spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算



Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Yran
Tachyon是分布式内存文件系统
Spark是核心计算引擎,能够将数据并行大规模计算
Spark Streaming是流式计算引擎,将每个数据切分成小块采用spark运算范式进行运算
Spark SQL是Spark的SQL ON Hadoop,能够用sql来对数据进行查询等功能
GraphX是图计算引擎
MLlib是机器学习库,提供聚类,分类以及推荐等基本的机器学习算法,并且社区中不断开发新的算法

Spark解决了哪些之前专有系统的局限性
重复开发,可能用使用storm来进行流式计算,有用别的框架进行机器学习
系统组合,不同系统之间数据需要约定格式
专有系统适用范围局限,storm适用于流计算,graphX适用于图计算
资源分配与管理,每个系统都有各自的资源管理,不方便协调




弹性分布式数据集RDD:分布式数组,将整个数据切分成不同的块,然后存到不同的节点通过一个统一的元数据RDD进行管理
partition,存储所有数据块的列表
compute函数,支持不同的RDD完成不同的运算(在不同节点上对这些数据块进行不同的运算)
dependencies维持每次RDD的顺序,比如一部分数据首先要进行去重,然后排序,分组,每次一运算数据都要用到上一次RDD的结果,这就需要dependencies来进行管理
partitioner,重新分区,
preferredLocations,优先读取本地数据

transformations,转换数据



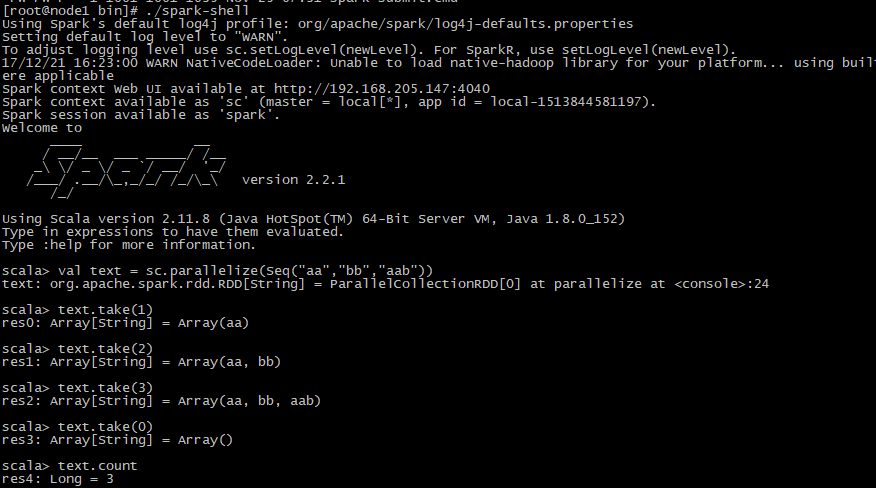
编写程序实例:
进入spark官网,下载并解压spark程序包,此处用最新的:


解压之后在IDE中新建Scala项目,此处使用IntelliJ作为IDE:
new一个project并选择Scala,然后选择object:

讲Spark中jar文件下的jar包全部导入project:
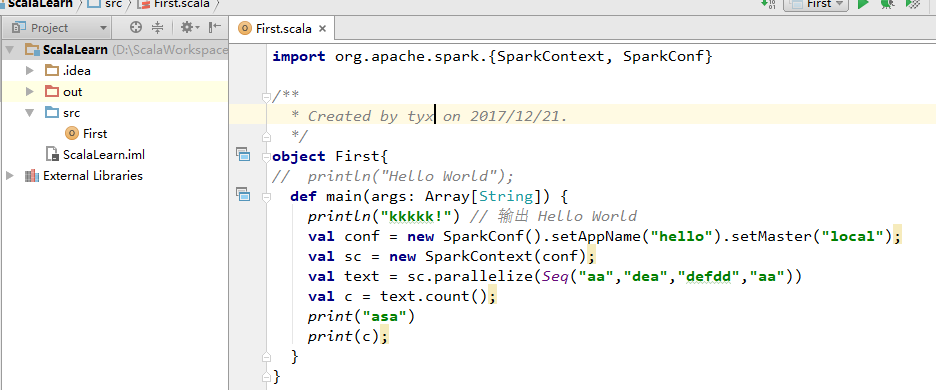
编写如上代码运行,先建立连接spark实例,然后命名,之后选择地址,目前用本地环境
之后编写数据,用parallelize将数据写入RDD,然后可以开始统计count,或者take数据等操作
还可以在服务器上用spark-shell执行代码,还是先解压下载好的scala包,然后进入bin目录,执行./spark-shell,由于是内环境操作,不需要实例化链接,然后与上述操作一样: