Python 解释器有一个全局解释器锁(PIL),导致每个 Python 进程中最多同时运行一个线程,因此 Python 多线程程序并不能改善程序性能,不能发挥多核系统的优势,可以通过这篇文章了解。但是多进程程序不受此影响, Python 2.6 引入了 multiprocessing 来解决这个问题。这里介绍 multiprocessing 模块下的进程,进程同步,进程间通信和进程管理四个方面的内容。 这里主要讲解多进程的典型使用,multiprocessing 的 API 几乎是完复制了 threading 的API, 因此只需花少量的时间就可以熟悉 threading 编程了。
一 起多进程
from multiprocessing import Process, current_process import time def func(i): time.sleep(2) proc = current_process() print("proce.name : ", proc.name) # 输出进程名 print("proc.pid :", proc.pid) # 输出进程ID if __name__ == "__main__": for i in range(10): p = Process(target=func, args=(i,)) p.start() # p.join() # p.join() 加上这一句之后,就是要等这个进程执行完之后才能进入下一个循环,也就是才能执行下一个进程,这样就失去了多进程的意义
二 进程中再起线程
from multiprocessing import Process, current_process import time import threading def foo(): print("threading id is ", threading.get_ident()) # 获取当前线和的ID def func(i): time.sleep(2) proc = current_process() print("proce.name : ", proc.name) # 输出进程名 print("proc.pid :", proc.pid) # 输出进程ID p = threading.Thread(target=foo, ) # 进程中再起线程 p.start() if __name__ == "__main__": for i in range(10): p = Process(target=func, args=(i,)) p.start()
三 利用os模块来查看各个进程ID
from multiprocessing import Process import os def info(title): print(title) print('module name:', __name__) print('parent process:', os.getppid()) #查看父进程ID print('process id:', os.getpid()) #查看当前进程ID print(" ") def f(name): info('called from child process function f ') print('hello', name) if __name__ == '__main__': info('main process line') p = Process(target=f, args=('bob',)) p.start() # p.join()
结果如下: 可以看到,主进程的id就是子进程的父ID

四 进程间的数据传递---queue
from multiprocessing import Process, Queue import threading def f(q): q.put([42, None, 'hello']) # 子进程中put 一个值进入Queue if __name__ == '__main__': q = Queue() q.put("test123") # 主进程中put 一个值进入Queue p = Process(target=f, args=(q,)) p.start() p.join() print("444", q.get_nowait()) print("444", q.get_nowait())
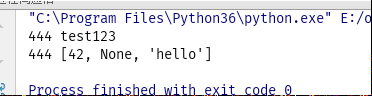
可以看到,在这个Queue中取出两个值,所以在子进程中给这个Queue传递的值,在主进程中也可以取出来.
和多线程之间数据传递(共享比较)
import threading import queue def f(): q.put([42, None, 'hello']) if __name__ == '__main__': q = queue.Queue() q.put("test123") p = threading.Thread(target=f, ) p.start() print("444", q.get_nowait()) print("444", q.get_nowait())
结果是:
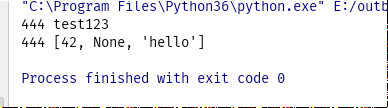
和进程数据传递比较:这里不用传递这个queue,因为线程之间数据是共享的,在多进程中,如果不传递,则在子进程中就会报未定义的错误,
不能把线程queue作为参数传给子进程
from multiprocessing import Process, Queue import threading import queue def f(q): q.put([42, None, 'hello']) if __name__ == '__main__': q = queue.Queue() q.put("test123") p = Process(target=f,args=(q,)) p.start() print("444", q.get_nowait()) print("444", q.get_nowait())
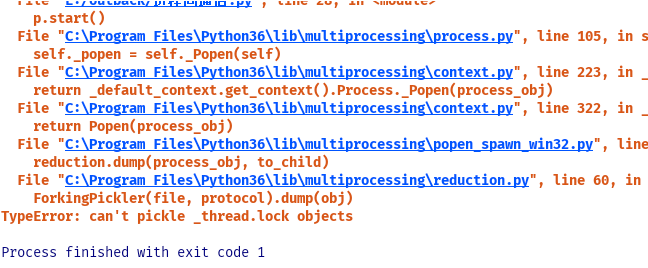
要想在进程之间传递数据,只能是进程queue,不能把线程queue作为参数传给子进程.
五 进程间的数据传递---Pipe
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello from child']) print("",conn.recv()) # prints "from main" conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() #产生两个返回对象,分别代表两头 p = Process(target=f, args=(child_conn,)) p.start() print("parent",parent_conn.recv()) # prints "[42, None, 'hello from child']" parent_conn.send("from main") p.join()
生成一个Pipe 对象后就自动生成两个返回对象,可以理解成两头,
也有两个方法 send() 发送数据 recv()接收数据.
六 进程间的数据传递---manager
from multiprocessing import Process, Manager import os def f(dct, lst): d[os.getpid()] = os.getppid() l.append(os.getpid()) # print(l) if __name__ == '__main__': with Manager() as manager: dct = manager.dict() # {} #生成一个manager的字典(不是平常的字典),可在多个进程间共享和传递. lst = manager.list(range(5)) # 生成一个列表,可在多个进程间共享和传递 p_list = [] for i in range(10): p = Process(target=f, args=(dct, lst)) p.start() p_list.append(p) for res in p_list: # 等待所有进程执行完闭结果,这里如如不写就会报错,说系统找不到指定文件 res.join() print(dct) print(lst)
结果如下:

七 进程锁
from multiprocessing import Process, Lock def f(l, i): l.acquire() #加锁 print('hello world', i) l.release() #解锁 if __name__ == '__main__': lock = Lock() for num in range(10): p=Process(target=f, args=(lock, num)) p.start() # p.join() # 加上这个之后就要当前进程执行完之后才执行下一下进程
结果如下:


from multiprocessing import Process, Lock def f(l, i): l.acquire() #加锁 print('hello world', i) l.release() #解锁 if __name__ == '__main__': lock = Lock() for num in range(10): p=Process(target=f, args=(lock, num)) p.start() p.join() # 加上这个之后就要当前进程执行完之后才执行下一下进程
结果如下

可以看到,打印的循序是固定的,而且在执行行明显知道,他是上一个进程执行完之后才执行的下一个进程.
按道理说,各进程之间数据是独立的,各进程之个对同一份内存数据是不共享的,(上面写的那几种数据共享都不是对同一份内存数据共享,只是复制了之后再共享的),不应该加锁啊,但这里各个进程是共享屏幕的,加锁的目的主要是为了防止屏幕输入输出数据出错.在python3中,进程锁的意义不大.
八 进程池
from multiprocessing import Process, Pool, freeze_support import time import os def Foo(i): time.sleep(2) print("in process", os.getpid()) return i + 100 def Bar(arg): print('-->exec done:', arg, os.getpid()) if __name__ == '__main__': # 在windows 中必须写在这个里面,不然出错 # freeze_support() pool = Pool(processes=5) # 允许进程池同时放入5个进程 print("主进程", os.getpid()) for i in range(10): pool.apply_async(func=Foo, args=(i,), callback=Bar) # callback=回调函数,是指这个进程执行完之后要执行的函数 # callback 函数是主进程调用的 # pool.apply(func=Foo, args=(i,)) #串行 # pool.apply_async(func=Foo, args=(i,)) #串行 print('end') pool.close() # 先close() 再join(), pool.join() # 进程池中进程执行完毕后再关闭,如果注释的话,当主程度执行完之后程序就关闭,而不会等各子进程执行完 # 进程池的另一种用法,这种方法不能调用callback函数 groups = [x * 20 for x in range(10)] pool = Pool(processes=5) pool.map(Foo, groups)
apply()是串行,也就是说只有等一个进程执行完才执行下一个进程,apply_async() 是并行,会按进程池中的个数一起执行,进程池的方法很多,用些方法不常用. map_async() 这是一个异常的map方法,可以调用callback()函数,用法和map一样,只是是异步执行.