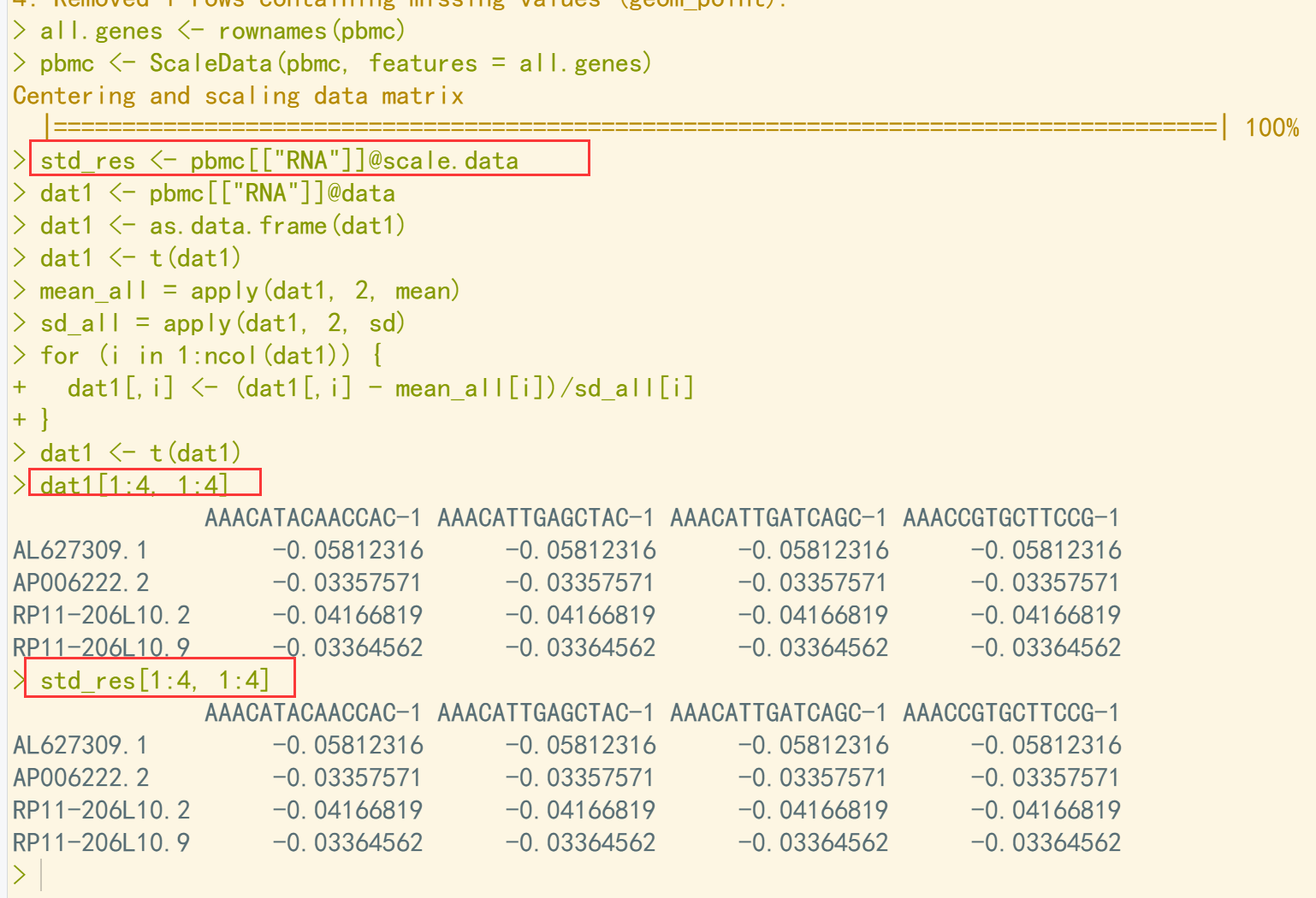
001、数据的归一化是在数据的标准化的基础上进行的,而且是按照行来进行的, 即:
(每一行的观测值 - 每一行的平均值)/每一行的标准差
验证:
a、前期步骤参考:https://www.jianshu.com/p/4f7aeae81ef1
b、
all.genes <- rownames(pbmc) pbmc <- ScaleData(pbmc, features = all.genes) std_res <- pbmc[["RNA"]]@scale.data ## 归一化标准答案 dat1 <- pbmc[["RNA"]]@data ## 在标准化数据的基础上进行归一化处理 dat1 <- as.data.frame(dat1) dat1 <- t(dat1) ## 首先转置, 按列计算速度快 mean_all = apply(dat1, 2, mean) sd_all = apply(dat1, 2, sd) for (i in 1:ncol(dat1)) { dat1[,i] <- (dat1[,i] - mean_all[i])/sd_all[i] ## 观测值减去平均值, 然后除以标准差 } dat1 <- t(dat1) ## 归一化计算结果 dat1[1:4, 1:4] std_res[1:4, 1:4] ## 对比结果