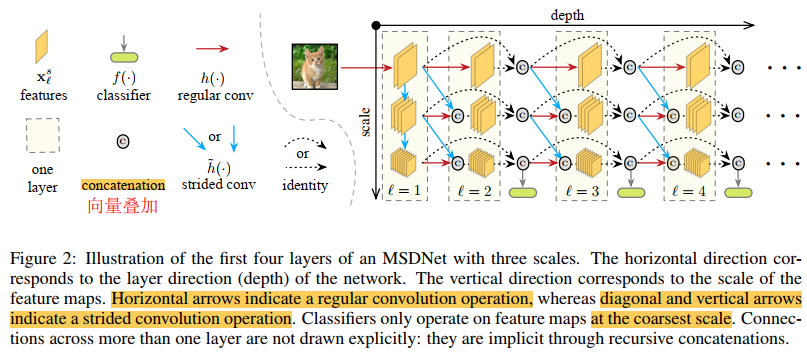
图为MSDNet整体结构,具体细节在下文中会进行介绍,每一列代表一层,每一行代表一个scale。
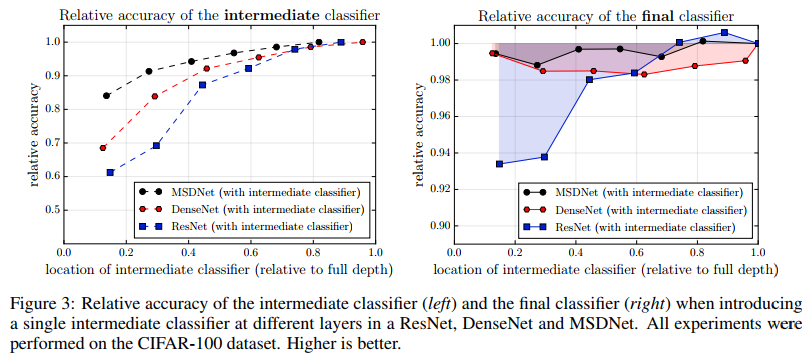
中间的早期分类器会损害神经网络性能的原因有两个:
问题:缺乏corase-level特征 传统神经网络在前几层学习fine scale的特征,通过重复卷积池化跨步卷积等在后面的层中学习corase scale的特征,corase scale features对于整个图片的分类至关重要,早期的层缺乏此类特征所以早期退出的分类器可能会错误率较高。Figure 3左图DeseNet和ResNet显示了相关的实验结果,分类器的准确性与其在网络中的位置高度相关。 特别是在ResNet(蓝线)的情况下,比较明显。
解决:Multi-scale features maps 让所有的分类器仅使用coarse-level features,在特定层的feature map 通过concatenate一个或两个卷积来进行计算,包括两种情况:一是对于将常规卷积应用于前一层的相同scale特征上的结果(Figure2中水平连接)二是对于前一层对fine-sale的特征图应用跨步卷积的结果(Figure2中对角线连接)。水平连接可保留和处理高分辨率信息,这有助于在以后的图层中构造高质量的corase features。 垂直连接在整个过程中都会产生corase features,可以进行分类。 图3中的黑色虚线显示MSDNet大大提高了早期分类器的准确性。
问题:早期分类器干扰最后的分类器 Figure 3右图说明了分类器放置位置对于最后分类器的影响,事实说明蓝色曲线可以看出对于ResNet中间分类器着实影响了最后的分类器,我们假设ResNet中的这种准确性下降可能是由于中间分类器影响了针对短期而非最终层进行优化的早期功能。 这提高了立即分类器的准确性,但折叠了在后续层中生成高质量特征所需的信息。 当第一个分类器附加到较早的层时,此效果会更加明显。
解决:密集连接 Dense Connectivity将每一层与所有后续层连接起来,并允许后续层绕过针对短期优化的特征,以保持最终分类器的高精度。 如果较早的层折叠了信息以生成short-term features,则可以通过直接连接到其上一层来恢复丢失的信息。 最终分类器的性能(或多或少)与中间分类器的位置无关。 据我们所知,这是第一篇发现密集连接是深度网络中早期退出分类器的重要元素的论文,我们将其作为MSDNet中不可或缺的设计选择。
Architecture
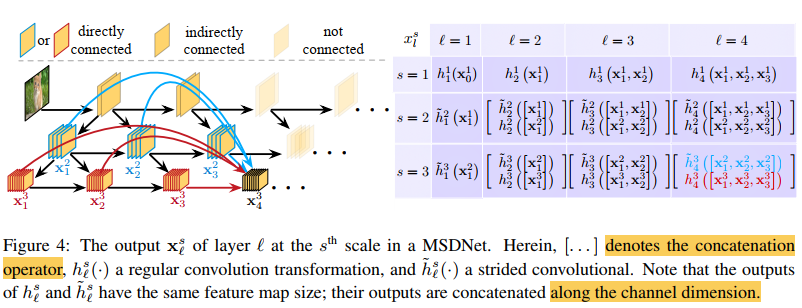
该图为网络架构的3D结构,更明显的看出普通卷积 跨步卷积 concatentation操作等
第一层 第一层唯一之处在于它包括垂直连接,主要目的是找到所有S个scale上的表示形式,可以将其垂直的布局视为一个微型的S层卷积网络,例如图中为S=3,coarse scales的特征图是通过下采样的方式所得到。
后续层 后续层所生成的feature map为所有之前scale s和s-1的feaure maps的结合
分类器 MSDNet中的分类器遵循最coarse scale的密集连接模式,l层的分类器利用之前所有的层在scale S上的特征,每个分类器包括两个卷积层然后是一个平均池化层和一个线性层,在实验中我们仅将分类器附加到某些中间层,利用fk表示第k个分类器,在anytime的设置中我们通过网络传播送输入直到预算用尽输出最近的一个预测,在budgeted设置中,一个样本在网络中遍历在某一个分类器置信度超过一个阈值后退出。在训练前,我们计算处理网络到第k个分类器所需要的计算成本Ck,我们用q表示一个固定的退出概率,即到达分类器的样本有足够的置信度退出分类,我们假设q在所有层都是一个常量,我们就可以计算每个分类器退出的概率记为qk,要保证在每一个分类器退出的概率之和为1,在测试时我们还需要保证所有的样本的开销不超过我们的总budget B,这样我们就解决好了q的约束,并且决定了在每一个分类器退出的阈值
Loss Function 每个分类器都采用了cross entropy loss,并且最小化了一个加权累计loss,如果提前预知了buget的分布P(B),我们可以用权重将我们对预算B的先验知识加入学习中, 根据经验,我们发现对所有损失函数使用相同的权重在实践中效果很好。
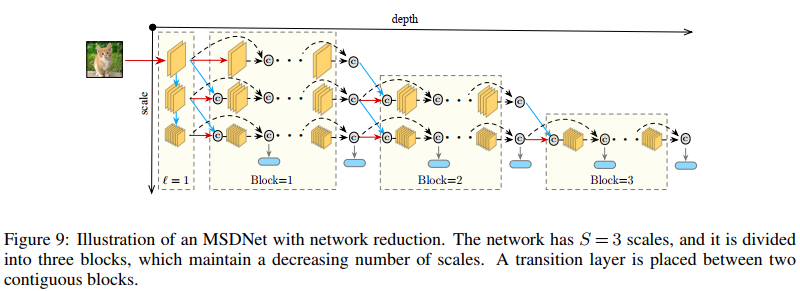
Network reduction and lazy evalution 有两种直接可以减少计算需求的方法。首先,在最后几层的时候还保留着所有的fine scale是没有必要的,一个简单的策略就是通过在深度上划分成S个blocks以减小网络的大小,在第i个block中只保留最coarse的S-i+1个scale,如Figure9所示,这样在训练和测试中均可以降低计算。每次移除一个scale时,我们在两个block中添加一个transition层,该层在通过strided convolution将fine-scale feature输入到coraser scale前利用1x1卷积concatenat特征并且将channel切割为原来的一半,这一步有点像DenseNet-BC。第二,由于l层的分类器仅使用最coarse scale上的特征,l层上较为fine的feature map和先前S-2层中一些较精细的特征图不会影响分类器的预测,因此,我们将计算group在“对角线块”中,以便我们仅沿着评估下一个分类器所需的路径传播样本。 当我们由于计算预算用尽而需要停止时,这将不必要的计算减到最少。我们将此策略称为懒惰评估。
Experiments
在三个数据集上进行了实验 分别是CIFAR-10,CIFAR-100,ImageNet ILSVRC2012
Datasets 两个cifar数据集包括训练集50000张图测试集10000张图,均为32x32,用5000张训练图像作为验证集,分别包括10和100类,遵循何凯明ResNet将标准的数据增强技术应用于训练图像,图像的每边zero-padding 4 pixels,然后随机裁剪以生成32×32图像。 图像以0.5的概率水平翻转,并通过减去通道平均值并除以通道标准偏差进行归一化。 ImageNet数据集包括1000类,总共有120万张训练集和50,000个验证集。我们从训练集中拿出50,000张图像,以估计MSDNet中分类器的置信度阈值。 在训练时我们采用何恺明ResNet的数据扩充方案,在测试时,我们对尺寸为256×256像素的224×224中心图像进行分类。
Training Details 在两个CIFAR数据集上都用最小batch64的随机梯度下降进行训练,使用Nesterov动量,我们使用Nesterov动量,其动量权重为0.9而无衰减,权重衰减为10−4 。 对所有模型进行了300个epoch的训练,初始学习率为0.1,在150和225个时期后将其除以10。 我们将相同的优化方案应用于ImageNet数据集,但将最小批处理大小增加到256,并且所有模型都训练了90个epoch,学习率在30和60个时期后下降。
anytime prediction
在anytime的预测设置中,该模型都将在所有类别上保持逐步更新的分布,并且可以强制该模型在任意时间输出其最新的预测。我们发现,在我们范围内的任何计算预算下,MSDNet的性能都大大优于ResNets MC和DenseNets MC(MC代表多个分类器)。这是由于这样的事实,即MSDNet仅经过了几层,就生成了比ResNets或DenseNets早期层中的高分辨率特征图更适合分类的低分辨率特征图。尽管在预算很小的情况下,MSDNet的表现与整体ensemble相当,但它几乎在所有计算预算方面都优于其他基准。在预算极低的情况下,ensemble具有优势,因为它们的预测是由第一个(小型)网络执行的,该网络专门针对低预算进行了优化。但是,随着预算的增加,ensemble的准确性提高的速度几乎没有提高。一旦ensemble需要评估第二个模型,MSDNet的性能便会超越它,因为与MSDNet不同的在于,它需要重复计算相似的low-level features,实验结果如下图所示:
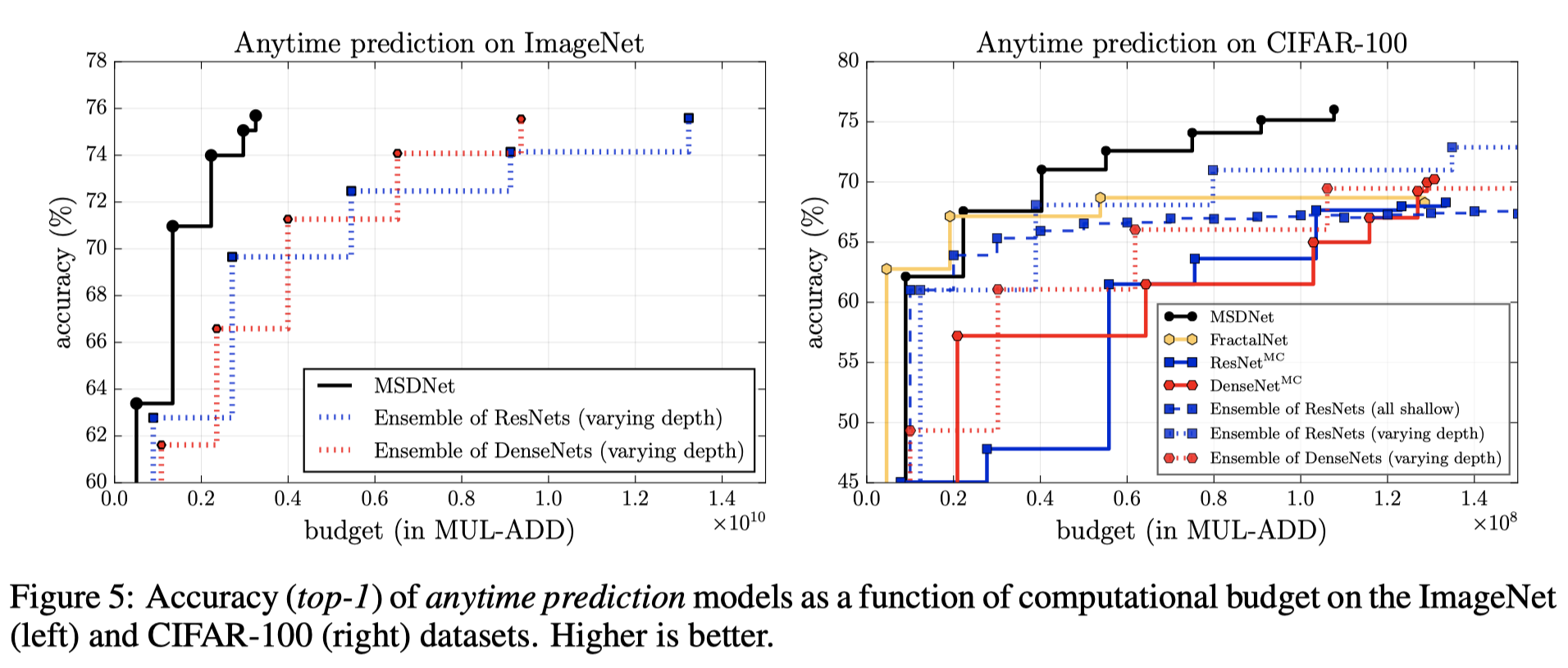
budgeted batch classification
在budgeted batch设置中,预测模型接收一批M个实例和用于对所有M实例进行分类的计算预算B。 在这种情况下,我们使用动态评估:在早期分类器上尽早退出“简单”示例,同时在整个网络中传播“困难”示例。根据在验证集上的准确性为每个预算选择最佳模型,如图所示:
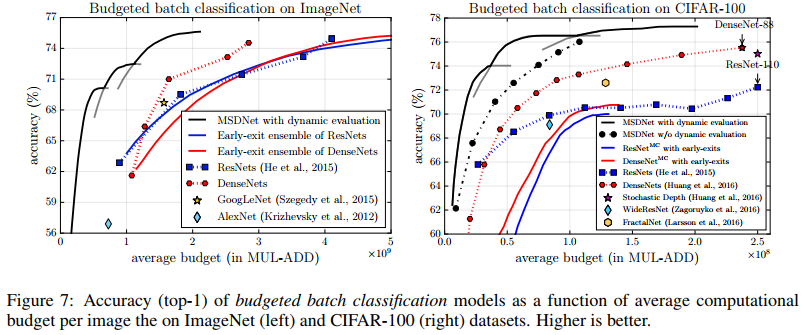
Details
我们在CIFAR数据集上使用具有3个scale的MSDNet,并应用了network reduction。Figure 9给出了简化网络的示意图。 卷积层在第一层中起作用,表示3×3卷积(Conv),批处理归一化(BN)和ReLU激活的序列。 在跨步卷积的计算中,通过使用跨度为2的幂的卷积进行卷积来执行下采样。对于后续的特征层,普通卷积和跨步卷积的转变是根据DenseNets中的设计定义的:Conv(1×1)-BN-ReLU-Conv(3×3)-BN-ReLU。我们将三个scale的输出通道数分别设置为6、12和24。 每个分类器都有两个下采样卷积层和128维3×3滤波器,然后是2×2平均池化层和线性层。
用于ImageNet的MSDNet具有4个scale,分别在每个图层上生成16、32、64和64个特征图。 network reduction也用于减少计算成本。 在进入MSDNet的第一层之前,首先通过7×7卷积和3×3最大池化(均具有步幅2)对原始图像进行转换。 分类器具有与CIFAR数据集相同的结构,除了每个卷积层的输出通道数设置为等于其输入通道数。
Network architecture for anytime prediction 在anytime设置下MSDNet有24层,分类器对于第2*(i+1)的输出进行处理,对于ImageNet,MSDNet具有4个scale,第i个分类器对于第(k*i+3)层进行处理,其中k=4,6,7,为简单起见,所有的分类器的损失均具同样的权值。
Network architecture for budgeted batch setting 两种CIFAR数据集上的层数在10-36之间,第k个分类器附加到前k个层,用于ImageNet的MSDNet与之前anytime设置描述的MSDNet相同。
Ablation Study
对于MSDNet的三个主要组件,进行了其他实验,包括:multi-scale feature maps,dense connectivity,intermediate classifiers. 我们从具有六个中间分类器的MSDNet开始,依次删除三个主要组件。 为了使我们的比较公平,我们通过调整网络宽度(即每层输出通道的数量),使整个网络的计算成本保持相似,约为3.0×108FLOPs。 在删除MSDNet中的所有三个组件之后,我们获得了一个类似于VGG的常规卷积网络。 我们在图10的左面板中显示了模型中所有分类器的分类准确性。可以观察到以下几点:1.紧密的连接对于MSDNet的性能至关重要,并且删除它会严重损害整体准确性(橙色与黑色) 曲线); 2.消除多尺度卷积只会损害较低预算区域的准确性,这与我们的动机-多尺度设计在早期引入区分特征的动机是一致的; 3.在完全符合其评估成本的特定预算下,最终的规范CNN(星级)的性能与MSDNet类似,但不适合变化的预算约束。 与没有密集连接(橙色曲线)的模型相比,最终的CNN在其特定预算区域的性能要好得多。 这表明密集的连通性与多个分类器结合在一起特别重要。
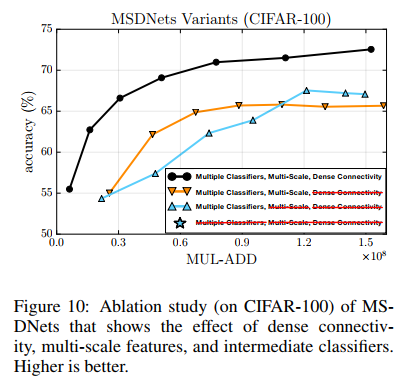
More Efficient Densenets
在这里,我们讨论探索MSDNet体系结构时的一个有趣发现。 我们发现遵循DenseNet结构来设计我们的网络,即通过在所有规模上保持输出通道数(或增长率)相同,并不能在准确性和速度之间取得最佳平衡。 主要原因是,与ResNets等网络体系结构相比,DenseNet结构倾向于在网络的高分辨率特征图上应用更多的过滤器。 这有助于减少模型中的参数数量,但与此同时,它会大大增加计算成本。 我们尝试通过在每个过渡层之后增加一倍的增长率来修改DenseNet,以便将更多过滤器应用于低分辨率特征图。 事实证明,所得的网络(我们称为DenseNet *)在计算效率方面明显优于原始的DenseNet。
我们在两个设置中以测试时间预算约束条件对DenseNet *进行了试验。 图8的左面板显示了变化深度的DenseNets *集合的随时预测性能。 它在很大程度上优于原始DenseNets的深度变化整体,但是仍然比MSDNets差一点。 在预算批处理预算设置中,在所有预算下,DenseNet *的准确性都大大高于其对应的副本,但在MSDNets方面仍然远远优于其他同类产品。
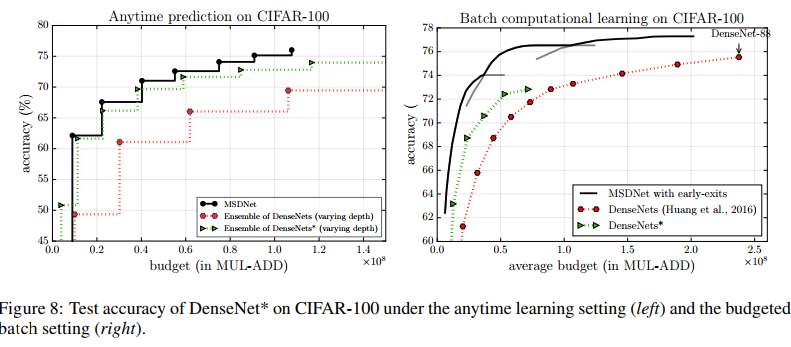
Conclusion
我们的设计基于两个高级设计原理,以生成并维护整个网络的coarse level features,并以密集的连接性互连各层。 前者允许我们甚至在早期阶段就引入中间分类器,后者确保这些分类器不会互相干扰。 最终设计是水平和垂直层的二维阵列,可将深度和feature coarseness分离。在传统的卷积网络中,feature只会随着深度的增加而变得coarser,而MSDNet会从第一层开始生成所有分辨率的功能,并始终保持这些分辨率,实验结果是架构具有前所未有的效率范围,可以在一定的计算预算范围上胜过所有竞争基准。
ps:今年CVPR ECCV均有文章是在MSDNet基础上进行的,后续会继续分享,第一次写博客,大部分时进行原文的翻译工作,在anytime和budgeted两种setting的理解值得再次推敲,而且在训练和测试两个过程分别是怎么处理的还没完全弄清,如有问题欢迎批评指正。
参考
1、http://www.voidcn.com/article/p-ewetechd-brk.html
2、https://www.cnblogs.com/RyanXing/p/MSDNet.html
3、https://blog.csdn.net/u014686356/article/details/79626471