HashMap介绍
在一起看HashMap的源码之前,在这里想要先简要介绍Java8中的HashMap的大体的结构。在前面一章中,我们看到了抽象类AbstractMap中的许多操作都是基于遍历的方式来进行的,比如查找,这样的操作的效率是很低的。
HashMap中采用了哈希表的方式来提高效率,并用数组来表示这个哈希表,而初始化时为了节约内存,一般不会设置很长的数组,因此不可避免地会出现哈希冲突,即多个对象的哈希值都为同一个数值。这时,HashMap的处理方式是,数组中,每个位置并不是直接放置一个要储存的对象,而是将对象放入链表中,再将这个链表的头节点放在数组中。
因此,我们要通过键查找一个元素的过程就是,先求哈希值,找到哈希值对应的数组中的位置,得到这个位置所对应的链表的头节点,再遍历链表找到我们要找的元素。当然,这里具体来说会有很多细节,比如数组的大小设置及扩容方式,为了解决遍历链表的效率问题,会在链表长度较长时将链表转换成一棵红黑树等等,这些我们可以在看源码的时候再具体了解。
HashMap总体结构
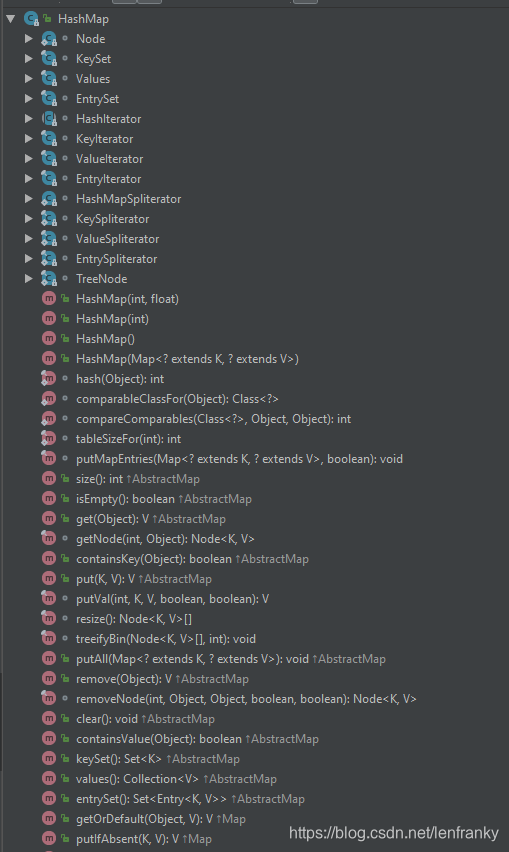
可以看到,HashMap中的内部类与方法还是很多的,这里,我们先来看看其中的内部类Node,因为这是其它很多操作的基础,了解了它才能比较清楚地去看很多方法的具体实现。
内部类Node<K, V>
首先,我们来看一下内部类Node的源码:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
首先是这个内部类的声明部分,在声明中内部类Node实现了Map中的内部的接口Entry,因此我们很容易就可以发现,这个内部类是用来实现map内部的entry的,也就是是实际的键值对的储存的数据结构。
在这个内部类中,定义了几个成员变量,分别用来记录当前entry的哈希值、键与值,这里,哈希值与键是final的,即一旦生成了这个entry,则其哈希值与所对应的键是不可以改变的,但是其值是可以改变的,这与我们印象中map的使用方法是相符的。
在这三个用来记录entry中实际数据的成员变量之后,是一个Node类型的成员变量,看到这个属性,熟悉数据结构的同学应该很快就会有所联想,特别是我们这个类的名字叫做Node,所以自然而然地会想到是不是与链表有关,答案是确实是一个链表,在Java中,HashMap中的每个键所对应的所有键值对是以链表的形式储存的,而其中的节点所用的数据结构就是现在所看的这个Node了。而具体是怎样实现的我们在后面会详细来讲。
在几个成员变量的定义之后,就是Node的构造函数了,这个构造函数也比较简单,就是把输入的参数传到内部变量上。
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
接下来,是几个存取数据的方法,这里可以注意一下,Node的哈希方法,是将键与值的哈希取一次异或,作为自身的哈希值。
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
最后,是Node类的equals()方法,首先判断参数中的对象o和自身地址是否相同,之后,再判断o是否是Map.Entry接口的实现类,若是的话,判断键与值是否分别相等,若想等,则返回true。
至此,内部类Node的源码便全部看完了。
内部类TreeNode
在上一节中,我们知道了,HashMap中,是使用Node来储存键值对,那么,在Node之外,是否外有其它数据结构储存键值对呢?确实是有的,那就是Java8中新加入的内部类TreeNode了。
既然已经有了Node了,为什么还需要另一个数据结构呢?我们知道Node是用链表的形式来储存数据的,如果想要从一个链表中找到一个确定的元素,我们只能从头开始遍历这个链表来进行查找,如果链表的长度较短,其实效率还是很高的,但是随着链表的长度的增长,效率是不断降低的,而我们对于HashMap的期待是一个高效的容器,这时,这样降低的效率是我们不希望看到的。因此,Java8中引入了红黑树来解决这个问题。
而红黑树的节点就是这一节中我们要看的TreeNode了。
我们先来看一下TreeNode的结构图:
可以看到,其中方法还是比较多的,主要是红黑树的各种操作,感兴趣的同学可以详细看一下,因为代码量比较大,可以在红黑树的专门的文章中来研究。这里我们可以一起看一下其声明的属性与构造函数:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
... ...
}
其所调用的父类LinkedHashMap.Entry的构造方法:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
... ...
}
可以看到,绕了一个圈,又回到了HashMap中,调用的是HashMap中的Node的构造方法。