%tensorflow_version 2.x import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from tensorflow import initializers as init from tensorflow import losses from tensorflow.keras import optimizers from tensorflow import data as tfdata #1.生成数据 num_inputs = 2#数据有两个特征 num_examples = 1000#共有1000条数据 true_w = [2, -3.4]#两个特征的权重 true_b = 4.2#偏置 features = tf.random.normal(shape=(num_examples, num_inputs), stddev=1)#随机生成一个1000*2的矩阵,每行代表一条数据 labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b#计算y值 labels += tf.random.normal(labels.shape, stddev=0.01)#加上一个偏差 #2.组合数据 batch_size = 10 # 将训练数据的特征和标签组合 dataset = tfdata.Dataset.from_tensor_slices((features, labels))#按第0维进行切分,和标签组合 # 随机读取小批量 dataset = dataset.shuffle(buffer_size=num_examples)#随机打乱1000 dataset = dataset.batch(batch_size) data_iter = iter(dataset)#生成一个迭代器
输出一个batch看一下:
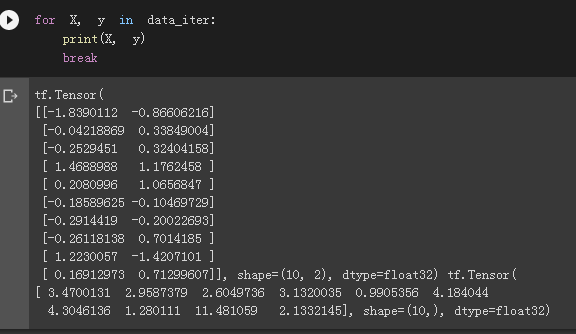
这里是其中一个batch,它包含10条原数据。
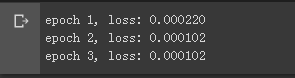
model = keras.Sequential()#定义模型 model.add(layers.Dense(1, kernel_initializer=init.RandomNormal(stddev=0.01)))#定义网络层 loss = losses.MeanSquaredError()#定义损失 trainer = optimizers.SGD(learning_rate=0.03)#定义优化器为随机梯度下降 loss_history = [] num_epochs = 3 for epoch in range(1, num_epochs + 1):#全体数据循环三次 for (batch, (X, y)) in enumerate(dataset):#对每一个batch循环 with tf.GradientTape() as tape:#定义梯度 l = loss(model(X, training=True), y) loss_history.append(l.numpy().mean())#记录该batch的损失 grads = tape.gradient(l, model.trainable_variables)#tape.gradient找到变量的梯度 trainer.apply_gradients(zip(grads, model.trainable_variables))#更新权重 l = loss(model(features), labels)#遍历完一次全体数据后的损失 print('epoch %d, loss: %f' % (epoch, l))
因为我们要求循环所有数据3次,而每一次循环都是小批量循环,每个小批量里都有10条数据,所以首先写出两个for循环,最里层的循环是每次循环10条数据。
我们通过调用tensorflow.GradientTape记录动态图梯度,之前定义的损失函数是均方误差,需要真实值和模型值,于是把model(X)和y输入loss里。
我们可以记录每个batch的损失,添加到loss_history中。
通过 model.trainable_variables 找到需要更新的变量,并用 trainer.apply_gradients 更新权重,完成一步训练。
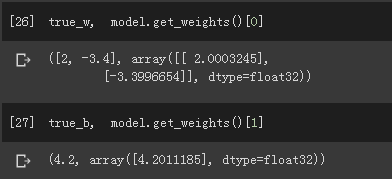
查看训练出来的参数和原参数的对比: