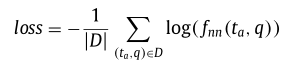发表期刊:Neurocomputing(2019) Harbin Institute of Technology
论文连接:https://www.sciencedirect.com/science/article/pii/S0925231218312219
摘要
论文重点关注基于内容的表检索,给定一个查询,任务是从一组表中找到最相关的表。在该任务的研究中,如果想要取得好的结果需要一个强大的语义匹配模型和更丰富的训练和评估预料。为了解决这一问题,论文提出了一种基于排名的方法,通过对查询语句特征的提取和神经网络结构的结合来计算查询和表内容之间的相关性。
介绍
给定一个查询,任务是从一组表中找到最相关的表。
表格检索对自认语言处理和信息检索都非常重要。
表格检索面临着多个挑战:
1. 如何有效地表示一个表,一个表通常是结构化或半结构化的,包括标题、字段、单元格等信息。
2. 第二个挑战是如何构建一个模型来度量非结构自然语言和表之间的相关性。因为查询和表的形式不同,所以表的检索可以看作是一个多模态任务
3. 据论文研究调查说明,目前没有一个公开可用的数据集用于表检索。
论文方法
论文提出的方法分为两个级联步骤,以权衡准确性和效率。
一、首先使用基本相似性度量找到若干个候选表
二、然后对候选表进一步计算与查询之间的相关性
任务描述
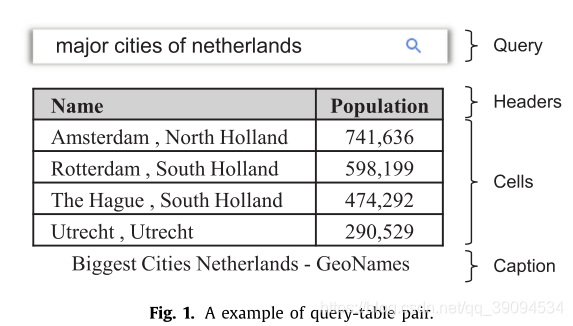
给定一个查询(q)和一组表格(T={t_1,...,t_N}),表搜索的模板就是找到与(q)最相关的表(t_i). 通常(q)是自然语言表达,例如("major cities of netherlands “)。表(表t_i)被定义为由三部分组成:(t={headers, cells, caption})。 一个表可以有多个字段,每个字段指示一列的属性。
方法介绍
候选表检索
候选表检索的目的是从整个大规模的集中得到一个小的候选集。
选择候选集时,论文使用BM25算法来计算查询和表格之间的相似度
bm25
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法,一句话概况其主要思想:对Query进行语素解析,生成语素(q_i),即(Q=q_1, q_2, ..., q_n);然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
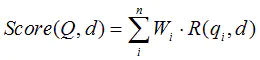
其中,Q表示Query,(q_i)表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素(q_i);d表示一个搜索结果文档;(W_i)表示语素(q_i)的权重;(R(q_i, d))表示语素(q_i)与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
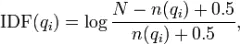
其中,(N)为索引中的全部文档数,(n(q_i))为包含了qi的文档数。根据IDF的定义可以看出,对于给定的文档集合,包含了(q_i)的文档数越多,(q_i)的权重则越低。也就是说,当很多文档都包含了(q_i)时,(q_i)的区分度就不高,因此使用(q_i)来判断相关性时的重要度就较低。
我们再来看语素(q_i)与文档d的相关性得分(R(q_i, d))。首先来看BM25中相关性得分的一般形式:
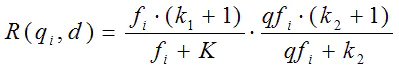
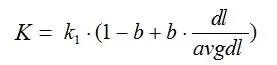
其中,(k_1),(k_2),(b)为调节因子,通常根据经验设置,一般(k_1=2),(b=0.75);(f_i)为(q_i)在(d)中的出现频率,(qf_i)为(q_i)在Query中的出现频率。(dl)为文档(d)的长度,(avgdl)为所有文档的平均长度。由于绝大部分情况下,(q_i)在Query中只会出现一次,即(qf_i=1),因此公式可以简化为:
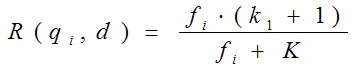
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含(q_i)的机会越大,因此,同等(f_i)的情况下,长文档与(q_i)的相关性应该比短文档与(q_i)的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
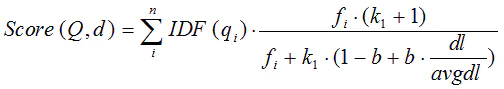
特征提取
论文设计了一组特征,分别从单词级,短语级和句子级和表格进行匹配。一个特征函数输入一个字符串(q)和(t_a)
单词级别
论文设计了两个单词匹配特征(f_wmt)和(f_wmq),(f_wmt)和(f_wmq)是根据(q)和(t_a)的字数进行计算的。
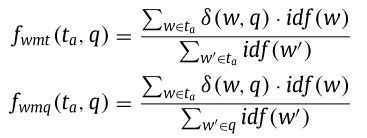
其中(idf(w))表示单词(w)在(t_a)中的逆文档频率。如果(y_j)出现在(q)中,则(delta(y_j, q))是等于1的指示函数,否则为0。(f_wmt())和(f_wmq())值越大则对应(t_a)和(q)之间有较多的单词重叠量。
短语级别
论文设计了一个(f_pp)来处理一个查询和一个表使用不用的解释来描述相同含义的情况。论文使用了统计翻译SMT来学习一个与领域无关的释义模型.
论文中短语表使用四个级联进行表示(PT={<src_i, trg_i, p(trg_i|src_i), p(src_i|trg_i)>});这里的(src_i)和(trg_i)分别表示(q)和(t_a)的短语。(p(trg_i|src_i))表示从(trg_i)翻译到(src_i)的概率。论文使用SMT来得到PT的结果。
短语特征表示如下所示,其中N为N-gram(论文中设置为3)的大小;(src^{t_a}_{i,n})和(src^{q}_{j,n}), 分别表示(t_a)和(q)从第(i-th)和(j-th)开始长度为n的单词短语:
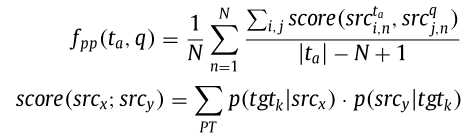
句子级别
论文使用了已成功应用于文本检索的CDSSM [24]。CDSSM的基本计算组件是子词,这使得它非常适合处理网络搜索中的拼写错误查询。该模型通过进化神经网络由子词嵌入组成句子向量。我们使用相同的模型架构来获取查询向量和表方面向量,并用余弦函数计算它们的相关性。
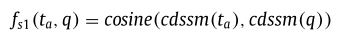
基于神经网络的特征
表格有不同类型的信息,包括标题、单元格和标题。我们开发了不同的机制来匹配查询和表的每个方面之间的相关性. 表格的一个重要性质是,随机交换两行或两列不会改变表格的意义.因此,匹配模型应该确保交换行或列将导致相同的输出。
论问使用了GRU网络来编码一个查询(q),得到查询的向量表示(v_q).
为了满足上述的条件,论文将每个header表示为一个嵌入向量,并将一组header嵌入视为外部存储器(M_h∈R^{k ×d}),其中(d)是字嵌入的维数,(k)是header单元的数量。给定一个查询向量(v_q),模型首先给每个存储单元(m_i)一个概率(α_i),在这种情况下是一个header嵌入。
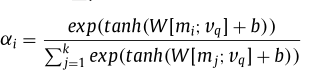
我们将(v_q)和(v_header)的连接馈送到一个线性层,后跟一个softmax函数,其输出长度为2。
论文将第一个类别的输出视为查询和标题之间的相关性:
用(NN_1())来表示这个模型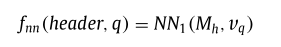
由于标题和单元格具有相似的特征,论文使用相似的方法来度量查询和可用单元格之间的相关性。
从表格单元中导出三个存储器(M_{cel})、(M_{row})和(M_{col}),以便从单元级、行级和列级进行匹配。
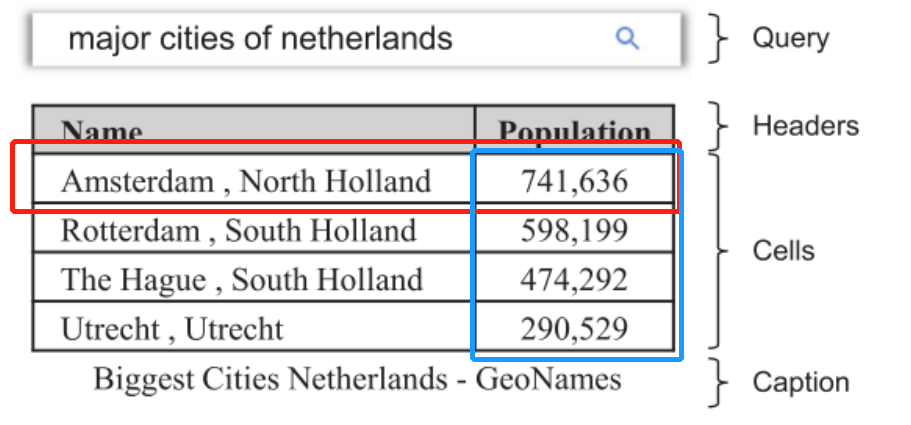
单元格中的每个存储单元代表一个表格单元的嵌入。(M_{row})中的每个单元格代表一行中的向量,该向量是通过对同一行中单元格的嵌入进行加权平均来计算的;以类似的方式导出列存储器(M_{col})
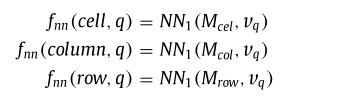
对于表格的标题,采用相同的方法
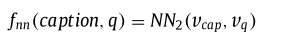
最后论文使用负对数似然作为损失函数