一,Pandas简介
网络中对于Pandas的介绍相比是比比皆是,在此我也不想废话多说那么多理论的东西。总之一句话Pandas非常强大!!!记住非常强大,学就完了。
它能干什么。我们知道python中是没有数组的概念的,当然如果你想写一个请随意,但是我们不想重复生产轮子,别人有直接拿来用岂不乐哉。而pandas对于一维,二维数组及三维等多维数组都可以很好的驾驭。
<1> Series:
1 一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。 2 3 Time- Series:以时间为索引的Series。
<2> DataFrame:
二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。而我们的数据库(关系型数据库),Excel等表格式的结构都属于二维的。因此用DataFrame可以
很好的对二维表格式的数据进行处理。
<3> Panel :三维的数组,可以理解为DataFrame的容器。
二,Pandas的安装
因为pandas是python的第三方库所以使用前需要安装一下,直接使用pip install pandas 就会自动安装pandas以及相关组件。
如果安装不成功,请先查看是否有pip包,没有百度下载一个安装后再进行pandas包的安装。
三,Pandas读取Excel
数据:请自行把数据保存成.xlsx格式的文件
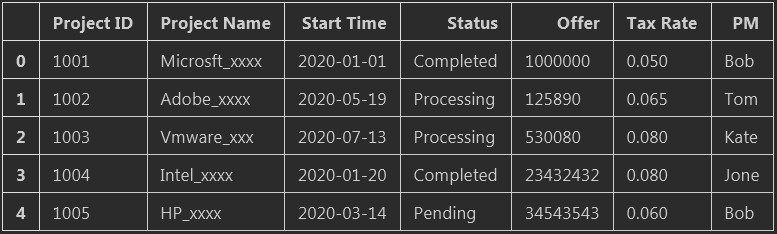
Project ID Project Name Start Time Status Offer Tax Rate PM 1001 Microsft_xxxx 2020/1/1 Completed 1000000 5.00% Bob 1002 Adobe_xxxx 2020/5/19 Processing 125890 6.50% Tom 1003 Vmware_xxx 2020/7/13 Processing 530080 8.00% Kate 1004 Intel_xxxx 2020/1/20 Completed 23432432 8.00% Jone 1005 HP_xxxx 2020/3/14 Pending 34543543 6.00% Bob 1006 Lenovo_xxxx 2020/5/30 Pending 1340324 12.50% Jone 1007 Dell_xxxx 2020/4/15 Completed 90943 10.50% Kate 1008 ALI_xxxx 2020/6/1 Processing 23423 6.00% Tony 1009 Aplle_xxxx 2020/5/18 Processing 12382132 5.00% Ken 1010 Google_xxxx 2020/7/3 Completed 147982342 12.00% Ken 1011 Amazon_xxxx 2020/7/10 Processing 23493243 17.50% Tony 1012 baidu_xxxx 2020/2/2 Completed 82432432 9.00% Bob 1013 alibaba_xxxx 2020/2/19 Processing 10023324324 8.00% Jone 1014 jingdong_xxxx 2020/1/30 Completed 234324324 10.00% Kate 1015 aiqiyi_xxxx 2020/7/13 Pending 103243243 11.00% Tom 1016 Dell_xxxx 2020/7/13 processing 782320 7.00% Kate 1017 ALI_xxxx 2020/6/20 pending 324323 5.00% Bob
1. 直接打开Excel(不传参)
解释:1. pandas的使用需要先import pandas这个包 as pd 代表起一个别名,方便调用
2. df.head() 默认显示5行数据
3. pd.read_excel()的括号中我只传入了一个excel的绝对路径,并没有给任何参数,打开一个excel远远没有这么简单。让我们一起来跟着往下看吧
注意:以下我是基于jupyter来操作的。因此在打印的时候是直接使用了df.head(). 如果您是直接使用python的情况下请加上print(df.head())
import pandas as pd
#
df = pd.read_excel(R"C:UsersAdministratorPandas_vs_Excel20200714get_need_info_from_Excel.xlsx")
# df = df.set_index("Project ID")
df.head()
2. 打开Excel ( 传参 - usecols)
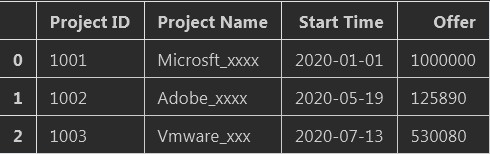
解释: usecols:读取指定的列,参数为字符串(切分),int类型及列表
下列通过字符串切分以及列表中添加int类型来演示3个案例
# 通过字符串选取想要的列
df = pd.read_excel(R"C:UsersAdministratorPandas_vs_Excel20200714get_need_info_from_Excel.xlsx",
usecols="A:C,E")
print(df)
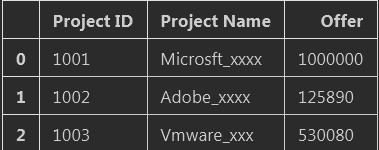
#通过int列表来选择多列,但是这种方式不支持切片
df = pd.read_excel(R"C:UsersAdministratorPandas_vs_Excel20200714get_need_info_from_Excel.xlsx",
usecols=[0,1,4]) #这里的int类型也可以换成字符串,为了可读性建议以后换成字符串。换成字符串写法:usecols=["Project ID","Project Name","Offer"]
df.head(3)
#通过lamba表达式来选取列
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderstudent_info.xlsx",
usecols=lambda x:(x=="姓名") | (x =="学号")) #这里也可以通过传入表达式的方式指定读取的列
df.head(3)
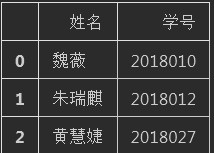
3. 打开Excel ( 传参 - header)
数据:请自行保存成.xls或者.xlsx格式的数据
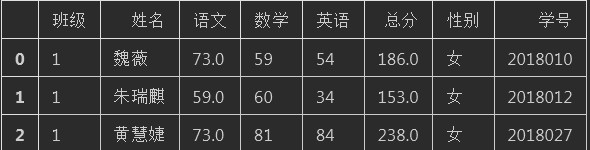
班级 姓名 语文 数学 英语 总分 性别 学号 1 魏薇 73 59 54 186 女 2018010 1 朱瑞麒 59 60 34 153 女 2018012 1 黄慧婕 73 81 84 238 女 2018027 1 张章 60 55 48 163 男 2018094 1 沈政宇 51 71 27 149 男 2018108 1 宋承泽 68 74 53 195 男 2018113 1 马彦冰 77 72 52 201 女 2018148 1 马恺 61 83 72 216 男 2018166 1 王锦程 80 96 83 259 男 2018167 1 闫瑾 74 64 64 202 女 2018196 1 王晓渝 45 12 28 85 女 2018198 1 王浩然 79 86 69 234 女 2018246 1 徐菁 54 90 60 204 女 2018256 1 唐诗涵 83 87 83 253 女 2018266 1 诸葛祥云 57 51 54 162 男 2018273 1 薛智元 62.5 22 46 130.5 男 2018278 1 廉政宇 73 74 55 202 男 2018279 1 马翔 77.5 78 72 227.5 男 2018281 1 王安琪 67 56 67 190 女 2018320 1 邵钰铭 73 91 56 220 男 2018341 1 朱昊宇 65 54 27 146 男 2018343 1 郭逸翔 68 78 62 208 女 2018379 1 马振郡 74 58 49 181 男 2018402 1 彭俊亿 67 83 48 198 男 2018408 1 曹露馨 78 95 82 255 女 2018443 1 郑顺文 70 75 73 218 男 2018456 1 许文泽 85 90 69 244 男 2018465 1 李鹏宇 49 54 47 150 男 2018516 1 韩宗祥 54 49 40 143 男 2018530 1 郁慧 68 50 36 154 女 2018562 1 麻洪轩 80 87 73 240 男 2018580 1 李镇宇 71 79 87 237 男 2018597 1 赵泓博 81 54 29 164 男 2018599 1 孙艺菲 64 59 39 162 女 2018610 1 刘家豪 85 91 95 271 男 2018655 1 王一涵 82 62 79 223 女 2018663 1 林紫凡 49 61 44 154 女 2018665 1 吴琳琳 67 40 37 144 女 2018666 1 李佳琳 74 84 75 233 女 2018680 1 王真 32.5 20 27 79.5 男 2018705 1 高侨 53.5 73 53 179.5 男 2018706 1 田峻赫 59 74 53 186 男 2018716 1 张忠庆 20 4 15 39 男 2018724 1 周星彤 52 48 34 134 女 2018727 1 王菲 80 74 76 230 女 2018742
解释: header顾名思义就是头部的意思,如果表格中含有表头而我们不希望显示表头的情况下可以按照表头所在的行指定行数跳过表头显示数据
注意: 当excel,csv或者txt文件中没有表头的情况下,一定不要忘记设置 header= None这个参数.否则会丢失第一行数据.(被作为表头)
import pandas as pd
df01 = pd.read_excel(R"C:UsersAdministratorPycharmProjectsuntitledPandas_to_Excel20200716file_folderstudent_info.xlsx",
sheet_name=0,
header=1) #如果这里把header的值设置为1那么原来的titile就会被跳过
df01.head()
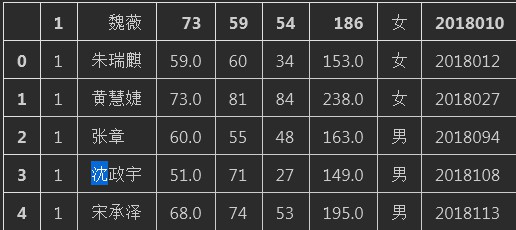
4. 打开Excel ( 传参 - sheet_name)
解释: sheet_name从字面意思上也可以看出,就是指向excel的多个sheets的。默认读取第一个sheet。如果想读取1个以上的sheets可以通过sheet_name = ["sheet1","sheet2"]这种方式读取,当然如果想一并读取excel表中所有的sheets直接指向参数为sheet_name=None即可
注意:这里特别强调一点的是,如果读取一个sheet的内容返回的是一个DataFrame二维数组,但是如果用列表或者None的方式读取多个sheets那么返回的则是一个dict字典。后续对于数据的处理清洗调用的方法不同,所以大家不要忽略这一点。
<1> 调用1个sheet
import pandas as pd
#通过int类型指定读取的sheet内容。不指定sheet_name参数默认读取第一个表.
#这里0表示读取第一个sheet中的内容
df01 = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderstudent_info.xlsx",
sheet_name=0)
df01.head(5)

<2> 调用多个sheet
提示:nrows参数可以指定读取数据的时候,最多读取数据的行数。当然不指定通过df02.head()指定也可以。另外主要注意的是print(type(df2))后它的类型是dict而不是dataframe
#通过字符串指定读取哪一个sheet中的内容
#这里我们读取sheet1和sheet2中的内容,因为是2个sheet所以需要通过list来包裹
#注意:因为我们同时读取了2个sheet中的内容,所以此时用df02.head()是无法指定读多少行的。为了实现这个功能,在读取数据时指定nrows参数来设定读取多少行
df02 = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderstudent_info.xlsx",
sheet_name=["sheet1","sheet2"],
nrows=5) #nrows代表指定读取sheet的行数
print(type(df02))
df02
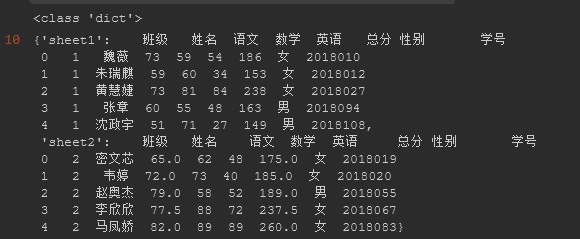
<3> 调用所有sheets
提示:我的数据其实有5个sheets,因为不方便传整个excel因此我就不一一把数据列举出来了。要想做练习的小伙伴可以自行编写几条数据来做演示
#设置sheet_name = None代表读取整个workbook中的所有sheet
df03 = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderstudent_info.xlsx",
sheet_name=None,
nrows=5) #nrows代表指定读取sheet的行数
df03
#%%
#获取sheet4中的数据
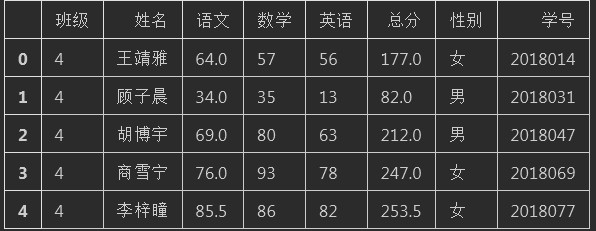
get_sheet4 = df03["sheet4"]
get_sheet4
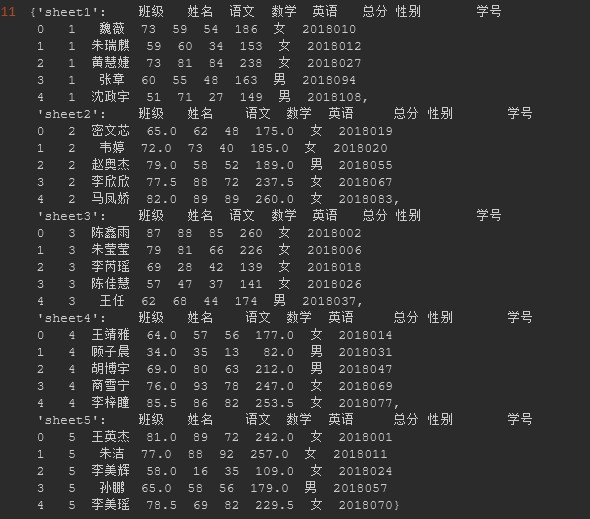
5. 打开Excel ( 传参 - names)
数据:自行保存为.xlsx的文件
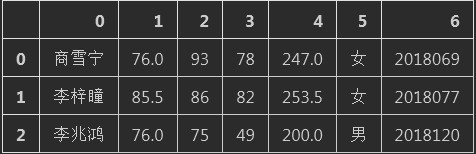
商雪宁 76 93 78 247 女 2018069 李梓瞳 85.5 86 82 253.5 女 2018077 李兆鸿 76 75 49 200 男 2018120 周诗棋 78 94 67 239 女 2018138 张利恒 58 74 64 196 男 2018172 刘若惜 55 44 45 144 女 2018192 苏永远 73 50 52 175 女 2018200 李坤璐 87 77 71 235 女 2018203 孙喆 34 59 9 102 男 2018224
解释: names参数跟sheet_names不同,它主要是面向DataFrame的而不是sheets. 作用是当一个数据读进来没有表头的时候,我们可以通过names参数给没有表头的数据设置一个表头
<1> 无表头数据读入后状态
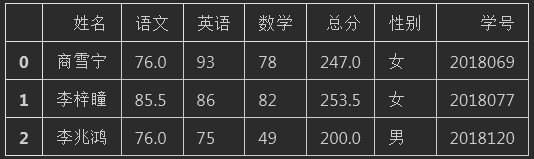
<2> 通过names参数加入表头后读取数据的状态
#通过names参数来定义列名.但是一定要指定header=None不然数据的第一行会缺失
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folder
o_names_sheet_Data.xlsx"
,header=None,
names=["姓名","语文","英语","数学","总分","性别","学号"])
df.head(3)
6. 打开Excel ( 传参 - dtype)
解释: dtype参数主要的作用是可以给当前数据的数据类型做变更(不是所有类型都可以。。。例如String类型)
例如下列数据被读取后可以通过正常的命令df.dtypes查看各个数据的类型,其中Object代表综合类型,可以理解为Str类型.但是数据类型中有单独的String类型。Str跟String在这里是不同的。
str就代表Object类型
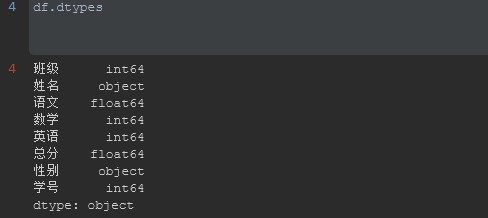
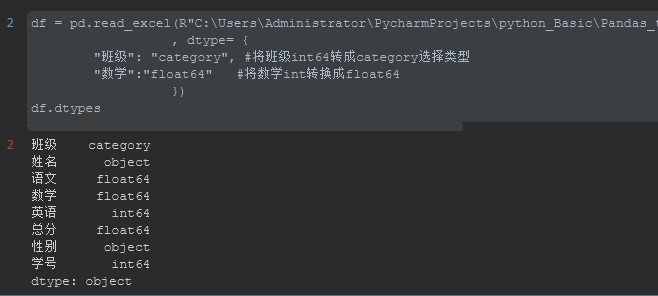
通过指定dtype={dict}的方式指定数据的类型,可以把之前的数据类型改为想要的数据类型。这么做的好处就是可以在后续处理中直接调用该类型的函数方法
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderstudent_info.xlsx"
, dtype= {
"班级": "category", #将班级int64转成category选择类型
"数学":"float64" #将数学int转换成float64
})
df.dtypes
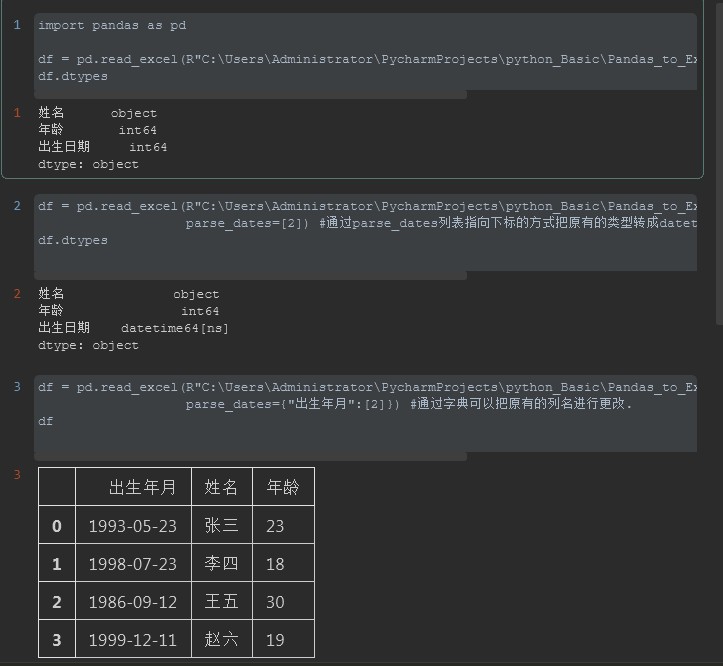
7. 打开Excel ( 传参 -parse_dates)
数据:请自行保存成.xlsx格式的文件
姓名 年龄 出生日期 张三 23 19930523 李四 18 19980723 王五 30 19860912 赵六 19 19991211
解释: parse_dates主要的作用就是把对于本来看似日期格式的数据,但是不是日期格式的数据,进行转化的功能(嗯。。。有点绕)
来解释一下,例如对于一个20200728的这样一个数据,这一看就是一个日期,但是并没有按照正常的日期格式来定义,20200728系统默认看似就是一个int类型因此定义成int类型
这不是我们想要的格式。因此可以通过parse_dates=[日期数据的索引]的方式把数据转化成日期格式的类型。如下案例所以
注意: 为了方便我直接把jupyther格式的输出贴到下方了。如果您没有用jupyther而是.py的文件打开的,请一步步的通过print()的方式输出
import pandas as pd
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderparser_datas.xlsx")
df.dtypes
#%%
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderparser_datas.xlsx",
parse_dates=[2]) #通过parse_dates列表指向下标的方式把原有的类型转成datetime64时间格式
df.dtypes
#%%
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderparser_datas.xlsx",
parse_dates={"出生年月":[2]}) #通过字典可以把原有的列名进行更改.
df
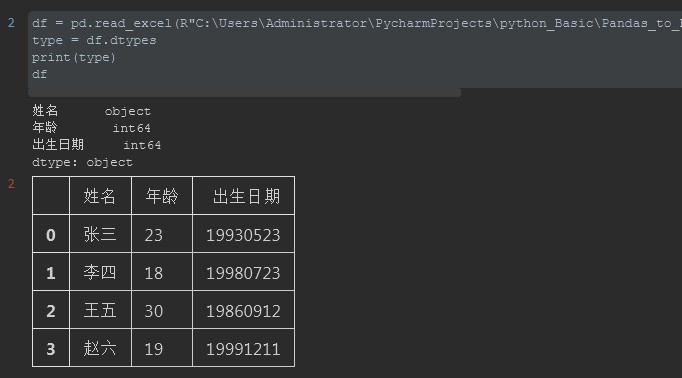
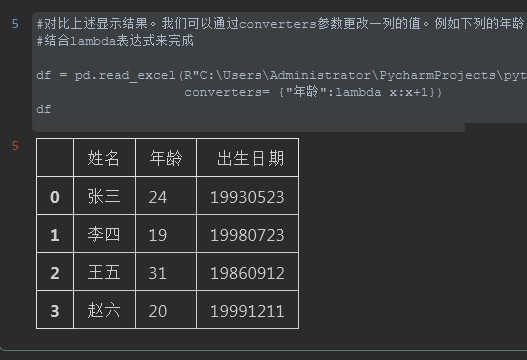
8. 打开Excel ( 传参 - converters)
解释:可以对于DataFrame的一列,也就是一个Series. 做整列的数据运算(仅限于数字)
例如我们需要把数据的一列年龄加1,如果一个个加有1万行就傻了,因此通过这个函数一步搞定
import pandas as pd #%% df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderparser_datas.xlsx") type = df.dtypes print(type) df
通过converters参数传入一个字典,key为要变更的列名,values值可以通过lambda表达式做数学运算传入值
#对比上述显示结果。我们可以通过converters参数更改一列的值。例如下列的年龄。让整列的年龄加1
#结合lambda表达式来完成
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200716file_folderparser_datas.xlsx",
converters= {"年龄":lambda x:x+1})
df
对于通过pandas如何打开一个Excel是不是感觉博大精深呀。仅仅一个打开文件就这么多的方法。当然不同情况下调用不同的参数,可以为我们后续对Excel的清洗带来很大的方便。
因此Pandas必须学。真的非常方便!对大数据及机器学习,AI领域来说pandas也是必备技能!!!
好了,对于如何对Excel进行读写及清洗,想必这才是大家真正关心的。在接下来的博文中会一一详细说明!