本文主要讲统计分词。
中文预处理的一个重要的环节就是对语料进行分词,将一句话或者一个段落拆分成许多独立个体的词,然后方便向量化,接着进行TF-IDF的特征处理。
在英语中,单词本身就是“词”,而在汉语中,“词”以“字”为基本单位,文章的语义表达仍然以“词”来划分,所以在处理中文文本时,需要进行分词处理,将句子转换为“词”的表示,这个切分词语的过程就是中文分词。
现在已有的分词算法大体可以分为:
- 规则分词:通过维护一个足够大的词典,这个词典中存储了很多的词条,然后计算机会与这些已经存在的词条进行匹配,匹配到一个就完成一个分词。主要有正向最大匹配法(MM),逆向最大匹配法(RMM),双向最大匹配法(BMM)
- 基于理解的分词方法:其做法就是让计算机尽可能模拟人类对于句子的理解,在分词的时候让计算机做到句法分析,语义分析,但是因为汉语言的庞杂以及多变性,这种分词方法并没有那么成熟。
- 统计分词:主要思想是把每个词看作是由词的最小单位的各个字组成的,如果相连的两个字在不同的文本中出现的次数越多,就表示这两个字很有可能构成一个词,因此就利用字与字相邻出现的频率来反应成词的可靠性。这种做法是给出大量的已分好词的文本,然后利用机器学习此文本的分词方式和方法,训练相应的分词模型,从而达到对未知文本的分词,这里就用到了统计学习算法,比如隐马尔可夫HMM,条件随机场CRF。
一、jieba引入
jieba分词是分词的一种工具,镜像下载方法如下:
打开anaconda prompt,输入pip,再输入pip install jieba -i https://pypi.douban.com/simple/即可安装成功。
接下来先看jieba分词的三种分词模式:精确模式,全模式,搜索引擎模式:
 全模式和搜索引擎模式会把分词的所有可能都打印出来,一般情况使用精确模式就可以了,在某些模糊匹配场景中,使用全模式和搜索引擎模式,代码如下:
全模式和搜索引擎模式会把分词的所有可能都打印出来,一般情况使用精确模式就可以了,在某些模糊匹配场景中,使用全模式和搜索引擎模式,代码如下:
import jieba sent="中文分词是文本处理不可缺少的一步!" seg_list=jieba.cut(sent,cut_all=True) print('全模式:','/'.join(seg_list))
import jieba sent="中文分词是文本处理不可缺少的一步!" seg_list=jieba.cut(sent,cut_all=False) print('精确模式:','/'.join(seg_list))
import jieba sent="中文分词是文本处理不可缺少的一步!" seg_list=jieba.cut(sent) print('默认精确模式:','/'.join(seg_list))
import jieba sent="中文分词是文本处理不可缺少的一步!" seg_list=jieba.cut_for_search(sent) print('搜索引擎模式:','/'.join(seg_list))
初学到这里的时候我在想,既然jieba分词这么好,那好像没有去研究它的必要了,只要会调库,就算是会分词了?这个问题留在这、
在运行代码的时候发现,代码的名字不能命名为“jieba”,否则就会出现“AttributeError: module 'jieba' has no attribute 'cut'”的报错。o(╯□╰)o
- jieba.cut : 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
- jieba.cut_for_search : 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
- jieba.cut 以及 jieba.cut_for_search :返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut 以及jieba.lcut_for_search 直接返回 list
二、添加新词/加载自定义词典
当我们在进行分词的时候可能会有一些新的词语,而这些词语分词器没有进行对应的训练,那么就可能导致分词有误。
例如:
import jieba sent="我不是药神很好看" seg_list=jieba.cut(sent,cut_all=False) print('精确模式:','/'.join(seg_list))
输出结果为:
“我不是药神”应该是一个词,那我们添加它,在网上搜索的时候找到两种添加方法,还未查明两种方法的区别,但是这两种方法适合词较少,可以手动添加的情况,比如对于医学大类的主题文本就不适合这样一行一行的添加:
- jieba.add_word("我是词")
- jieba.suggest_freq("我是词",True)
import jieba sent="我不是药神很好看" jieba.add_word("我不是药神") seg_list=jieba.cut(sent,cut_all=False) print('精确模式:','/'.join(seg_list))
import jieba sent="我不是药神很好看" jieba.suggest_freq("我不是药神", True) seg_list=jieba.cut(sent,cut_all=False) print('精确模式:','/'.join(seg_list))
这两种方式得到的输出结果都为: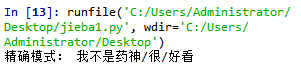
如果是某一专业领域的文本,可在网上寻找用户自定义词典,代码如下:
# 加载用户自定义字典 jieba.load_userdict('./source/user_dict.utf8')
三、停用词
有时候我们需要对新闻进行高频词提取,将其作为热词,发现舆论的焦点。高频词指的是文档中出现频率高且非无用的词语,在一定程度上代表了文章的焦点。但是诸如“的”,“了”也是文章中经常出现的词,它们对我们提取高频词产生了干扰且无用,无意义,称为停用词。
有时候并不出于做高频词提取的目的,而我们分词后的下一步常常要做的就是向量化,进行文本分析的时候不需要这些停用词,要想办法去除。
所以出于上述两种停用词的使用目的,下述代码也有两种方式:
①对于TF-IDF,我们只需要告诉组件停用词库,它将自己载入词库并使用它,具体代码为:
import jieba.analyse jieba.analyse.set_stop_words("C:/Users/Administrator/Desktop/stop_words/stop_words.txt")
这里要注意,对于txt文件是用‘utf-8’来解码的,所以还要注意下载的停用词表的存储方式,即:
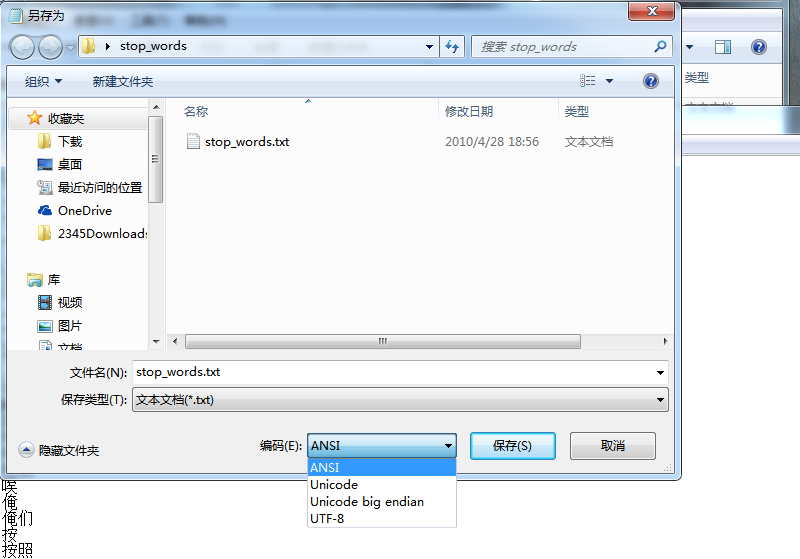
这里编码方式需要选择UTF-8,否则会出现如下报错:
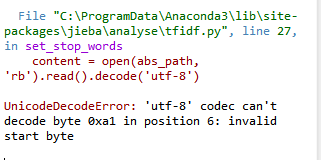
②除了上一种涉及到tfidf的载入停用词表的方式,还有如下方式,主要是将停用词表输入到代码中为一个列表;然后对分词结果进行筛选,如果分词不在停用词表中且不是换行符,就将词和一个空格输出:
import jieba.analyse
stpwrd_dic = open("C:/Users/Administrator/Desktop/stop_words/stop_words.txt", encoding='UTF-8')
stpwrd_content = stpwrd_dic.read()
stpwrdlst = stpwrd_content.splitlines()
content="沙瑞金赞叹易学习的胸怀了,是金山的百姓有福,可是这件事对李达康的触动很大。易学习又回忆起他们三人分开的前一晚,大家一起喝酒话别,易学习被降职到道口县当县长,王大路下海经商,李达康连连赔礼道歉,觉得对不起大家,他最对不起的是王大路,就和易学习一起给王大路凑了5万块钱,王大路自己东挪西撮了5万块,开始下海经商。没想到后来王大路竟然做得风生水起。沙瑞金觉得他们三人,在困难时期还能以沫相助,很不容易。"
tent=jieba.cut(content,cut_all=False)
stp=' '
for words in tent:
if words not in stpwrdlst:
if words!=' ':
stp+=words
stp+=' '
print(stp)
使用停用词表后的代码结果为:
可以看到,一些标点符号和停用词被去除了,这里还是要注意一下编码的问题,即open时需要encoding='UTF-8',否则会报错。
四、原理浅析
jieba分词结合了基于规则和基于统计两类方法:
首先,基于前缀词典进行词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG),前缀词典就是词典中的词是按照前缀包含的顺序排列。
比如这句话‘天使兰超温柔’

jieba 在其源码中有一个 dict.txt 文件,基于这个文件生成一个 trie 树,将需要进行分词的句子生成有向无环图 (DAG),通俗来说就是将需要分词的句子对照已有的 trie 树生成几种可能的区分。像上图,就是一个DAG,它的划分结果是‘天 使 兰 超 温 柔’,jieba基于前缀词典可以快速构建包含全部可能分词结果的有向无环图,上图分词结果只是其中的一条分词路径,‘有向’是指全部的路径都起始于第一个字,止于最后一个字,无环是指节点之间不构成闭环。
然后,采用动态规划查找最大概率路径,找出基于词频的最大切分组合,并将其作为最终的分词结果:
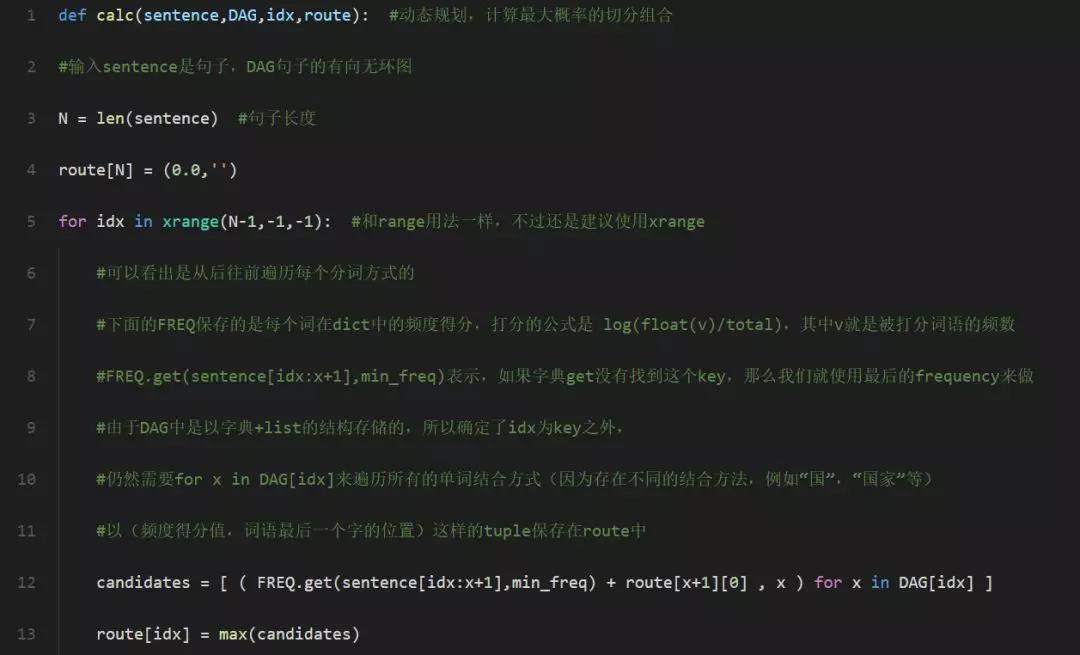
最后,基于未登录词,使用基于汉字成词的hmm模型,采用维特比算法进行推导:
未登陆词指的是在dict.txt里面没有被记录的词,值得注意的是当我们把dict.txt中的词语全部删除,jieba依然能够进行分词,但是分出来的词大部分长度都为2,其实这个时候使用的就是HMM来进行分词了。
我们可以将中文的词汇按照B(begin–开始的位置)E(end–结束的位置)M(middle–中间的位置)S(singgle–单独成词的位置,没有前也没有后)排列成一个序列,jieba中就是以这种形式来标记中文的词语,举个例子:“深圳”这个词语可以被标记为BE,也就是深/B圳/E,其意义是深是开始的位置,圳是结束的位置,复杂一些的词语“值得关注”会被标记为BMME,也就是开始,中间,中间,结束。
在jieba中对语料进行了训练从而得到了三个概率表,通过训练得到了概率表再加上viterbi算法就可以得到一个概率最大的BEMS序列, 按照B打头, E结尾的方式, 对待分词的句子重新组合, 就得到了分词结果。
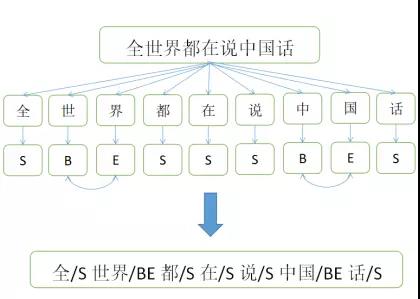
例如我们有一个待分词的句子“全世界都在学中国话”,这句话可以得到一个BEMS序列 [S,B,E,S,S,S,B,E,S](注意这个序列是一个假设,不一定正确),接下来我们将序列中的BE放在一起得到一个词,单独的S独立出来,那么我们就可以得到这样的一个分词结果“全/S 世界/BE 都/S 在/S 学/S 中国/BE 话/S”这样我们就得到了一个较为准确的分词结果。