经历多天的努力,hadoop的环境配置已经完成,编译器也能成功连接,下一步就是开始学习框架,第一个目标为WebMagic,这应该是比较简单好上手的java爬虫框架,先把这个搞懂,再以此为基础进行下一步。
今天对WebMagic进行了初步的概念上的认识,在此做个笔记。
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,我们只需要完成逻辑的设计即可快速开发出一个高效、易维护的爬虫。
流程图:
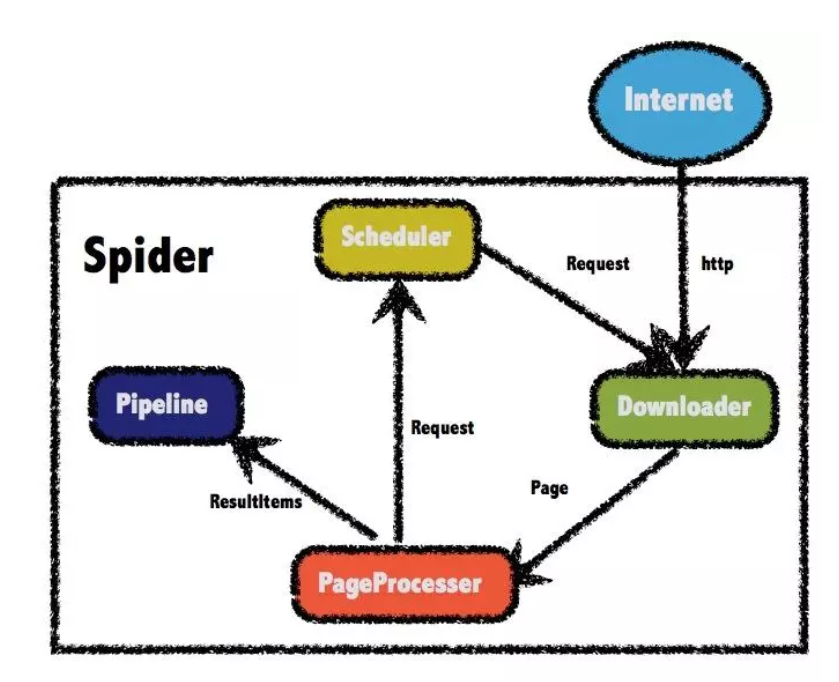
Downloader 负责从internet上下载页面,方便后续处理
PageProcesser负责解析网页和提取链接
Scheduler 负责管理待抓取的 URL 和去重。
Pipeline 负责结果数据的持久化,所谓持久化就是把数据进行贮存,保存在文件或是数据库中。