分布式架构下的数据一致性,大家有这样的问题:跨系统间分布式事务如何解决?系统内多个服务的分布式事务如何解决?一个服务内的多个数据源/数据库的分布式事务如何解决?由于术语不准确,所以解释起来会有二义性,所以先要统一语言或者术语,也就是统一概念:
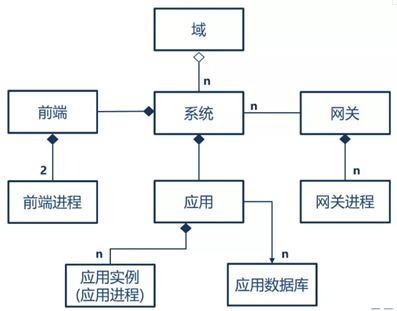
域是一个虚拟的分类,几个系统属于某一个域,例如网上银行和手机银行都属于电子渠道领域;
传统的单体应用,指的就是系统,在微服务架构下,单体应用采用前后端分离模式,前端一般使用 Nginx,Ngnix 进程间采用主备模式,系统的后端可以分为多个应用,每个应用有一组对等的应用进程(也称为应用实例)提供服务,每个应用对应一个数据库,实际上在分库的情况下,有可能一个应用对应多个数据库。复杂一点的是网关,网关由一组对等的网关实例组成,如果多个系统共享一个网关,网关和系统就是1对多的关系,也可以一个系统独享一个网关,就是一对一情况,下图是一个概念的示例,使用的是系统独享网关模式。
跨系统间分布式事务、系统内多个服务的分布式事务、一个服务内多个数据源/数据库的分布式事务,这些问题完全是从技术的角度做归纳,用上述概念应该改为:系统间的数据一致性、系统内应用间的数据一致性、应用内部对应多数据库的数据一致性,另外可以增加一个数据库对应多个应用的数据一致性(技术上存在可能,但从上述概念上看应该是在架构上避免的)。
1、系统间的数据一致性
需要服务实现 TCC或者业务补偿模式,由框架(业务协调器)自动调用,减少人工参与,或者实现幂等服务,反复投递。这两种方式都没法做到数据的 100% 一致,在失败的时候都需要有重试的机制,例如补偿失败要重试(这就是框架的好处),多次重试还是失败,记录失败历史,业务上人工处理。不要害怕人工处理,只要减少人工处理的机会就好了,在工行时就是提出人工干预比例降低若干个百分点作为目标。
2、系统内应用间的数据一致性
这个可以使用华为 SAGA 的模式,也就是建立一个共享的事务协调器模式,简单的方式是用共享的事务协调器模式,记录服务调用的事件,在合适的时机调用TCC和补偿服务。
3、应用内部对应多数据库的数据一致性,是个反模式,不要做通用方案
一般来说,一个应用对应一个数据库,不允许一个应用对应多个数据库,多个数据库的情况应该分成多个应用,通过服务调用方式解决,这是一个基本原则,否则就是一个反模式设计。就是有很多人一定问有这个情况你怎么解决,我的回答是架构设计解决这个问题,在技术上不支持这种方式,让设计者必须在架构解决,而不是利用技术手段解决不合理的架构设计,否则后患无穷。
4、一个数据库对应多个应用的数据一致性
这种情况经常也是一个反模式,既然是共享一个数据库,把应用放在一起。如果真的有需要(例如一个模块部署过于频繁,单独拆出来做一个应用),那也应该和多应用多数据库一样处理。
总结:分布式有几种一致性
强一致
当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据 CAP 理论,这种实现需要牺牲可用性。
弱一致性
系统并不保证续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。
最终一致性
弱一致性的特定形式。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。DNS 是一个典型的最终一致性系统。