摘自《Netty 即时聊天实战与底层原理》
通过 [09] 的学习,我们已经知道,Netty 的 Reactor 线程就像是一个发动机,驱动着整个框架的运行,而服务端启动和新连接接入正是发送机的导火线,将发动机点燃。
在服务端端口绑定和新连接建立的过程中会建立相应的 Channel,而与 Channel 密切相关的是 Pipeline 这个概念,ChannelPipeline 可以看做一条流水线,原料(字节流)进来,经过加工,形成一个个 Java 对象,然后基于这些对象进行处理,最后输出二进制字节流。
本章将以新连接接入为入口,分以下几个部分介绍 Netty 中的 ChannelPipeline 是如何运转起来的。
- ChannelPipeline 的初始化
- ChannelPipeline 添加 ChannelHandler
- ChannelPipeline 删除 ChannelHandler
- Inbound 事件的传播
- OutBound 事件的传播
- 异常事件的传播
1. ChannelPipeline 的初始化
在学习新连接建立过程中,我们已经知道创建 NioSocketChannel 的时候会将 Netty 的核心组件创建出来,ChannelPipeline 就是其中一员。
AbstractChannel
protected AbstractChannel(Channel parent) {
this.parent = parent;
id = newId();
unsafe = newUnsafe();
pipeline = newChannelPipeline();
}
protected DefaultChannelPipeline newChannelPipeline() {
return new DefaultChannelPipeline(this);
}
创建一个 ChannelPipeline 的默认实现如下。
DefaultChannelPipeline
protected DefaultChannelPipeline(Channel channel) {
this.channel = ObjectUtil.checkNotNull(channel, "channel");
succeededFuture = new SucceededChannelFuture(channel, null);
voidPromise = new VoidChannelPromise(channel, true);
tail = new TailContext(this);
head = new HeadContext(this);
head.next = tail;
tail.prev = head;
}
ChannelPipeline 中保存了 Channel 的引用,创建完 ChannelPipeline 之后,整个 ChannelPipeline 的结构如下图所示:
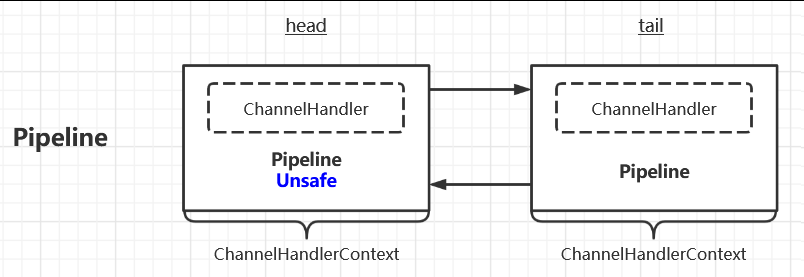
ChannelPipeline 中的每个节点都是一个 ChannelHandlerContext 对象,每个 ChannelHandlerContext 节点都保存了它包裹的执行器 ChannelHandler 执行操作所需要的上下文,其实就是 ChannelPipeline,因为 ChannelPipeline 包含了 Channel 的引用,所以可以拿到所有的上下文信息。
在默认情况下,一条 ChannelPipeline 会有两个节点,TailContext 和 HeadContext。后面会具体分析这两个特殊的节点。接下来,我们先分析如何向 ChannelPipeline 中添加一个节点。
2. ChannelPipeline 添加 ChannelHandler
下面是一段非常常见的客户端代码。
serverBootStrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new Spliter());
p.addLast(new Decoder());
p.addLast(new BusinessHandler());
p.addLast(new Encoder());
}
});
首先,用一个拆包器 Spliter 将二进制数据流进行拆包,然后将拆出来的包进行解码,解码成 Java 对象之后传入业务处理器 BusinessHandler,业务处理完编码成二进制形式输出。

这里共有两种不同类型的节点,一种是 ChannelInboundHandler,处理 Inbound 事件,最典型的就是读取数据流,加工处理;还有一种类型的节点是 ChannelOutboundHandler,处理 Outbound 事件,比如当调用 writeAndFlush 方法的时候,就会经过该种类型的 Handler。
不管是哪种类型的 Handler,其外层对象 ChannelHandlerContext 之间都是通过双向链表连接的。而区分一个 Handler 到底是 ChannelInboundHandler 还是 ChannelOutboundHandler,在添加节点的时候我们就可以看到 Netty 是怎么处理的。
DefaultChannelPipeline
@Override
public final ChannelPipeline addLast(ChannelHandler... handlers) {
return addLast(null, handlers);
}
@Override
public final ChannelPipeline addLast(EventExecutorGroup executor, ChannelHandler... handlers) {
if (handlers == null) {
throw new NullPointerException("handlers");
}
for (ChannelHandler h: handlers) {
if (h == null) {
break;
}
addLast(executor, null, h);
}
return this;
}
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
// 1. 检查是否有重复的 handler
checkMultiplicity(handler);
// 2. 创建节点
newCtx = newContext(group, filterName(name, handler), handler);
// 3. 添加节点
addLast0(newCtx);
// ...
}
// 4. 回调用户方法
callHandlerAdded0(newCtx);
return this;
}
这里简单地用 synchronized 是为了防止多线程并发操作 ChannelPipeline 底层的双向链表,实际添加节点的过程分为以下 4 部分:
- 检查是否有重复的 handler;
- 创建节点;
- 添加节点;
- 回调用户方法。
2.1 检查是否有重复的 Handler
DefaultChannelPipeline
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
// => 1. 检查是否有重复的 handler
checkMultiplicity(handler);
// 2. 创建节点
newCtx = newContext(group, filterName(name, handler), handler);
// 3. 添加节点
addLast0(newCtx);
// ...
}
// 4. 回调用户方法
callHandlerAdded0(newCtx);
return this;
}
在用户代码中,调用 addLast() 方法添加一个 Handler 对象的时候,首先会查看该 Handler 有没有被添加过。
private static void checkMultiplicity(ChannelHandler handler) {
if (handler instanceof ChannelHandlerAdapter) {
ChannelHandlerAdapter h = (ChannelHandlerAdapter) handler;
if (!h.isSharable() && h.added) {
throw new ChannelPipelineException(h.getClass().getName() +
" is not a @Sharable handler, so can't be added or removed multiple times.");
}
h.added = true;
}
}
Netty 使用一个成员变量 added 标识一个 ChannelHandler 是否已经添加。上面这段代码很简单,如果当前要添加的 Handler 是非共享的,并且已经添加过,那么就抛出异常;否则,标识该 Handler 已经添加。
由此可见,一个 Handler 如果是支持共享的,就可以无限次被添加到 ChannelPipeline 中。客户端代码如果要让一个 Handler 共享,只需要加一个 @Sharable 注解即可,例如:
@Sharable
public class BusinessHandler { /* ... */ }
而如果 Handler 是共享的,一般就通过 Spring 注入的方式使用,而不需要每次都重新创建。 isSharable() 方法正是通过该 Handler 对应的类是否标注 @Sharable 注解来实现的。
ChannelHandlerAdapter
public boolean isSharable() {
Class<?> clazz = getClass();
Map<Class<?>, Boolean> cache = InternalThreadLocalMap.get().handlerSharableCache();
Boolean sharable = cache.get(clazz);
if (sharable == null) {
sharable = clazz.isAnnotationPresent(Sharable.class);
cache.put(clazz, sharable);
}
return sharable;
}
从这里也可以看出,Netty 为了性能优化,还是用了 ThreadLocal 来缓存 Handler 的状态。在高并发海量的连接下,每次有新连接添加 Handler 都会创建调用此方法,从而优化性能。
2.2 创建节点
回到主流程,我们看创建上下文这段代码。
DefaultChannelPipeline
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
// 1. 检查是否有重复的 handler
checkMultiplicity(handler);
// => 2. 创建节点
newCtx = newContext(group, filterName(name, handler), handler);
// 3. 添加节点
addLast0(newCtx);
// ...
}
// 4. 回调用户方法
callHandlerAdded0(newCtx);
return this;
}
这里我们需要先分析 filterName(name, handler) 这个方法,这个方法用于给 Handler 创建一个唯一性的名字。
DefaultChannelPipeline
private String filterName(String name, ChannelHandler handler) {
if (name == null) {
return generateName(handler);
}
checkDuplicateName(name);
return name;
}
显然,在默认情况下,我们传入的 name 为 null,Netty 就生成一个默认的 name;否则,检查是否有重名,检查通过则返回。
Netty 创建默认 name 的规则为:“简单类型#0”,下面我们来看下具体是怎么实现的。
DefaultChannelPipeline
private static final FastThreadLocal<Map<Class<?>, String>> nameCaches =
new FastThreadLocal<Map<Class<?>, String>>() {
@Override
protected Map<Class<?>, String> initialValue() throws Exception {
return new WeakHashMap<Class<?>, String>();
}
};
private static String generateName0(Class<?> handlerType) {
return StringUtil.simpleClassName(handlerType) + "#0";
}
private String generateName(ChannelHandler handler) {
// 先查看缓存中是否生成过默认 name
Map<Class<?>, String> cache = nameCaches.get();
Class<?> handlerType = handler.getClass();
String name = cache.get(handlerType);
// 没有生成过,就生成一个默认 name,加入缓存
if (name == null) {
name = generateName0(handlerType);
cache.put(handlerType, name);
}
// It's not very likely for a user to put more than one handler of
// the same type, but make sure to avoid any name conflicts.
// Note that we don't cache the names generated here.
// 生成后,还要看默认 name 有没有冲突
if (context0(name) != null) {
String baseName = name.substring(0, name.length() - 1); // Strip the trailing '0'.
for (int i = 1;; i ++) {
String newName = baseName + i;
if (context0(newName) == null) {
name = newName;
break;
}
}
}
return name;
}
Netty 使用一个 FastThreadLocal 变量来缓存 Handler 的类和默认名称的映射关系,在生成 name 的时候,首先查看缓存中有没有生成过默认 name(简单类名#0),如果没有生成,就调用 generateName0() 生成默认 name,然后加入缓存。
接下来需要检查 name 是否和已有的 name 有冲突,调用 context0() 方法,查找 ChannelPipeline 里有没有对应的 ChannelHandler 节点。
DefaultChannelPipeline
private AbstractChannelHandlerContext context0(String name) {
AbstractChannelHandlerContext context = head.next;
while (context != tail) {
if (context.name().equals(name)) {
return context;
}
context = context.next;
}
return null;
}
context0() 遍历链表中每一个 ChannelHandlerContext,只要发现某个 context 的 name 与待添加的 name 相同,就返回该 context,最后抛出异常,这是一个线性搜索过程。
所以,如果 context0(name) != null 成立,说明现有的 ChannelHandlerContext 节点链表中已经有了一个默认的 name,那么就从“简单类名#1”往上一直找,直到找到一个唯一的 name,比如“简单类型#3”,这是一个不断试探的过程。
当然,如果用户代码在添加 Handler 的时候指定了一个 name,那么要做的仅仅是检查一下是否有重复的节点。
DefaultChannelPipeline
private void checkDuplicateName(String name) {
if (context0(name) != null) {
throw new IllegalArgumentException("Duplicate handler name: " + name);
}
}
处理完 name 之后,就进入调用 newContext 方法真正创建 context 的过程。
private AbstractChannelHandlerContext newContext(
EventExecutorGroup group, String name, ChannelHandler handler) {
return new DefaultChannelHandlerContext(this, childExecutor(group), name, handler);
}
private EventExecutor childExecutor(EventExecutorGroup group) {
if (group == null) {
return null;
}
// ...
}
由前面的调用链得知,group 为 null,因此 childExecutor(group) 也返回 null。
接下来调用 DefaultChannelHandlerContext 构造方法。
DefaultChannelHandlerContext(DefaultChannelPipeline pipeline,
EventExecutor executor, String name, ChannelHandler handler) {
super(pipeline, executor, name, isInbound(handler), isOutbound(handler));
if (handler == null) {
throw new NullPointerException("handler");
}
this.handler = handler;
}
在 DefaultChannelHandlerContext 的构造方法中,DefaultChannelHandlerContext 将参数回传到父类,保存 handler 的引用。我们进入其父类。
AbstractChannelHandlerContext
AbstractChannelHandlerContext(DefaultChannelPipeline pipeline,
EventExecutor executor, String name, boolean inbound, boolean outbound) {
this.name = ObjectUtil.checkNotNull(name, "name");
this.pipeline = pipeline;
this.executor = executor;
this.inbound = inbound;
this.outbound = outbound;
// Its ordered if its driven by the EventLoop or
// the given Executor is an instanceof OrderedEventExecutor.
ordered = executor == null || executor instanceof OrderedEventExecutor;
}
Netty 中用两个字段来表示这个 ChannelHandlerContext 是 Inbound 类型还是 outBound 类型的,或者两者都是,通过下面两个方法来判断。
private static boolean isInbound(ChannelHandler handler) {
return handler instanceof ChannelInboundHandler;
}
private static boolean isOutbound(ChannelHandler handler) {
return handler instanceof ChannelOutboundHandler;
}
我们看到,Netty 是通过 instanceof 关键字根据接口类型来判断的,因此,如果一个 Handler 实现了两类接口,那么它既是一个 Inbound 类型的 Handler,又是一个 Outbound 类型的 Handler,比如 ChannelDuplexHandler 这个类。
我们将常用的 decode 操作和 encode 操作合并到一起的 codec,一般会继承 MessageToMessageCodec,而 MessageToMessageCodec 就继承自 ChannelDuplexHandler。
public abstract class MessageToMessageCodec<INBOUND_IN, OUTBOUND_IN> extends ChannelDuplexHandler {
protected abstract void encode(ChannelHandlerContext ctx, OUTBOUND_IN msg, List<Object> out)
throws Exception;
protected abstract void decode(ChannelHandlerContext ctx, INBOUND_IN msg, List<Object> out)
throws Exception;
// ...
}
ChannelHandlerContext 创建完后,接下来需要将这个节点添加到 Channel 的 ChannelPipeline 中。
2.3 添加节点
DefaultChannelPipeline
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
// 1. 检查是否有重复的 handler
checkMultiplicity(handler);
// 2. 创建节点
newCtx = newContext(group, filterName(name, handler), handler);
// => 3. 添加节点
addLast0(newCtx);
// ...
}
// 4. 回调用户方法
callHandlerAdded0(newCtx);
return this;
}
调用 addLast0() 方法,真正添加节点。
private void addLast0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext prev = tail.prev;
newCtx.prev = prev;
newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx;
}
操作完毕,该 ChannelHandlerContext 节点就加入 ChannelHandlerPipeline 了。到这里,ChannelPipeline 添加节点的操作就完成了。
2.4 回调用户方法
Netty 框架最优秀的设计之一就是在很多地方会埋一些扩展点,用户代码可以在适当的时机做很多定制化操作。这里,当节点添加完毕之后,可以回调用户方法。
DefaultChannelPipeline
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
// 1. 检查是否有重复的 handler
checkMultiplicity(handler);
// 2. 创建节点
newCtx = newContext(group, filterName(name, handler), handler);
// 3. 添加节点
addLast0(newCtx);
// ...
}
// => 4. 回调用户方法
callHandlerAdded0(newCtx);
return this;
}
private void callHandlerAdded0(final AbstractChannelHandlerContext ctx) {
ctx.handler().handlerAdded(ctx);
ctx.setAddComplete();
}
到了第 4 步,ChannelPipeline 中的新节点添加完成,于是便开始回调用户代码 ctx.handler().handlerAdded(ctx)。
接下来,设置该节点的状态。
AbstractChannelHandlerContext
final void setAddComplete() {
for (;;) {
int oldState = handlerState;
// Ensure we never update when the handlerState is REMOVE_COMPLETE already.
// oldState is usually ADD_PENDING but can also be REMOVE_COMPLETE
// when an EventExecutor is used that is not exposing ordering guarantees.
if (oldState == REMOVE_COMPLETE
|| HANDLER_STATE_UPDATER.compareAndSet(this, oldState, ADD_COMPLETE)) {
return;
}
}
}
用 CAS 修改节点的状态至 ADD_COMPLETE(说明该节点添加完成)。
2.5 小结
用户调用 addLast 类方法或者其他 add 类方法往 ChannelPipeline 中添加 ChannelHandler 的时候:
- 根据名字检查待添加的 Handler 是否重复,如果没有名字则使用简单类名默认生成一个名字;
- 创建一个 ChannelHandlerContext 包裹着 Handler,并且每一个 ChannelHandlerContext 都拥有一个 Channel 的所有信息;
- 通过双向链表的方式,将 ChannelHandlerContext 添加到 ChannelPipeline;
- 添加完结点之后,会调用用户所添加 Handler 的 handlerAdded 方法。
3. ChannelPipeline 删除 ChannelHandler
Netty 最大的特性之一就是 ChannelHandler 可拔插,做到动态编制 ChannelPipeline。
一个比较典型的例子:在客户端首次连接服务端的时候,需要进行权限认证。认证通过之后,该连接合法,后续就可以不用再认证了。
我们只需要使用一个 AuthHandler 就能满足这个需求:下面是权限认证 AuthHandler 最简单的实现,第一个数据包传来的是认证信息,如果校验通过,则删除此 AuthHandler,后续不会进入 verify 逻辑;否则,直接关闭连接。
@Slf4j
public class AuthHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (!LoginUtil.hasLogin(ctx.channel())) {
ctx.channel().close();
} else {
// --- ↓↓↓ 重点 ↓↓↓ ---
ctx.pipeline().remove(this);
// 把读到的数据向下传递,传递给后续指令处理器。
super.channelRead(ctx, msg);
}
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
if (LoginUtil.hasLogin(ctx.channel())) {
log.info("[{}] 当前连接登录验证完毕,无需再次验证,AuthHandler 被移除。", new Date());
} else {
log.error("[{}] 无登录验证,强制关闭连接!");
}
}
}
class LoginUtil {
public static void markAsLogin(Channel channel) {
channel.attr(Attributes.LOGIN).set(true);
}
public static boolean hasLogin(Channel channel) {
Attribute<Boolean> loginAttr = channel.attr(Attributes.LOGIN);
return loginAttr.get() != null;
}
public static boolean valid(LoginRequestPacket loginRequestPacket) {
// ...
return true;
}
}
重点就在 ctx.pipeline().remove(this) 这段代码上。
DefaultChannelPipeline
@Override
public final ChannelPipeline remove(ChannelHandler handler) {
remove(getContextOrDie(handler));
return this;
}
删除 ChannelHandler 操作相比添加 ChannelHandler 简单不少,分为 3 个步骤:
- 找到待删除节点;
- 调整双向链表指针并删除;
- 回调用户方法。
3.1 找到待删除的节点
DefaultChannelPipeline
private AbstractChannelHandlerContext getContextOrDie(ChannelHandler handler) {
AbstractChannelHandlerContext ctx = (AbstractChannelHandlerContext) context(handler);
if (ctx == null) {
throw new NoSuchElementException(handler.getClass().getName());
} else {
return ctx;
}
}
@Override
public final ChannelHandlerContext context(ChannelHandler handler) {
if (handler == null) {
throw new NullPointerException("handler");
}
AbstractChannelHandlerContext ctx = head.next;
// 1. 遍历双向链表找到指定 Handler
for (;;) {
if (ctx == null) {
return null;
}
if (ctx.handler() == handler) {
return ctx;
}
ctx = ctx.next;
}
}
这里为了找到 Handler 对应的 ChannelHandlerContext,依然是通过依次遍历双向链表的方式,直到某一个 ChannelHandlerContext 包裹的 Handler 和当前 Handler 相同,即找到该节点。
3.2 调整双向链表指针并删除
找到了 ChannelPipeline 中对应的 ChannelHandlerContext 节点之后,即可以展开对这个节点的删除操作了。
DefaultChannelPipeline
private AbstractChannelHandlerContext remove(final AbstractChannelHandlerContext ctx) {
assert ctx != head && ctx != tail;
synchronized (this) {
// 2. 调整双向链表指针并删除
remove0(ctx);
// If the registered is false it means that the channel
// was not registered on an eventloop yet.
// In this case we remove the context from the pipeline and
// add a task that will call ChannelHandler.handlerRemoved(...)
// once the channel is registered.
if (!registered) {
callHandlerCallbackLater(ctx, false);
return ctx;
}
EventExecutor executor = ctx.executor();
if (!executor.inEventLoop()) {
executor.execute(new Runnable() {
@Override
public void run() {
callHandlerRemoved0(ctx);
}
});
return ctx;
}
}
// 3. 回调用户方法
callHandlerRemoved0(ctx);
return ctx;
}
private static void remove0(AbstractChannelHandlerContext ctx) {
AbstractChannelHandlerContext prev = ctx.prev;
AbstractChannelHandlerContext next = ctx.next;
prev.next = next;
next.prev = prev;
}
被删除的节点因为没有对象引用,过段时间就会被 JVM 自动回收,删除这个 Handler 之后,与添加 Handler 的操作一样,也会有一个用户代码的回调。
3.3 回调用户方法
DefaultChannelPipeline
private void callHandlerRemoved0(final AbstractChannelHandlerContext ctx) {
try {
ctx.handler().handlerRemoved(ctx);
} finally {
ctx.setRemoved();
}
}
final void setRemoved() {
handlerState = REMOVE_COMPLETE;
}
到了第 3 步,ChannelPipeline 中的节点删除完成,于是开始回调用户代码 ctx.handler().handlerRemoved(ctx)。最后,该节点的状态设置为 REMOVE_COMPLETE。
3.4 小结
ChannelPipeline 对 ChannelHandler 的删除和添加是一对相反的操作,删除 ChannelHandler 的时候:
- 定位到 ChannelHandler 对应的 ChannelHandlerContext 节点;
- 通过调整 ChannelPipeline 中双向链表的指针删除对应的 ChannelHandlerContext 节点;
- 回调到用户的 handlerRemoved 方法,我们可以再这个回调方法中做一些资源清理的操作。
4. Inbound 事件的传播
我们已经了解了 ChannelPipeline 在 Netty 中所处的角色,像一条流水线,控制着字节流的读写。接下来,我们在这个基础上继续深挖 Pipeline 在事件处理、异常传播等方面的原理。
4.1 Unsafe 是什么
之所以把 Unsafe 放到 ChannelPipeline 中讲,是因为 Unsafe 和 ChannelPipeline 密切相关。ChannelPipeline 中有关 IO 的操作最终都是落地到 Unsafe 的,所以,有必要先讲讲 Unsafe。
a. 初识 Unsafe
顾名思义,Unsafe 是不安全的意思,就是告诉你不要在应用程序里直接使用 Unsafe 及它的衍生类对象。
A nexus to a network socket or a component which is capable of I/O operations such as read, write, connect, and bind. Unsafe operations that should never be called from user-code. These methods are only provided to implement the actual transport, and must be invoked from an IO thread.
Unsafe 在 Channel 定义,属于 Channel 的内部类,表明 Unsafe 和 Channel 密切相关。
下面是 Unsafe 接口的所有方法。
RecvByteBufAllocator.Handle recvBufAllocHandle();
SocketAddress localAddress();
SocketAddress remoteAddress();
void register(EventLoop eventLoop, ChannelPromise promise);
void bind(SocketAddress localAddress, ChannelPromise promise);
void connect(SocketAddress remoteAddress, SocketAddress localAddress, ChannelPromise promise);
void disconnect(ChannelPromise promise);
void close(ChannelPromise promise);
void closeForcibly();
void deregister(ChannelPromise promise);
void beginRead();
void write(Object msg, ChannelPromise promise);
void flush();
ChannelPromise voidPromise();
ChannelOutboundBuffer outboundBuffer();
按功能可以分为内存分配、Socket 四元组信息、注册事件循环、绑定端口、Socket 的连接和关闭、Socket 的读写,看得出来,这些操作都和 JDK 底层相关。
b. Unsafe 继承结构

从增加的接口及类名上来看:
- NioUnsafe 增加了可以访问底层 JDK 的 SelectableChannel 的功能,定义了从 SelectableChannel 读取数据的 read 方法;
// Special Unsafe sub-type which allows to access the underlying SelectableChannel public interface NioUnsafe extends Unsafe { SelectableChannel ch(); void finishConnect(); void read(); void forceFlush(); } - AbstractUnsafe 实现了大部分 Unsafe 的功能;
- AbstractUnsafe 主要是通过代理到其外部类 AbstractNioUnsafe 获得了与 JDK NIO 相关的一些信息,比如 SelectableChannel、SelectionKey 等;
- 把 NioSokcetChannelUnsafe 和 NioByteUnsafe 放到一起讲,实现了 IO 的基本操作 —— 读和写,这些操作都与 JDK 底层相关;
- NioMessageUnsafe 和 NioByteUnsafe 是处在同一层次的抽象,Netty 将一个新连接的建立也当作一个 IO 操作来处理,这里 Message 的含义我们可以当作一个 SelectableChannel,读的意思就是接收到了一个 SelectableChannel。
c. Unsafe 的分类
从以上继承结构来看,我们可以总结出两种类型的 Unsafe,一种是与连接的字节数据读写相关的 NioByteUnsafe,一种是与新连接建立操作相关的 NioMessageUnsafe。
(1)NioByteUnsafe 读
AbstractNioByteChannel
protected class NioByteUnsafe extends AbstractNioUnsafe {
@Override
public final void read() {
// ...
doReadBytes(byteBuf);
// ...
}
}
NioByteUnsafe 中的读被委托到外部类 AbstractNioByteChannel。
public class NioSocketChannel extends AbstractNioByteChannel implements io.netty.channel.socket.SocketChannel {
@Override
protected int doReadBytes(ByteBuf byteBuf) throws Exception {
final RecvByteBufAllocator.Handle allocHandle = unsafe().recvBufAllocHandle();
allocHandle.attemptedBytesRead(byteBuf.writableBytes());
return byteBuf.writeBytes(javaChannel(), allocHandle.attemptedBytesRead());
}
}
可以看到,最后一行已经与 JDK 底层及 Netty 中的 ByteBuf 相关,将 JDK 的 SelectableChannel 的字节数据读取到 Netty 的 ByteBuf 中。
(2)NioMessageUnsafe 读
AbstractNioMessageChannel
private final class NioMessageUnsafe extends AbstractNioUnsafe {
@Override
public void read() {
doReadMessages(readBuf);
}
}
NioMessageUnsafe 中的读最后是委托到外部类 AbstractNioMessageChannel。
public class NioServerSocketChannel extends AbstractNioMessageChannel
implements io.netty.channel.socket.ServerSocketChannel {
@Override
protected int doReadMessages(List<Object> buf) throws Exception {
SocketChannel ch = SocketUtils.accept(javaChannel());
if (ch != null) {
buf.add(new NioSocketChannel(this, ch));
return 1;
}
return 0;
}
}
NioMessageUnsafe 的读操作很简单,就是调用 JDK 的 accept() 方法,新建立一条连接。
(3)NioByteUnsafe 写
NioByteUnsafe 中的写有两个方法,一个是 write,一个是 flush。write 是将数据添加到 Netty 的缓冲区,实际将字节流写到 TCP 缓冲区的方法是 flush,最终会委托到 NioSokcetChannel 的 doWrite() 方法。
@Override
protected int doWriteBytes(ByteBuf buf) throws Exception {
final int expectedWrittenBytes = buf.readableBytes();
return buf.readBytes(javaChannel(), expectedWrittenBytes);
}
可以看到,这个方法最终会调用 JDK 底层的 Channel 进行数据读写。
(4)NioMessageUnsafe 写
NioMessageUnsafe 的写没有太大意义,这里就不分析了。
4.2 HeadContext
HeadContext 节点在 ChannelPipeline 中第一个处理 IO 事件,新连接接入和读事件在 Reactor 线程的第 2 个过程(检测 IO 事件)中被检测到,之前已经介绍过了。
NioEventLoop
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
}
读操作直接依赖 Unsafe 来操作,新连接的接入在前面的章节中已详细阐述过,这里不再描述。下面我们将重点放到连接字节数据流的读写。连接数据读写对应的 Unsafe 是 NioByteUnsafe。
NioByteUnsafe
Override
public final void read() {
final ChannelConfig config = config();
final ChannelPipeline pipeline = pipeline();
// 分配 ByteBuf 分配器
final ByteBufAllocator allocator = config.getAllocator();
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
allocHandle.reset(config);
ByteBuf byteBuf = null;
boolean close = false;
do {
// 1. 分配一个 ByteBuf
byteBuf = allocHandle.allocate(allocator);
// 2. 将数据读取到分配的 ByteBuf 中
allocHandle.lastBytesRead(doReadBytes(byteBuf));
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
readPending = false;
}
break;
}
allocHandle.incMessagesRead(1);
readPending = false;
// 3. 触发事件,将会引发 ChannelPipeline 的读事件传播
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while (allocHandle.continueReading());
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
if (close) {
closeOnRead(pipeline);
}
// ...
}
抽出核心代码,剪去细枝末节,NioByteUnsafe 要做的事情可以简单地分为以下几个步骤:
- 通过 Channel 的 ChannelConfig,获取 ByteBuf 分配器,用分配器来分配一个 ByteBuf(ByteBuf 是 Netty 里的字节数据载体);
- 将 Channel 中的数据读取到 ByteBuf;
- 数据读完之后,调用
pipeline.fireChannelRead(ByteBuf)从 HeadContext 节点开始传播事件至整个 ChannelPipeline;
这里,我们的重点其实就是 pipeline.fireChannelRead(byteBuf)。
DefaultChannelPipeline
final AbstractChannelHandlerContext head;
protected DefaultChannelPipeline(Channel channel) {
// ...
head = new HeadContext(this);
// ...
}
@Override
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
在进行下一步分析之前,我们先把 HeadContext 节点的功能捋一遍。
DefaultChannelPipeline
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
private final Unsafe unsafe;
HeadContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, HEAD_NAME, false, true);
unsafe = pipeline.channel().unsafe();
setAddComplete();
}
@Override
public ChannelHandler handler() {
return this;
}
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
// NOOP
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
// NOOP
}
@Override
public void bind(
ChannelHandlerContext ctx, SocketAddress localAddress, ChannelPromise promise)
throws Exception {
unsafe.bind(localAddress, promise);
}
@Override
public void connect(
ChannelHandlerContext ctx,
SocketAddress remoteAddress, SocketAddress localAddress,
ChannelPromise promise) throws Exception {
unsafe.connect(remoteAddress, localAddress, promise);
}
@Override
public void disconnect(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception {
unsafe.disconnect(promise);
}
@Override
public void close(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception {
unsafe.close(promise);
}
@Override
public void deregister(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception {
unsafe.deregister(promise);
}
@Override
public void read(ChannelHandlerContext ctx) {
unsafe.beginRead();
}
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
@Override
public void flush(ChannelHandlerContext ctx) throws Exception {
unsafe.flush();
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.fireExceptionCaught(cause);
}
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
invokeHandlerAddedIfNeeded();
ctx.fireChannelRegistered();
}
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelUnregistered();
// Remove all handlers sequentially if channel is closed and unregistered.
if (!channel.isOpen()) {
destroy();
}
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelActive();
readIfIsAutoRead();
}
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelInactive();
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelReadComplete();
readIfIsAutoRead();
}
private void readIfIsAutoRead() {
if (channel.config().isAutoRead()) {
// 调用 Channel 的读方法
channel.read();
}
}
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
ctx.fireUserEventTriggered(evt);
}
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelWritabilityChanged();
}
}
从 HeadContext 节点实现的两个接口看,它既是一个 ChannelHandlerContext(表明本身它就是 ChannelPipeline 中的一个节点),同时属于 Inbound 和 Outbound 类型的 Handler。
在传播读写事件的时候,HeadContext 的功能只是简单地将事件传播下去,如 ctx.fireChannelRead(msg),在真正执行读写操作的时候,例如在调用 writeAndFlush() 等方法的时候,最终都会委托 Unsafe 执行。
当一次数据读完,channelReadComplete() 方法首先被调用,它要做的事情除了将事件继续传播下去,还会继续向 Reactor 线程注册读事件,即调用 readIfIsAutoRead(),我们来简单分析一下。
AbstractChannel
@Override
public Channel read() {
pipeline.read();
return this;
}
在默认情况下,Channel 都是默认开启自动读取模式的,即只要 Channel 是活跃的,读完一波数据之后就继续向 Selector 注册读事件,这样就可以连续不断地读取数据,最终通过 ChannelPipeline 传递到 HeadContext 节点。
HeadContext
@Override
public void read(ChannelHandlerContext ctx) {
unsafe.beginRead();
}
接下来委托到了 NioByteUnsafe。
@Override
public final void beginRead() {
assertEventLoop();
doBeginRead();
}
AbstractNioChannel
@Override
protected void doBeginRead() throws Exception {
// Channel.read() or ChannelHandlerContext.read() was called
final SelectionKey selectionKey = this.selectionKey;
if (!selectionKey.isValid()) {
return;
}
readPending = true;
final int interestOps = selectionKey.interestOps();
if ((interestOps & readInterestOp) == 0) {
selectionKey.interestOps(interestOps | readInterestOp);
}
}
doBeginRead() 做的事情很简单,拿到处理过的 SelectionKey,如果发现该 SelectionKey 在某个地方被移除了 readInterestOp 操作,这里会给它加上(事实上,通常情况下是不会走到这一行的,即 if 条件不会成立),只有在 TCP 三次握手成功之后,才会调用如下方法,下面是 TCP 三次握手成功之后的回调。
HeadContext
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelActive();
readIfIsAutoRead();
}
在首次连接的时候,会将 readInterestOp 注册到 SelectionKey。
总结一点,HeadContext 节点的作用就是作为 ChannelPipeline 的头节点,开始传递读写事件,调用 Unsafe 进行实际读写操作。下面我们开始分析 ChannelPipeline 的 Inbound 事件的传播。
4.3 Inbound 事件传播
这一节,我们通过 channelActive 事件来分析一下 ChannelPipeline 中 Inbound 事件的传播,其他 Inbound 事件,包括 channelInactive、channelRegistered、channelUnregistered、channelRead、channelReadComplete 等,原理是一致的。
在上一章中,没详细描述为什么 pipeline.fireChannelActive() 最终会调用 AbstractNioChannel.doBeginRead(),了解 ChannelPipeline 中事件传播机制,你会发现其实相当简单。
新连接建立成功,三次握手之后,pipeline.fireChannelActive() 被调用。
DefaultChannelPipeline
@Override
public final ChannelPipeline fireChannelActive() {
AbstractChannelHandlerContext.invokeChannelActive(head);
return this;
}
然后以 HeadContext 节点为参数,直接调用一个静态方法。
AbstractChannelHandlerContext
static void invokeChannelActive(final AbstractChannelHandlerContext next) {
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelActive();
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelActive();
}
});
}
}
首先,Netty 为了确保线程的安全性,将确保该操作在 Reactor 线程中被执行,因为是在 Reactor 线程中被执行,所以直接调用 HeadContext.fireChannelActive() 方法。
HeadContext
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelActive();
readIfIsAutoRead();
}
可以看到,readIfIsAutoRead() 在 HeadContext 传播 active 事件的时候被调用。
我们继续分析 channelActive 事件的传播过程。
AbstractChannelHandlerContext
@Override
public ChannelHandlerContext fireChannelActive() {
invokeChannelActive(findContextInbound());
return this;
}
首先,调用 findContextInbound() 找到下一个 Inbound 节点,由于当前 ChannelPipeline 的双向链表结构中,既有 Inbound 节点,又有 Outbound 节点,下面来看看 Netty 是如何找到下一个 Inbound 节点的。
AbstractChannelHandlerContext
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
这段代码很清楚地表明,Netty 寻找下一个 Inbound 节点的过程是一个线性搜索的过程,它会遍历双向链表的下一个节点,直到下一个节点为 Inbound。
找到下一个节点之后,递归调用 invokeChannelActive(next),直到最后一个 Inbound 节点 —— TailContext 节点。
TailContext
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
onUnhandledInboundChannelActive();
}
protected void onUnhandledInboundChannelActive() {}
TailContext 节点的该方法为空,结束调用。同理,可以分析其他 Inbound 事件的传播,在正常情况下,即用户如果不覆盖每一个节点的事件回调方法,则几乎所有的事件最后都落到 TailContext 节点。所以,接下来,我们分析一下 TailContext 节点的功能。
4.4 TailContext
DefaultChannelPipeline
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
TailContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, TAIL_NAME, true, false);
setAddComplete();
}
@Override
public ChannelHandler handler() {
return this;
}
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception { }
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception { }
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
onUnhandledInboundChannelActive();
}
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
onUnhandledInboundChannelInactive();
}
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
onUnhandledChannelWritabilityChanged();
}
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception { }
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception { }
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
onUnhandledInboundUserEventTriggered(evt);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
onUnhandledInboundException(cause);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
onUnhandledInboundMessage(msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
onUnhandledInboundChannelReadComplete();
}
}
正如前面提到的,TailContext 节点的大部分作用为终止事件的传播(方法体为空)。除此之外,有两个重要的方法我们必须提一下,即 exceptionCaught() 和 channelRead()。
首先来看下 exceptionCaught() 这个方法。异常的传播机制和 Inbound 事件传播机制类似,最终如果用户自定义 ChannelHandler 没有处理,则会落到 TailContext 节点,TailContext 节点可不会简单地“吞下”这个异常,而是发出告警:
DefaultChannelPipeline
protected void onUnhandledInboundException(Throwable cause) {
try {
logger.warn("An exceptionCaught() event was fired, and it reached at the tail of the pipeline. "
+ "It usually means the last handler in the pipeline did not handle the exception.", cause);
} finally {
ReferenceCountUtil.release(cause);
}
}
我们再看下 channelRead() 方法。TailConText 节点在发现字节数据 ByteBuf 或者 decode 之后地业务对象在 ChannelPipeline 流转过程中没有被消费,落到 TailContext 节点时,TailContext 节点就会发出一个警告,告诉你:“我已经将你未处理的数据丢掉了”。
DefaultChannelPipeline
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug("Discarded inbound message {} that reached at the tail of the pipeline. "
+ "Please check your pipeline configuration.", msg);
} finally {
ReferenceCountUtil.release(msg);
}
}
发出告警之后,默认会将未处理的对象进行释放。
总结一下,TailContext 节点的作用就是结束事件传播,并且对一些重要的事件进行善意提醒。
4.5 小结
- 一般我们自定义 ChannelInboundHandler 都继承自 ChannelInboundHandlerAdapter 类,如果用户代码没有覆盖 ChannelInboundHandler.channelXXX() 方法,Inbound 事件从 HeadContext 开始传播,遍历 ChannelPipeline 的双向链表,默认情况下传递到 TailContext 节点;
- 如果用户代码覆盖了 ChannelInboundHandler.channelXXX() 方法,那么事件传播就在当前节点结束;
- 如果用户代码调用 ChannelInboundHandler.fireXXX() 来传播事件,那么这个事件就从当前节点开始往下传播。
5. OutBound 事件的传播
在这一节中,我们以最常见的 writeAndFlush() 方法调用来分析 ChannelPipeline 中的 Outbound 事件是如何进行传播的。
在典型的消息推送系统中,会有类似下面的一段代码。
Channel channel = ChannelManager.getChannel(userId);
channel.writeAndFlush(response);
这段代码的含义就是根据用户 ID 获得对应的 Channel,然后向用户推送消息,跟进 channel.writeAndFlush()。
AbstractChannel
@Override
public ChannelFuture writeAndFlush(Object msg) {
return pipeline.writeAndFlush(msg);
}
从 ChannelPipeline 开始传播。
DefaultChannelPipeline
final AbstractChannelHandlerContext tail;
@Override
public final ChannelFuture writeAndFlush(Object msg) {
return tail.writeAndFlush(msg);
}
从上面这段代码我们可以看到,如果通过 Channel 来传播事件,是从 TailContext 开始传播,writeAndFlush() 方法是 TailContext 类从 AbstractChannelHandlerContext 继承来的方法。
AbstractChannelHandlerContext
@Override
public ChannelFuture writeAndFlush(Object msg) {
return writeAndFlush(msg, newPromise());
}
@Override
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
if (msg == null) {
throw new NullPointerException("msg");
}
if (isNotValidPromise(promise, true)) {
ReferenceCountUtil.release(msg);
// cancelled
return promise;
}
write(msg, true, promise);
return promise;
}
Netty 中很多 IO 操作都是异步操作,返回一个 ChannelFuture 给调用方,调用方获得这个 Future 后,可以在适当的时机拿到操作的结果,或者注册回调。
我们继续分析 write 方法。
AbstractChannelHandlerContext
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
Netty 为了保证程序的高效执行,所有的核心操作都在 Reactor 线程中处理,如果业务线程调用 Channel 的方法,Netty 会将该操作封装成一个 Task,随后在 Reactor 线程事件循环的第 3 个过程中执行。
write() 先调用 findContextOutbound() 方法找到下一个 Outbound 节点。
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
找 Outbound 节点的过程和找 Inbound 节点类似,反方向遍历 ChannelPipeline 中的双向链表,直到第一个 Outbound 节点。
无论调用 writeAndFlush() 方法的线程是 Reactor 线程还是用户线程,最后都会调用 next.invokeWriteAndFlush(m, promise)。
AbstractChannelHandlerContext
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
// 默认返回 true
if (invokeHandler()) {
invokeWrite0(msg, promise);
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}
writeAndFlush() 方法到这里被分解为 invokeWrite0 和 invokeFlush0 方法,invokeFlush0 和 invokeWrite0 的传播过程类似。因此,下面只分析 invokeWrite0 方法。
AbstractChannelHandlerContext
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
我们在使用 Outbound 类型的 ChannelHandler 时,一般会继承 ChannelOutboundHandlerAdapter,而 ChannelOutboundHandlerAdapter 和 ChannelInboundHandlerAdapter 的原理类似,默认情况下都会把事件继续传播下去。
ChannelOutboundHandlerAdapter
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ctx.write(msg, promise);
}
我们已经知道,在 ChannelPipeline 的双向链表结构中,最后一个 Outbound 节点是 HeadContext 节点,因此数据最终会落到它的 write 方法。
HeadContext
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
这里,其实可以加深我们对 HeadContext 节点的理解,即所有的数据写出都会经过 HeadContext 节点。
在实际应用程序中,Outbound 类的节点中会有一种特殊类型的节点叫 encoder,它的作用是根据自定义编码规则将业务对象转换成 ByteBuf,而这类 Encoder 一般继承自 MessageToByteEncoder,下面是一段实例代码。
public class PacketEncoder extends MessageToByteEncoder<Packet> {
@Override
protected void encode(ChannelHandlerContext ctx, Packet packet, ByteBuf out) throws Exception {
// 这里获得业务对象 msg 的数据,然后调用 out.writeXxx() 系列方法编码
}
}
为什么业务代码只需要覆盖这里的 encode 方法,就可以将业务对象转换成字节流写出去呢?
我们查看一下其父类 MessageToByteEncoder 的 write 方法 是怎么处理业务对象的。
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
// 1. 需要判断当前编码器是否能处理这类对象
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
// 2. 分配内存
buf = allocateBuffer(ctx, cast, preferDirect);
try {
// 3. 填充数据
encode(ctx, cast, buf);
} finally {
ReferenceCountUtil.release(cast);
}
// 4. buf 到这里已经装载着数据,于是把该 buf 向前传播,直到 HeadContext 节点
if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
// 5. 如果不能处理,就将 Outbound 事件继续向前传播
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
// 6. 释放内存
if (buf != null) {
buf.release();
}
}
}
- 调用 acceptOutboundMessage() 方法进行判断,该 Encoder 是否可以处理 msg 对应的 Java 对象。通过之后,就强制转换,这里的泛型 I 对应的是 Packet;
- 转换之后,开辟一段内存 ByteBuf;
- 调用 encode(),即回到 PacketEncoder 中,将 buf 装满数据;
- 如果 buf 中被写了数据,即
buf.isReadable(),就将该 buf 往前传递,一直传递到 HeadContext 节点,被 HeadContext 节点的 Unsafe 消费掉; - 当然,如果当前 Encoder 不能处理当前业务对象,就将该业务对象向前传播,直到 HeadContext 节点;
- 都处理完了,释放 buf,免得堆外内存泄漏。
最后,我们来简单总结一下:Outbound 事件传播机制和 Inbound 事件传播非常类似,只不过 Outbound 事件是从链表尾部开始向前传播的,而 Inbound 事件传播是从链表头部开始传播的。关于写数据,最终都会落到 HeadContext 节点的 Unsafe 来处理。
6. 异常事件的传播
我们通常在业务代码中,会加入一个异常处理器,统一处理 ChannelPipeline 过程中的所有异常,并且,一般该异常处理器需要加在自定义节点的末尾(在双向链表中处于 TailContext 之前的位置)。
此自定义类 ExceptionHandler 一般继承自 ChannelDuplexHandler,标识该节点既是一个 Inbound 节点,又是一个 Outbound 节点。我们分别分析一下在 Inbound 事件和 Outbound 事件的过程中,ExceptionHandler 是如何处理这些异常的。
6.1 Inbound 异常的传播
我们以数据的读取为例,看下 Netty 如何传播在这个过程中发生的异常。
a. Inbound 异常的产生
对于每一个节点的数据读取都会调用 AbstractChannelHandlerContext.invokeChannelRead(msg) 方法。
AbstractChannelHandlerContext
private void invokeChannelRead(Object msg) {
try {
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
}
可以看到,最终委托其内部的 ChannelHandler 来处理 channelRead,而在最外层捕获整个 Throwable,因此,我们在用户代码中的异常会被捕获,进入 notifyHandlerException(t),然后传播。下面我们看下它是如何传播的。
b. Inbound 异常的传播
AbstractChannelHandlerContext
private void notifyHandlerException(Throwable cause) {
// ...
invokeExceptionCaught(cause);
}
private void invokeExceptionCaught(final Throwable cause) {
// ...
handler().exceptionCaught(this, cause);
}
可以看到,此 Handler 中异常优先被此 Handler 中的 exceptionCaught 方法来处理,默认情况下,如果不覆写此 Handler 中的 exceptionCaught 方法,则会调用 ChannelInboundHandlerAdapter 的 exceptionCaught 方法。
ChannelInboundHandlerAdapter
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.fireExceptionCaught(cause);
}
AbstractChannelHandlerContext
@Override
public ChannelHandlerContext fireExceptionCaught(final Throwable cause) {
invokeExceptionCaught(next, cause);
return this;
}
到了这里,其实已经很清楚了,如果在自定义 Handler 中没有处理异常,那么默认情况下该异常会一直传递下去,遍历每个节点,直到最后一个自定义异常处理器 ExceptionHandler 来终结该异常。
ExceptionHandler
public ExceptionHandler extends ChannelDuplexHandler {
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
// 处理该异常,并终止该异常的传播
}
}
到了这里,读者应该可以知道为什么异常处理器要加在 ChannelPipeline 链表的最后了吧?如果加在中间,那么这个异常处理器后面的 Handler 抛出的异常都处理不了。
6.2 Outbound 异常的传播
a. Outbound 异常的产生
对于 Outbound 事件传播过程中所发生的异常,加到 ChannelPipeline 中双向链表最后的 ExceptionHandler 也能处理,为什么?
我们以前面提到的 writeAndFlush() 方法为例,来看看 Outbound 事件传播过程中的异常最后是如何落到 ExceptionHandler 中去的。
前面我们已经知道,channel.writeAndFlush() 方法最终也会调用 AbstractChannelHandlerContext 的 invokeFlush0() 方法。
private void invokeFlush0() {
try {
((ChannelOutboundHandler) handler()).flush(this);
} catch (Throwable t) {
notifyHandlerException(t);
}
}
invokeFlush0() 会委托其内部的 ChannelHandler 的 flush() 方法。这个过程中,可能会产生异常。
b. Outbound 异常的处理
假设当前节点在 flush 过程中发生了异常,进入 notifyHandlerException(t) 方法来处理,该方法和 Inbound 事件传播过程中的异常传播方法一样,也是轮流找下一个异常处理器。而如果异常处理器在 ChannelPipeline 最后面,则一定会被执行到,这也就是为什么该异常处理器也能处理 Outbound 异常的原因。
【小结】关于为什么 ExceptionHandler既能处理 Inbound 事件过程中的异常,又能处理传播 Outbound 事件过程中的异常,总结一点就是:在任何节点中发生的异常都会向下一个节点传递,最后终究会传递到异常处理器。
7. 总结
- 以新连接的接入流程为例,在新连接创建的过程中创建了 Channel,而在创建 Channel 的过程中创建了该 Channel 对应的 ChannelPipeline;
- 创建完 ChannelPipeline 之后,给该 ChannelPipeline 添加了两个节点 HeadContext 和 TailContext,每个节点的数据结构都是 ChannelHandlerContext 类型的,ChannelHandlerContext 中拥有 ChannelPipeline 和 Channel 所有的上下文信息;
- ChannelPipeline 是双向链表结构,添加和删除节点均只需要调整链表结构;
- ChannelPipeline 中的每个节点都包着具体的处理器 ChannelHandler,节点根据 ChannelHandler 的类型是 ChannelInboundHandler 还是 ChannelOutboundHandler 来判断该节点属于 Inbound 类型还是 Outbound 类型,或者两者都是;
- 一个 Channel 对应一个 Unsafe,Unsafe 处理底层 IO 操作,NioServerSocketChannel 对应 NioMessageUnsafe,NioSocketChannel 对应 NioByteUnsafe;
- Inbound 事件从 HeadContext 节点传播到 TailContext 节点,Outbound 事件从 TailContext 节点传播到 HeadContext 节点;
- 异常在 ChannelPipeline 中的双向链表中传播时,无论 Inbound 节点还是 Outbound 节点,都是向下一个节点传播,直到 TailContext 节点。