一、Zookeeper是什么 (安装的是3.4.7)
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现。它提供了简单原始的功能,分布式应用可以基于它实现更高级 的服务, 比如分布式同步, 配置管理, 集群管理, 命名空间,队列管理。它被设计为易于编程,使用
文件系统目录树作为数据模型。服务端跑在 java 上,提供 java 和 C 的客户端 API
众所周知,协调服务非常容易出错,但是却很难恢复正常,例如,协调服务很容易处于 竞态以至于出现死锁。我们设计 ZooKeeper 的目的是为了减轻分布式应用程序所承担的协 调任务
官网地址: http://zookeeper.apache.org/
官网快速开始地址: http://zookeeper.apache.org/doc/trunk/zookeeperStarted.html
官网 API 地址: http://zookeeper.apache.org/doc/r3.4.6/api/index.html
二、zookeeper提供了什么
1、文件系统
Zookeeper 的命名空间就是 Zookeeper 应用的文件系统,它和 linux 的文件系统很像,也是树 状,这样就可以确定每个路径都是唯一的,对于命名空间的操作必须都是绝对路径操作。与 linux 文件系统不同的是,linux 文件系统有目录和文件的区别,而 Zookeeper 统一叫做 znode,
一个 znode 节点可以包含子 znode,同时也可以包含数据。
所以总结说来, znode 即是文件夹又是文件的概念,所以在 zookeeper 这里面就不叫文件文 件也不叫文件夹,叫 znode,每个 znode 有唯一的路径标识,既能存储数据,也能创建子 znode。
但是 znode 只适合存储非常小量的数据,不能超过 1M,最好小于 1K。

下面关于znode的介绍:
(1) Znode 有两种类型:
短暂( ephemeral)(断开连接自己删除) (例如:mysql连接,插入一条数据,如果连接断开,插入数据消失)
持久( persistent)(断开连接不删除) (相反)
短暂性znode下不能创建子节点,持久可以
(2)Znode 有四种形式的目录节点(默认是 persistent ) (两种短暂,两种持久)
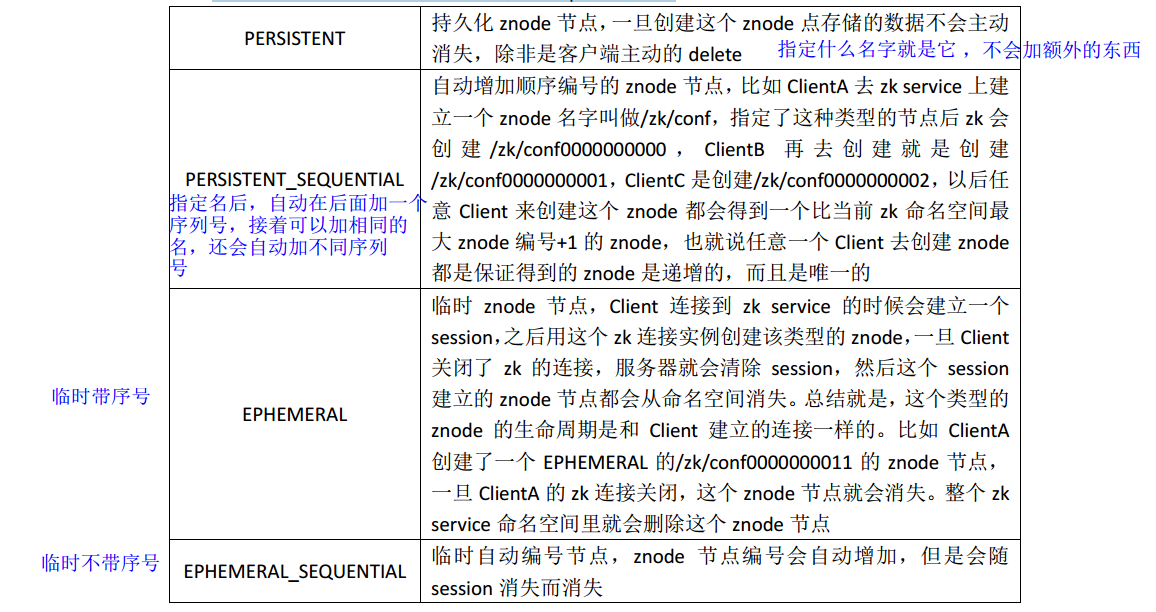
(3)创建 znode 时设置顺序标识, znode 名称后会附加一个值,顺序号是一个单调递增的计 数器,由父节点维护
(4)在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过 顺序号推断事件的顺序
(5)EPHEMERAL 类型的节点不能有子节点
(6)客户端可以在 znode 上设置监听器
2、监听机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点 增加删除)时, zookeeper 会通知客户端。 监听机制保证 zookeeper 保存的任何的数据的任 何改变都能快速的响应到监听了该节点的应用程序
监听器的工作机制,其实是在客户端会专门创建一个监听线程,在本机的一个端口上等待 zk 集群发送过来事件

3、zookeeper典型应用场景
(1)命名服务
分布式应用中,通常需要一套完备的命令机制,既能产生唯一的标识,又方便人识别和记忆。 我们知道,每个 ZNode 都可以由其路径唯一标识,路径本身也比较简洁直观,另外 ZNode 上还可以存储少量数据,这些都是实现统一的 NameService 的基础
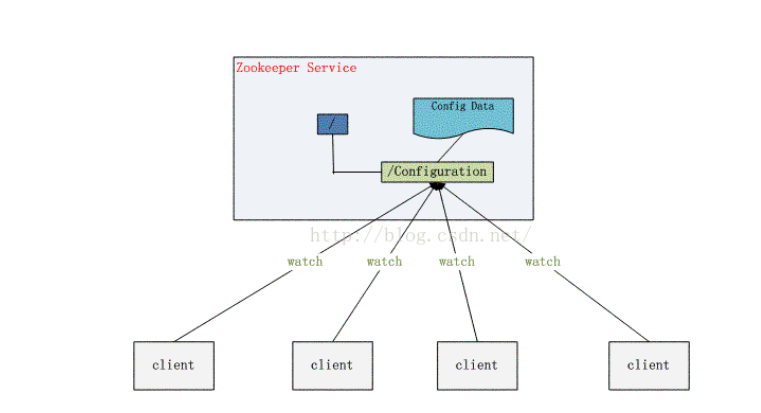
(2)配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在 把这些配置全部放到 zookeeper 上去,保存在 Zookeeper 的某个目录节点中,然后所有相关 应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到
Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好
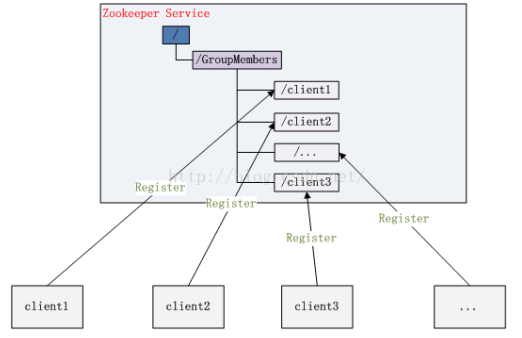
(3)集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举 master。
对于第一点,所有机器约定在父目录 GroupMembers 下创建临时目录节点,然后监听父目录 节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper 的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:
有兄弟挂了。新机器加入也是类似,所有机器收到通知:新兄弟目录加入, 又多了个新兄弟。
对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小 的机器作为 master 就好
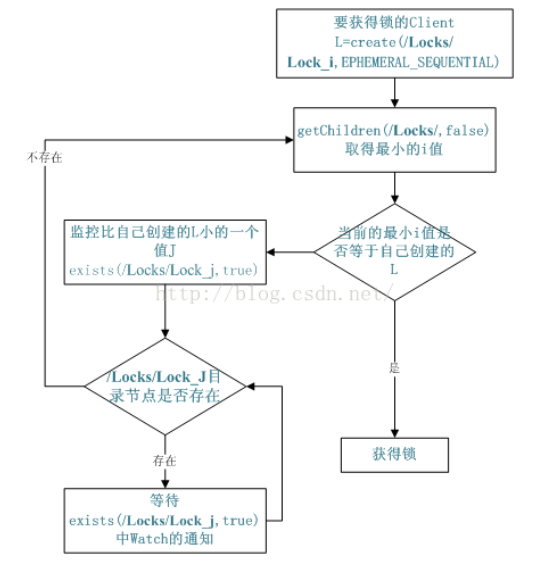
(4)分布式锁
有了 zookeeper 的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持 独占,另一个是控制时序。
对于第一类,我们将 zookeeper 上的一个 znode 看作是一把锁,通过 createznode 的方式来 实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了 这把锁。用完删除掉自己创建的 distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录 节点,和选 master 一样,编号最小的获得锁,用完删除,依次有序。
(5)队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。

三、zookeeper特点、设计目的
1、 最终一致性: client 不论连接到哪个 Server,展示给它都是同一个视图,这是 zookeeper 最重要的性能。 (节点数最好为是奇数 )
2、 可靠性:具有简单、健壮、良好的性能,如果消息 m 被到一台服务器接受,那么它将被 所有的服务器接受。
3、实时性: Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者 服务器失效的信息。但由于网络延时等原因, Zookeeper 不能保证两个客户端能同时得 到刚更新的数据,如果需要最新数据,应该在读数据之前调用 sync()接口。(同步的一个方法)
4、 等待无关( wait-free):慢的或者失效的 client 不得干预快速的 client 的请求,使得每个 client 都能有效的等待。
5、 原子性:更新只能成功或者失败,没有中间状态。 ( 如果更新数据时有一个节点失败了,怎结果不会有的成功 ,有的失败)
6、 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消 息 a 后被同一个发送者发布, a 必将排在 b 前面。