摘要
论文研究果蝇的大脑细胞发现,它们在接受外界多种感知后会产生一个稀疏的高维输入来表示这些信息。论文中使用该网络来学习词汇的语义表示任务,并且可以生成静态的和上下文相关的词汇嵌入。与使用密集表示的传统方法(如BERT、GloVe)不同,论文的算法以稀疏二进制哈希码的形式编码单词的语义及其上下文。使用词相似度分析,词义消歧和文档分类的任务来评价该表现形式的质量。结果表明,果蝇网络主题不仅可以达到与现有自然语言处理方法相当的性能,而且,它的训练时间更短、内存占用更小。
果蝇对感觉信息的处理
磨菇体是果蝇大脑中负责处理感觉信息的主要区域。
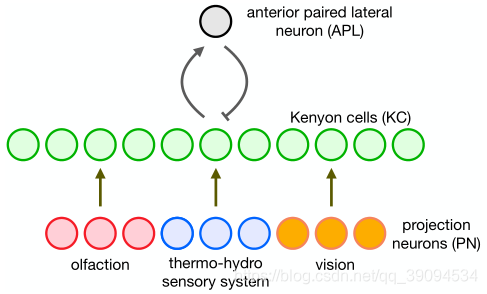
投射神经元包括对嗅觉、温度湿度感知以及视觉的感知输入。这些感官信息通过一组突触权重转发给KCs,KCs层通过与APL神经元的交互连接而被抑制,这种循环网络有效地实现了KCs之间的“胜者全得”竞争,使除一小部分顶部激活的神经元之外的所有神经元沉默。
该网络可以认为是帮助实现聚类感官刺激,相似的刺激在KCs水平上引起相似的神经反应模式,而不同的刺激导致不同的神经反应
传统的词向量表示方法
现有的词向量表示方法,如word2vec、GloVe,以及BERT等。所有这些方法都利用单个单词与其上下文之间的关联来学习有效的词嵌入。
论文提出问题:能否使用果蝇的生物网络结构来实现从原始文本中提取单词和上下文之间的关联?
相互抑制KCs的循环网络可以用作“生物”模型,在NLP任务中,论文使用随机投影的KC网络想法,为投影神经元层处的输入数据生成稀疏二进制哈希码。从PN层投射到KCs层的随机权值矩阵可以使生成的哈希码具有局部性。
论文的贡献
- 受果蝇网络的启发,论文提出了一种算法,生成单词及其上下文联系的二进制单词嵌入。同时论文对该算法在单词相似度任务、词义消歧和文档分类方面进行了其性能的实验分析。
- 证明了与连续GloVe嵌入相比,二值嵌入产生了更紧密和更好的分类簇。
- 二值化的聚类特性。论文证明,以相对较小的分类精度下降为代价,训练果蝇网络需要比训练经典的自然语言处理体系结构(如BERT)用的时间更短。
什么是GloVe?
因为论文中与GloVe词嵌入做了比较,所以这里概述一下什么GloVe。
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计的词表征工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。通过对向量的运算,比如欧几里得距离或者余弦相似度,可以计算出两个单词之间的语义相似性。
论文中词表示的方法
考虑一个训练语料库。每个句子都可以分解成连续单词的w-gram集合。
现有大小为(N_{voc})的预定义词汇表,则算法的输入是大小为(2N_{voc})的向量。
这个向量由两个块组成:上下文和目标, 论文假设(w)为奇数,目标词为w-gram的中心,如下图(蓝色部分表示w-grams,这里stock为中心词,上下问是Apple和rises)。

前(N_{voc})维表示该单词在上下文中是否出现,后(N_{voc})维表示中心词。
窗口w沿文本语料库滑动,对每个位置生成一个训练向量(V^{A}=left { {v^{A}_{i}}
ight }^{2N_{voc}}_{i=1}),其中(A)表示不同的w-grams,(i)表示上下文目标向量中的位置。
这些训练向量被传递给学习算法,该算法的目标是学习上下文和目标块之间的相关性。
到这里论文就的得到了对输入文本的词向量表示,然后论文对(V^{A}=left { {v^{A}_{i}}
ight }^{2N_{voc}}_{i=1})做了一个K-means聚类。
这里论文将(V^{A}=left { {v^{A}_{i}}
ight }^{2N_{voc}}_{i=1})和词在语料库中出现的概率作为了PN层的输入,也就是说PN层有(2N_{voc})个神经元,然后进行K-means聚类后,PN层连接的下一层KCs层具有K个神经元。
神经元的激活状态
论文对(V^{A}=left { {v^{A}_{i}}
ight }^{2N_{voc}}_{i=1})进行了BioHashing,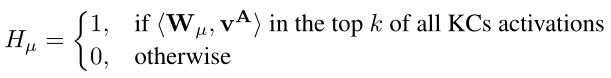
这里表示,对于输入(V^{A}=left { {v^{A}_{i}}
ight }^{2N_{voc}}_{i=1})向量,算法将其与距离最近的前K个簇表示为1,其他的表示为0。对应的KCs层对应簇的神经元将被激活,其他的神经元保持静息状态,进而得到输出的二进制哈希编码。