一 . 索引介绍
为什么要有索引:一般的应用系统,读写比列在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易的问题,查询语句的优化显然是重中之重,说起加速查询,就要提到索引了!
索引在MySQL中也叫“键”或者“key”(primary key unique key,还有一个index key),是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响越发重要,减少io次数,加速查询。索引优化应该是对查询性能优化最有效的手段了,索引能轻易将查询性能提高号几个数量级,索引相当于字典的音序表。
一旦为表创建了索引,以后的查询最好先查索引,再根据索引定位的结果去找数据。索引是应用程序设计和开发的一个重要方面,若索引太多,应用程序的性能可能会收到影响。
索引的影响:1.在表中有大量数据的前提下,创建索引速度会很慢,2.在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低。
索引的本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
二 . 索引的数据结构
索引的数据结构跟树是差不多的,树根到树枝在到树叶,见下图:
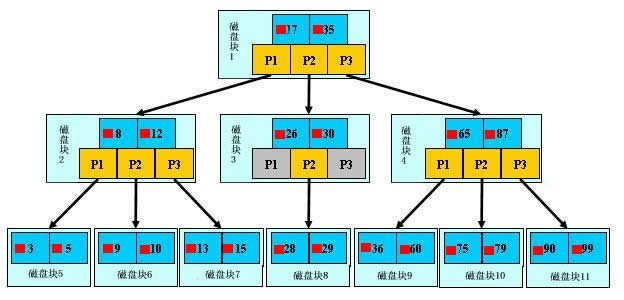
索引的两个特性:1.索引字段要尽量的小 2.索引的最左匹配特性。
三 . 聚集索引与辅助索引
1.在数据库中,B+树的高度一般都在2~4层,也就是说查找某一个键值的行记录时最多只需要2到4次IO,一般的机械硬盘每秒至少可以左100次IO,2~4次的IO意味着查询事件只需要0.02~0.04秒。
数据库中B+树索引可以分为聚集索引和辅助索引,聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息。
聚集索引的好处之一:它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
聚集索引的好处之二:范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可
2.辅助索引:简单来说就是帮助,辅助你来索引的,举例来说,如果在一棵高度为3的辅助索引树种查找数据,那需要对这个辅助索引树遍历3次找到指定主键,如果聚集索引树的高度同样为3,那么还需要对聚集索引树进行3次查找,最终找到一个完整的行数据所在的页,因此一共需要6次逻辑IO访问才能得到最终的一个数据页。
四 . mysql 索引管理
1. 索引的功能就是快速查找,看看mysql常用的索引
普通索引INDEX:加速查找
唯一索引:
-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
索引的两大类型hash与btree
#我们可以在创建上述索引的时候,为其指定索引类型,分两类
hash类型的索引:查询单条快,范围查询慢
btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
#不同的存储引擎支持的索引类型也不一样
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
2 . 创建/删除索引的语法
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
#方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
#删除索引:DROP INDEX 索引名 ON 表名字;
#方式一
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index ix_name(name) #index没有key
);
#方式二
create index ix_age on t1(age);
#方式三
alter table t1 add index ix_sex(sex);
#查看
mysql> show create table t1;
| t1 | CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL,
`name` char(1) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` enum('male','female') DEFAULT NULL,
UNIQUE KEY `uni_id` (`id`),
KEY `ix_name` (`name`),
KEY `ix_age` (`age`),
KEY `ix_sex` (`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
五 . 测试索引
准备过程:
#1. 准备表
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. 创建存储过程,实现批量插入记录
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,'egon','male',concat('egon',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
#3. 查看存储过程
show create procedure auto_insert1G
#4. 调用存储过程
call auto_insert1();
在没有索引的前提下测试数值大的查询速度是相对较慢的,因为mysql不知道有多少个等于它的数据,所以要挨个的去扫描一遍。
六 . 正确使用索引
首先,我们创建索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果,我们必须要遵循1.范围一定要明确 ,不能模糊查找的数据,否则找不到2.一定要等于,不可以大于或者小于还有不等于3.尽量选择区分度高的列作为索引
七 . 联合索引
联合索引指对表上的多个列合并起来左一个索引,省的你查询的时候,where后面的条件字段一直再变,你就想给每个字段加索引的尴尬问题
mysql> create table t(
-> a int,
-> b int,
-> primary key(a),
-> key idx_a_b(a,b)
-> );
Query OK, 0 rows affected (0.11 sec)
详情见博客:https://www.cnblogs.com/clschao/articles/10049133.html
八 . 前端CSS的简单介绍
数据库的知识也大概说完了,今天简单接触到了前端的知识,下面是我整理的内容
前端CSS定义如何显示HTML元素,给HTML设置样式,让它更加美观,当浏览器读到一个样式表,它就会按照这个样式来对文档进行格式化(渲染)。
CSS注释:/*这是注释*/
CSS的引入方式:
1.行内样式
<p style="color: red">Hello world.</p>
2.内部样式
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
p{
background-color: #2b99ff;
}
</style>
</head>
3.外部样式
<link href="mystyle.css" rel="stylesheet" type="text/css"/> #现在写的这个.css文件是和你的html是一个目录下,如果不是一个目录,href里面记得写上这个.css文件的路径