1. 分布式文件系统
分布式文件系统(Distributed File System,DFS)又叫做网络文件系统(Network File System)。一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
【特点】在一个分享的磁盘文件系统中,所有节点对数据存储区块都有相同的访问权,在这样的系统中,访问权限就必须由客户端程序来控制。分布式文件系统可能包含的功能有:透通的数据复制与容错。
【区别】分布式文件系统是被设计用在局域网。而分布式数据存储,则是泛指应用分布式运算技术的文件和数据库等提供数据存储服务的系统。
FastDFS 是一个开源的轻量级分布式文件系统,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合中小文件(建议范围:4KB < file_size < 500MB),对以文件为载体的在线服务,如相册网站、视频网站等。
2. 系统架构
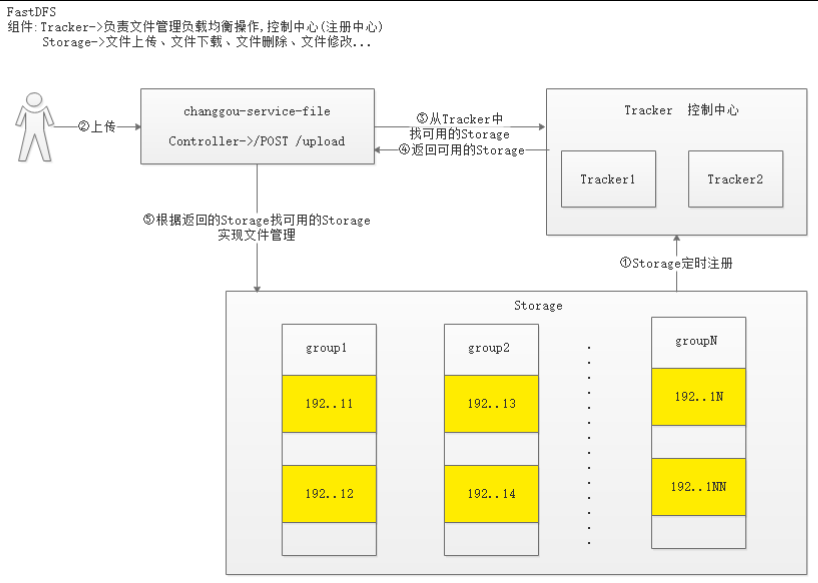
FastDFS 架构包括「跟踪服务器 Tracker Server」、「存储服务器Storage Server」和「客户端 Client」构成。Client 请求 Tracker Server 进行文件上传、下载,经 Tracker Server 调度,最终由 Storage Server 完成文件上传和下载。
- 跟踪服务器 Tracker Server
- 主要做调度工作,起到均衡的作用;负责管理所有的 Storage 和 Group,每个 Storage 在启动后会连接 Tracker,告知自己所属 Group 等信息并保持周期性心跳。Tracker 根据 Storage 的心跳信息,建立 Group → [StorageServer List] 的映射表。
- Tracker 需要管理的元信息很少,会全部存储在内存中;另外 Tracker 上的元信息都是由 Storage 汇报的信息生成的,本身不需要持久化任何数据,这样使得 Tracker 非常容易扩展,直接增加 Tracker 机器即可扩展为 Tracker Cluster 来服务,Cluster 里每个 Tracker 之间是完全对等的,所有的 Tracker 都接受 Stroage 的心跳信息,生成元数据信息来提供读写服务。
- 存储服务器 Storage Server
- 主要提供容量和备份服务;以 Group 为单位,每个 Group 内可以有多台 Storage Server,数据互为备份(不分主从~)。以 Group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制(Group 内 Storage Server 数量即为该 Group 的副本数),比如将不同应用数据存到不同的 Group 就能隔离应用数据,同时还可根据应用的访问特性来将应用分配到不同的 Group 来做负载均衡;缺点是 Group 的容量受单机存储容量的限制,同时当 Group 内有机器坏掉时,数据恢复只能依赖 Group 内地其他机器,使得恢复时间会很长。
- Group 内每个 Storage 的存储依赖于本地文件系统,Storage 可配置多个数据存储目录,比如有 10 块磁盘,分别挂载在 /data/disk1 ~ /data/disk10,则可将这 10 个目录都配置为 Storage 的数据存储目录。Storage 接受到写文件请求时,会根据配置好的规则选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在 Storage 第一次启动时,会在每个数据存储目录里创建 2 级子目录,每级 256 个,总共 65536 个文件,新写的文件会以 hash 的方式被路由到其中某个子目录下,然后将文件数据作为本地文件存储到该目录中。
- 客户端 Client
- 主要是上传下载数据的服务器,也就是我们自己的项目所部署在的服务器;
- 每个 Client 服务器都需要安装 Nginx。
3. FastDFS 的存储策略
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。

在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
4. FastDFS 常见流程
4.1 上传
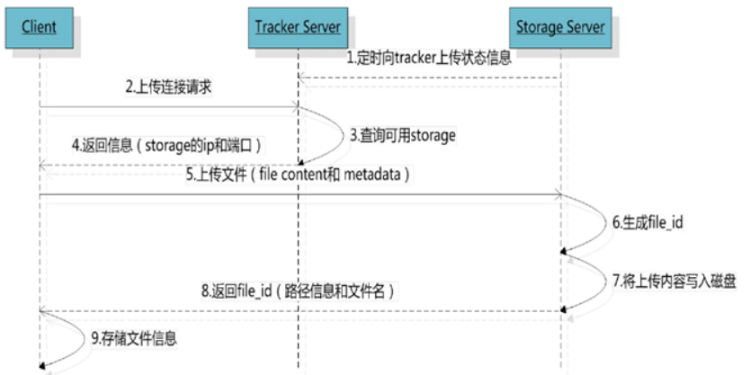
客户端上传文件后存储服务器将文件 ID 返回给客户端,此文件 ID 用于以后访问该文件的索引信息。文件索引信息包括:组名、虚拟磁盘路径、数据两级目录、文件名。

- 【组名】文件上传后所在的 Storage 组名称,在文件上传成功后有 Storage 服务器返回,需要客户端自行保存;
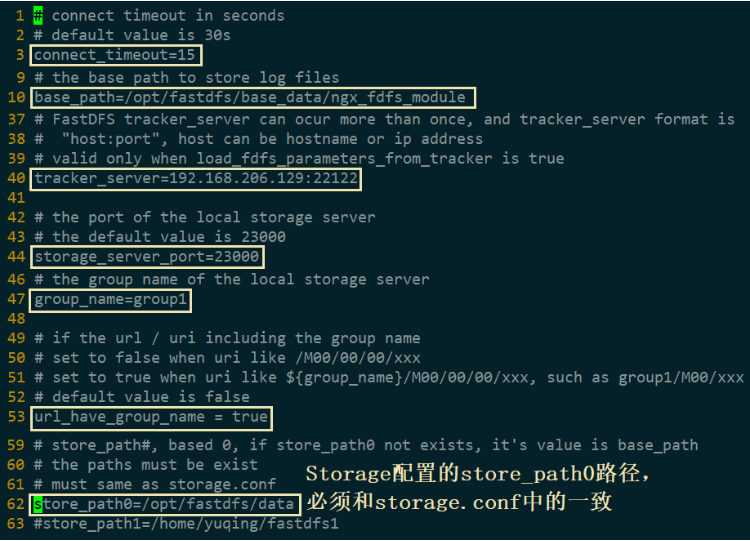
- 【虚拟磁盘路径】Storage 配置的虚拟路径,与磁盘选项 store_path* 对应。如果配置了 store_path0 则是 M00,如果配置了 store_path1 则是 M01,以此类推;
- 【数据两级目录】Storage 服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
- 【文件名】与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器 IP 地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
4.2 同步
写文件时,客户端将文件写至 Group 内一个 Storage Server 即认为写文件成功,Storage Server 写完文件后,会由后台线程将文件同步至同 Group 内其他的 Storage Server。
每个 Storage 写文件后,同时会写一份 Binlog,Binlog 里不包含文件数据,只包含文件名等元信息,这份 Binlog 用于后台同步,Storage 会记录向 Group 内其他 Storage 同步的进度,以便重启后能接上次的进度继续同步;进度以“时间戳”的方式进行记录,所以最好能保证集群内所有 Server 的时钟保持同步。
Storage 的同步进度会作为元数据的一部分汇报到 Tracker 上,Tracker 在选择读 Storage 的时候会以“同步进度”作为参考。
4.3 下载
客户端 uploadFile 成功后,会拿到一个 Storage 生成的文件名,接下来客户端根据这个文件名即可访问到该文件。
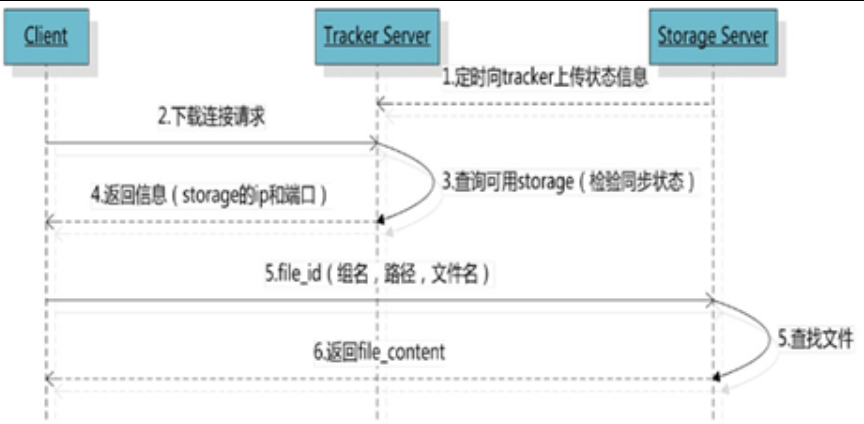
跟 uploadFile 一样,在 downloadFile 时客户端可以选择任意 Tracker Server。Tracker 发送 download 请求给某个 Tracker,必须带上文件名信息,Tracker 从文件名中解析出文件的 Group、大小、创建时间等信息,然后为该请求选择一个 Storage 用来服务读请求。
5. 搭建环境

- https://github.com/happyfish100/libfastcommon/releases
- https://github.com/happyfish100/fastdfs/releases
- http://nginx.org/download/nginx-1.12.0.tar.gz
- https://github.com/happyfish100/fastdfs-nginx-module/releases
5.1 FastDFS
5.1.1 安装依赖库
(1)安装 libevent 事件通知函数库:yum -y install libevent
(2)安装 libfastcommon,它是从 FastDFS 和 FastDHT 中提取出来的公共 C 函数库,基础环境。
a. 解压 libfastcommon:tar -xzvf libfastcommon-1.0.43.tar.gz
b. 进入目录,编译 ./make.sh,然后安装 ./make.sh install
安装的时候控制台的打印会有讲到,会默认装到 /usr/lib64 下面,我忘截图了,下图是网上找的:

cd 到 /usr/lib64 下,查看相关文件:

libfastcommon.so 安装到了/usr/lib64/libfastcommon.so,但是 FastDFS 主程序设置的 lib 目录是 /usr/lib,所以需要创建软链接(这里不用了,我用的这个版本已经把这事给做了)。
5.1.1 安装 FastDFS
(1)解压 fastdfs-5.12.zip:unzip fastdfs-5.12.zip

(2)仍然是进入加压目录,编译 ./make.sh 然后安装 ./make.sh install,默认会安装在 /usr/bin 目录下:

(3)除了 fastdfs-5.12/conf 之外,还有一部分配置文件在 /etc/fdfs 下,现都给它并到 /etc/fdfs 下:

5.1.2 配置 FastDFS
注意,下面出现的目录配置,都要你自己先建好。
(1)tracker.conf:Tracker 数据和日志目录地址(根目录必须存在,子目录会自动创建)

(2)storage.conf
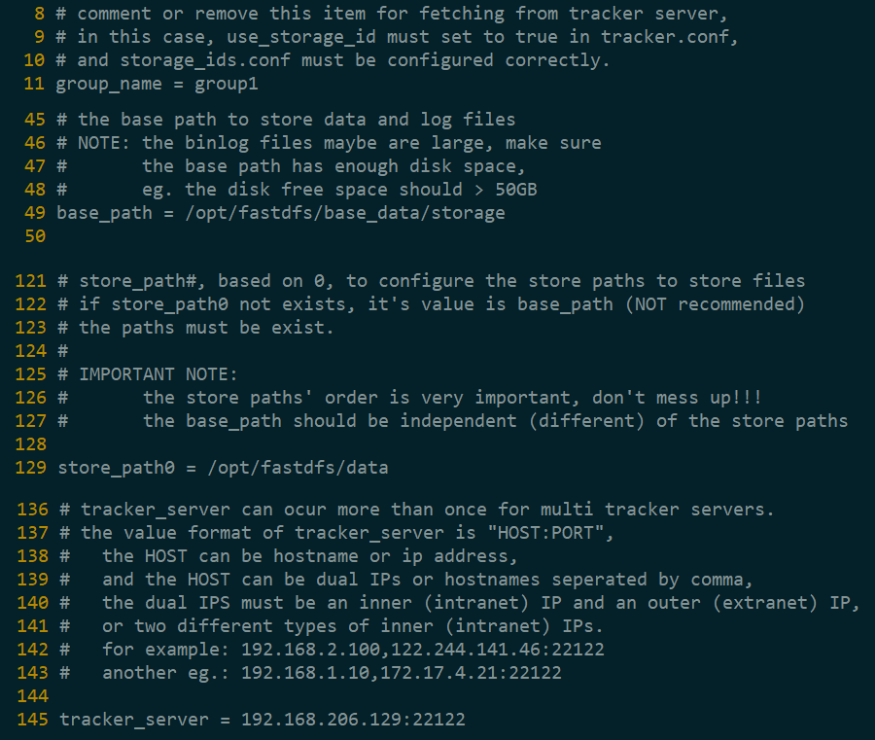
(3)client.conf
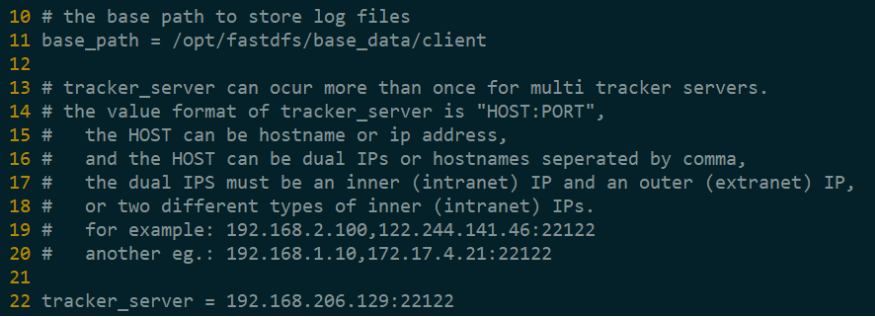
5.1.3 运行 FastDFS

服务的启动都是“服务名+配置文件名”的形式:首先启动 fdfs_trackerd 服务 fdfs_trackerd /etc/fdfs/tracker.conf,然后启动 fdfs_storage 服务 fdfs_storaged /etc/fdfs/storage.conf。

通过 fdfs_monitor 查看 Storage 和 Tracker 是否在通信:
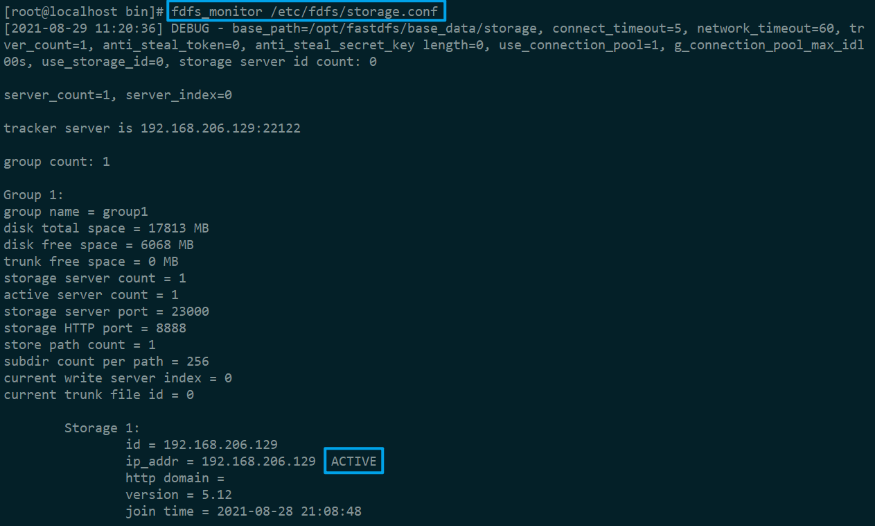
再通过 fdfs_test 简单测试一下文件上传:

根据返回的 url 去 store_path0 下找一下这张图片:
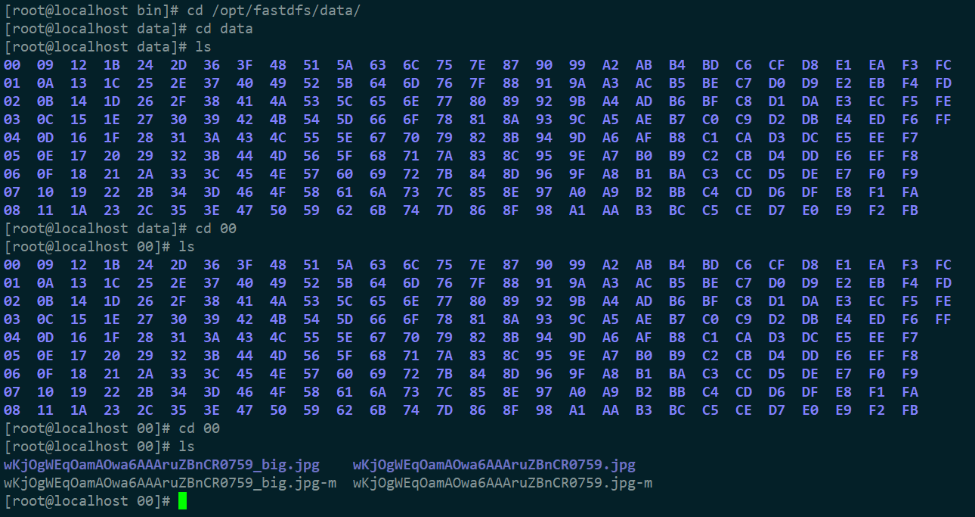
但目前通过这个 url 并不能实现在浏览器中访问,因为没有配置 Nginx ~
5.2 Nginx
上面将文件上传成功了,但我们无法下载。因此安装 Nginx 作为服务器以支持 HTTP 方式访问文件。同时,后面安装 FastDFS 的 Nginx 模块也需要 Nginx 环境。
Nginx 只需要安装到 Storage 所在的服务器即可,用于访问文件。我这里由于是单机,TrackerServer 和 StorageServer 在一台服务器上。
5.2.1 安装依赖库
- GCC:
yum install gcc-c++ - PCRE pcre-devel(正则解析):
yum install -y pcre pcre-devel - zlib(数据压缩):
yum install -y zlib zlib-devel - OpenSSL(安全|加密):
yum install -y openssl openssl-devel
5.2.2 安装 Nginx
(1)解压 tar -xzvf nginx-1.12.0.tar.gz
(2)使用默认配置 ./configure
(3)编译 make,安装 make install
(4)启动 Nginx

(5)简单的测试访问文件:首先修改 nginx.conf,然后重启 Nginx,最后用浏览器访问~


5.2.2 fastdfs-nginx-module
FastDFS 通过 Tracker 服务器,将文件放在 Storage 服务器存储, 但是同组存储服务器之间需要进行文件复制, 有同步延迟的问题。
现假设 Tracker 服务器将文件上传到了 192.168.206.129,上传成功后文件 ID 已经返回给客户端。此时 FastDFS 存储集群机制会将这个文件同步到同组存储 192.168.206.128,在文件还没有复制完成的情况下,客户端如果用这个文件 ID 在 192.168.206.128 上取文件,就会出现文件无法访问的错误。
fastdfs-nginx-module 可以重定向文件链接到源服务器取文件,避免客户端由于复制延迟导致的文件无法访问错误。
(1)先停掉 Nginx:/usr/local/nginx/sbin/nginx -s stop
(2)解压 fastdfs-nginx-module
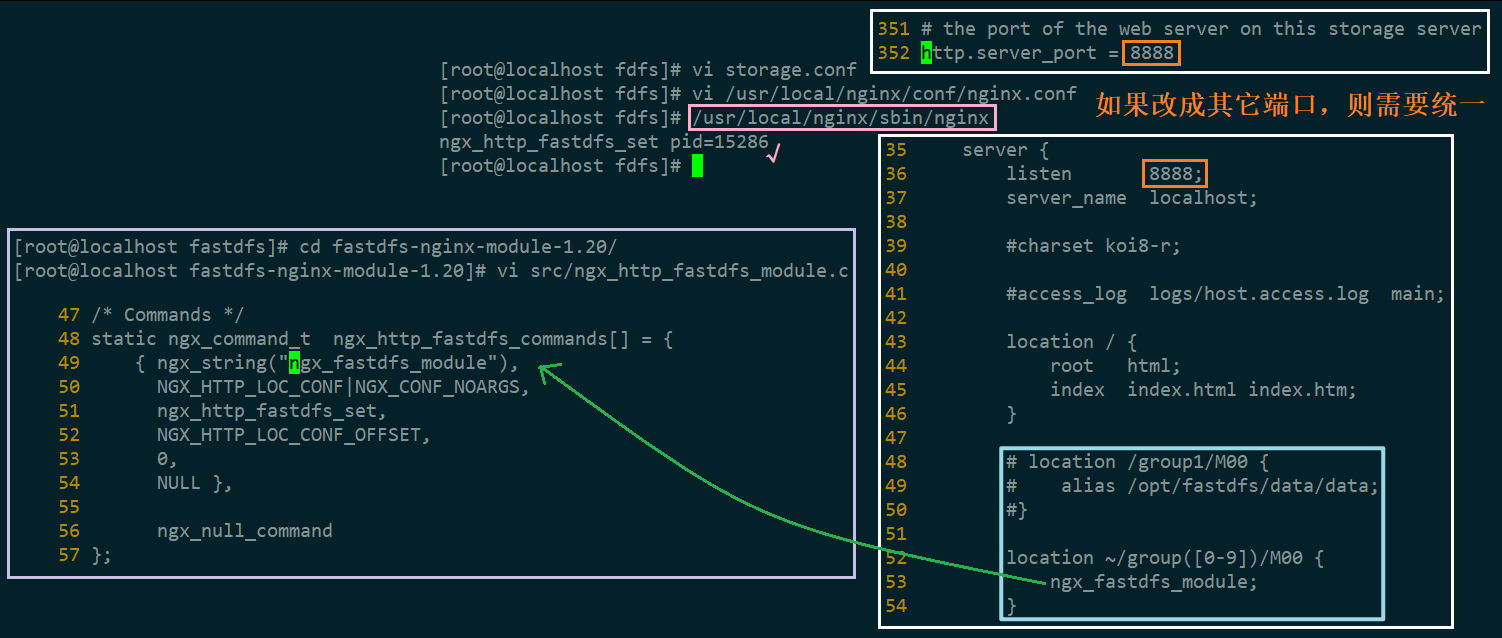
(3)进入 Nginx 目录,给 Nginx 添加模块:./configure --add-module=../fastdfs-nginx-module-1.20/src
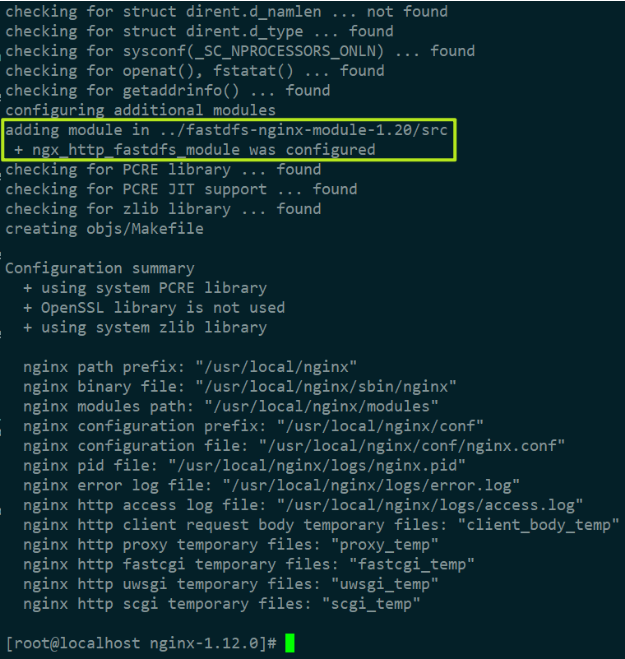
(4)重新编译 make、安装 make install Nginx 后,查看 Nginx 版本和配置:

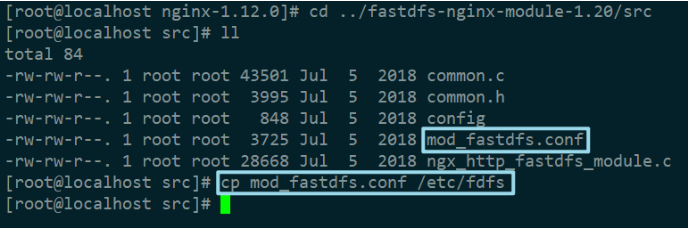
(5)复制 fastdfs-nginx-module/src 中的配置文件到 /etc/fdfs 目录
(6)修改 mod_fastdfs.conf
(7)修改 nginx.conf,然后启动 Nginx
(8)再去访问那张图,也是 OK 的 ~

6. fastdfs-op
6.1 配置和依赖
(1)Maven 依赖
<dependency>
<groupId>org.csource</groupId>
<artifactId>fastdfs-client-java</artifactId>
<version>1.27</version>
</dependency>
(2)application-dev.properties
fastdfs.connect_timeout_in_seconds = 5
fastdfs.network_timeout_in_seconds = 30
fastdfs.charset = UTF-8
fastdfs.http_anti_steal_token = false
fastdfs.http_tracker_http_port = ${scms.fdfs.nginx.port}
fastdfs.httpIp = ${scms.fdfs.nginx.ip}
fastdfs.httpPort = ${scms.fdfs.nginx.port}
fastdfs.pathHeader = /ZNVFSIMG/
fastdfs.tracker_servers = ${scms.fastdfs.tracker.servers}
fastdfs.reservedStorageSpace = 10%
fastdfs.fileEncrypted= 0
fastdfs.fileExtName = jpg
fastdfs.oldFileIntervalDays = 365
# 0:按时间段 1:按文件个数 其他数值:两者结合
fastdfs.spaceFullDeleteFileMethod = 1
fastdfs.spaceFullDeleteFileDays = 90
fastdfs.spaceFullDeleteFileCnt = 3000
fastdfs.highV =
# 每次批量插入文件记录的最多条数
batch.insert.files.count=2000
#################### ↓ Nacos ↓ ####################
scms.fdfs.nginx.ip=10.45.154.171
scms.fdfs.nginx.port=8888
scms.fastdfs.tracker.servers=10.45.154.171:22122
6.2 Client
- 创建一个访问 Tracker 的客户端对象 TrackerClient;
- 通过 TrackerClient 访问 TrackerServer 服务,获取连接信息;
- 通过 TrackerServer 返回的 Storage 连接信息,创建 StorageClient 对象;
- 通过 StorageClient 访问 StorageServer,实现文件上传,并获取上传后的存储信息。