Java 内存模型是围绕着在并发过程中如何处理原子性、可见性和有序性这三个特征来建立的。简单来说,JMM 定义了一套在多线程读写共享数据时(成员变量、数组)时,对数据的可见性、有序性、和原子性的规则和保障。
1. 并发编程中的三个问题
1.1 可见性
可见性(Visibility):是指一个线程对共享变量进行修改,另一个应立即得到修改后的最新值。
1.1.1 示例
一个线程根据 boolean 类型的标记 flag 进行 while 循环,另一个线程改变这个 flag 变量的值,但另一个线程并没有停止循环。
public class VisibilityTest {
private static boolean run = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
while (run) {
// ...
}
}).start();
Thread.sleep(2000);
new Thread(()->{
run = false;
System.out.println("修改完毕");
}).start();
}
}
补充一句:The main thread must be the last thread to finish execution. When the main thread stops, the program terminates.
1.1.2 小结
当一个线程对共享变量进行了修改并同步至主存,而另外的线程并没有立即看到修改后的最新值,还是在使用自己工作内存中缓存着的共享变量的旧值。

1.2 原子性
原子性(Atomicity):在一次或多次操作中,要么所有的操作都执行且不会受其他因素干扰而中断,要么所有的操作都不执行。
1.2.1 示例
开 5 个线程各自执行 1000 次 i++ 所得到的结果不一定是 5k。
public class AutomaticTest {
private static int number = 0;
public static void main(String[] args) throws InterruptedException {
List<Thread> list = new ArrayList<>();
Runnable r = () -> { for (int i = 0; i < 1000; i++) number ++; };
for (int i = 0; i < 5; i++) {
Thread t = new Thread(r);
t.start();
list.add(t);
}
for (Thread t : list) t.join();
System.out.println("number = " + number); // 4819, 5000, 4646
}
}
使用 javap -p -v AutomaticTest.class 反汇编 class 文件,得到下面的字节码指令。其中,对于 number++ 而言(number 为静态变量),实际会产生如下 4 条 JVM 字节码指令。

问题就出在自增运算“number++”之中,我们用 javap 反编译这段代码后会得到如上代码,发现 number++ 在 Class 文件中是由 4 条字节码指令构成,从字节码层面上已经很容易分析出并发失败的原因了。
以上多条指令在一个线程的情况下是不会出问题的,但是在多线程情况下就可能会出现问题。比如一个线程在执行 13: iadd 时,另一个线程又执行 9: getstatic。会导致两次 number++,实际上只加了 1。
1.2.2 小结
并发编程时,会出现原子性问题,当一个线程对共享变量操作到一半时,另外的线程也有可能来操作共享变量,干扰了前一个线程的操作(结果就是可能会出现数据丢失)。
1.3 有序性
有序性(Ordering):是指程序中代码的执行顺序,Java 在编译时和运行时会对代码进行优化,会导致程序最终的执行顺序不一定就是我们编写代码时的顺序。
1.3.1 示例
使用 Java 并发压测工具 jcstress 来进行测试
(1) 先修改 pom 文件,添加依赖
<dependency>
<groupId>org.openjdk.jcstress</groupId>
<artifactId>jcstress-core</artifactId>
<version>0.3</version>
</dependency>
(2) 测试代码
@JCStressTest
@Outcome(id={"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id="0", expect = Expect.ACCEPTABLE_INTERESTING, desc="danger")
@State
public class OrderingTest {
int num = 0;
boolean ready = false;
@Actor // Thread-1 执行的代码
public void actor1(I_Result r) {
if (ready) r.r1 = num + num;
else r.r1 = 1;
}
@Actor // Thread-2 执行的代码
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
(3) 运行测试
mvn clean install
java -jar target/jcstress.jar
(4) I_Result 是一个对象,有一个属性 r1 用来保存结果,在多线程情况下可能出现几种结果?

- Thread-1 先执行 actor1,这时 ready = false,所以进入 else 分支结果为 1。
- Thread-2 执行到 actor2,执行了 num = 2 和 ready = true;接着 Thread-1 执行,这回进入 if 分支,结果为 4。
- Thread-2 先执行 actor2,只执行 num = 2 但没来得及执行 ready = true;轮到 Thread-1 执行,还是进入 else 分支,结果为 1。
- 还有一种结果 0 → 因为 actor2 的方法体就是两个毫无关系的变量赋值操作,Java 在编译期和运行期的优化,有可能会导致代码重排序,即:L17 和 L18 顺序颠倒。
1.3.2 小结
程序代码在执行过程中的先后顺序,由于 Java 在编译期以及运行期的优化,导致了代码的执行顺序未必就是开发者编写代码时的顺序。
2. Java 内存模型
虚拟机如何实现多线程、多线程之间由于共享和竞争数据而导致的一系列问题及解决方案。
2.1 计算机内存结构
2.1.1 引入缓存
在引出 JMM 之前,先来看一下到底什么是「计算机内存模型」。

CPU 的运算速度和内存的访问速度相差比较大。这就导致 CPU 每次操作内存都要耗费很多等待时间。内存的读写速度成为了计算机运行的瓶颈。于是就有了在 CPU 和主内存之间增加缓存的设计。最靠近 CPU 的缓存称为 L1,然后依次是 L2,L3 和主内存,CPU 缓存模型如图下图所示。

CPU Cache 分成了三个级别:L1, L2, L3。级别越小越接近 CPU,速度也更快,同时也代表着容量越小。
- L1 是最接近 CPU 的,它容量最小,例如 32K,速度最快,每个核上都有一个 L1 Cache。
- L2 Cache 更大一些,例如 256K,速度要慢一些,一般情况下每个核上都有一个独立的 L2 Cache。
- L3 Cache 是三级缓存中最大的一级,例如 12MB,同时也是缓存中最慢的一级,在同一个 CPU 插槽之间的核共享一个 L3 Cache。

Cache 的出现是为了解决 CPU 直接访问内存效率低下问题的,程序在运行的过程中,CPU 接收到指令后,它会最先向 CPU 中的一级缓存(L1 Cache)去寻找相关的数据,如果命中缓存,CPU 进行计算时就可以直接对 CPU Cache 中的数据进行读取和写入,当运算结束之后,再将 CPU Cache 中的最新数据刷新到主内存当中,CPU 通过直接访问 Cache 的方式替代直接访问主存的方式极大地提高了 CPU 的吞吐能力。但是由于一级缓存(L1 Cache)容量较小,所以不可能每次都命中。这时 CPU 会继续向下一级的二级缓存(L2 Cache)寻找,同样的道理,当所需要的数据在二级缓存中也没有的话,会继续转向 L3 Cache、内存(主存)和硬盘。
基于高速缓存的存储交互很好地解决了处理器与内存速度之间的矛盾,但是也为计算机系统带来更高的复杂度,它引入了一个新的问题:缓存一致性(Cache Coherence)。
2.1.2 缓存一致性问题
多路处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存(Main Memory),这种系统称为共享内存多核系统(Shared Memory Multiprocessors System),如图所示。

当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致。如果真的发生这种情况,那同步回到主内存时该以谁的缓存数据为准呢?为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有 MSI、MESI(Illinois Protocol)、MOSI、Synapse、Firefly 及 Dragon Protocol 等。
从这儿开始,我们将会频繁见到「内存模型」一词,它可以理解为在特定的操作协议下,对特定的内存或高速缓存进行读写访问的过程抽象。不同架构的物理机器可以拥有不一样的内存模型,而 Java 虚拟机也有自己的内存模型(JMM),并且与这里介绍的内存访问操作及硬件的缓存访问操作具有高度的可类比性。
除了增加高速缓存之外,为了使处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行(Out-Of-Order Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致,因此如果存在一个计算任务依赖另外一个计算任务的中间结果,那么其顺序性并不能靠代码的先后顺序来保证。与处理器的乱序执行优化类似,Java 虚拟机的即时编译器中也有指令重排序(Instruction Reorder)优化。← 并发编程Q3~有序性!
2.2 JMM 概述
Java 内存模型(Java Memory Molde,JMM),是 Java 虚拟机规范中所定义的一种内存模型,Java 内存模型是标准化的,来屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
Java 内存模型是一套规范,描述了 Java 程序中各种变量(线程共享变量)的访问规则,以及在 JVM 中将变量存储到内存和从内存中读取变量这样的底层细节,具体如下。
- 【主内存】主内存是所有线程都共享的,都能访问的。所有的变量都存储在主内存(Main Memory)中(此处的主内存与介绍物理硬件时提到的主内存名字一样,两者也可以类比,但物理上它仅是虚拟机内存的一部分)。
- 【工作内存】每条线程还有自己的工作内存(Working Memory,可与前面讲的处理器高速缓存类比),线程的工作内存中保存了被该线程使用的变量的主内存副本,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的数据。
不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存、工作内存三者的交互关系如下图所示。

注意:
- 如果局部变量是一个 reference 类型,它引用的对象在 Java 堆中可被各个线程共享,但是 reference 本身在 Java 栈的局部变量表中,是线程私有的。
- “假设线程中访问一个 10MB 大小的对象,也会把这 10MB 的内存复制一份出来吗?”,事实上并不会如此,这个对象的引用、对象中某个在线程访问到的字段是有可能被复制的,但不会有虚拟机把整个对象复制一次。
- 根据《Java 虚拟机规范》的约定,volatile 变量依然有工作内存的拷贝,但是由于它特殊的操作顺序性规定(后文会讲到),所以看起来如同直接在主内存中读写访问一般,因此这里的描述对于 volatile 也并不存在例外。
- 除了实例数据,Java 堆还保存了对象的其他信息,对于 HotSpot 虚拟机来讲,有 Mark Word(存储对象哈希码、GC 标志、GC 年龄、同步锁等信息)、Klass Point(指向存储类型元数据的指针)及一些用于字节对齐补白的填充数据(如果实例数据刚好满足 8 字节对齐,则可以不存在补白)。
2.3 缓存,内存与 JMM 的关系
通过对前面的 CPU 硬件内存架构、Java 内存模型以及 Java 多线程的实现原理的了解,我们应该已经意识到,多线程的执行最终都会映射到硬件处理器上进行执行。
但 Java 内存模型和硬件内存架构并不完全一致。对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存和主内存之分,也就是说 Java 内存模型对内存的划分对硬件内存并没有任何影响,因为 JMM 只是一种抽象的概念,是一组规则,不管是工作内存的数据还是主内存的数据,对于计算机硬件来说都会存储在计算机主内存中,当然也有可能存储到 CPU 缓存或者寄存器中。
这里所讲的主内存、工作内存与第 2 章所讲的 Java 内存区域中的 Java 堆、栈、方法区等并不是同一个层次的对内存的划分,这两者基本上是没有任何关系的。
如果两者一定要勉强对应起来,那么从变量、主内存、工作内存的定义来看,主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域。
从更基础的层次上说,主内存直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机(或者是硬件、操作系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问的是工作内存。
因此总体上来说,Java 内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。

Java 内存模型是一套规范,描述了 Java 程序中各种变量(线程共享变量) 的访问规则,以及在 JVM 中将变量存储到内存和从内存中读取变量这样的底层细节,Java 内存模型是对共享数据的可见性、有序性、和原子性的规则和保障。
2.4 主内存与工作内存之间的交互
目标了解主内存与工作内存之间的数据交互过程 JMM 中定义了以下 8 种操作来完成,主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存之类的实现细节,虚拟机实现时必须保证下面提及的每一种操作都是原子的、不可再分的。

- 如果某线程对一个变量执行
lock操作,将会清空该线程工作内存中此变量的值,获取最新值。 - 对一个变量执行
unlock操作之前,必须先把此变量同步到主内存中。
- 主内存的操作
- lock 锁定:作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
- unlock 解锁:作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- 工作内存的操作(和执行引擎的交互)
- use 使用:作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign 赋值:作用于工作内存的变量,它把一个从执行引擎接收的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- 主内存和工作内存的同步操作
- 主内存 → 工作内存
- read 读取:作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的 load 动作使用。
- load 载入:作用于工作内存的变量,它把 read 操作从主内存中得到的变量值放入工作内存的变量副本中。
- 工作内存 → 主内存
- store 存储:作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的 write 操作使用。
- write 写入:作用于主内存的变量,它把 store 操作从工作内存中得到的变量的值放入主内存的变量中。
- 主内存 → 工作内存
如果要把一个变量从主内存拷贝到工作内存,那就要按顺序执行 read 和 load 操作,如果要把变量从工作内存同步回主内存,就要按顺序执行 store 和 write 操作。注意,Java 内存模型只要求上述两个操作必须按顺序执行,但不要求是连续执行!也就是说 read 与 load 之间、store 与 write 之间是可插入其他指令的,如对主内存中的变量 a、b 进行访问时,一种可能出现的顺序是 read a、read b、load b、load a。
除此之外,Java 内存模型还规定了在执行上述 8 种基本操作时必须满足如下规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者工作内存发起回写了但主内存不接受的情况出现。
- 不允许一个线程丢弃它最近的 assign 操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从线程的工作内存同步回主内存中。
- 一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load 或 assign)的变量,换句话说就是对一个变量实施 use、store 操作之前,必须先执行 assign 和 load 操作。
- 一个变量在同一个时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁。
- 如果对一个变量执行 lock 操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作以初始化变量的值。
- 如果一个变量事先没有被 lock 操作锁定,那就不允许对它执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量。
- 对一个变量执行 unlock 操作之前,必须先把此变量同步回主内存中(执行 store、write 操作)。
这 8 种内存访问操作以及上述规则限定,再加上稍后会介绍的专门针对 volatile 的一些特殊规定,就已经能准确地描述出 Java 程序中哪些内存访问操作在并发下才是安全的。
主内存与工作内存之间的数据交互过程:(lock) -> read -> load -> use -> assign -> store -> write -> (unlock)。
3. volatile
关键字 volatile 可以说是 Java 虚拟机提供的最轻量级的同步机制。当一个变量被定义成 volatile 之后,它将具备两项特性:① 保证此变量对所有线程的可见性(volatile 的英文释义就是“易变的”);② 禁止指令重排序优化(保证有序性)。
3.1 保证可见性
这里的“可见性”是指当一条线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的。而普通变量并不能做到这一点,普通变量的值在线程间传递时均需要通过主内存来完成。比如,Thread-A 修改一个普通变量的值,然后向主内存进行回写,另外一条 Thread-B 在 Thread-A 回写完成了之后再对主内存进行读取操作,新变量值才会对 Thread-B 可见。
volatile 变量对所有线程是立即可见的,对 volatile 变量所有的写操作都能立刻反映到其他线程之中。但是并不能得出“基于 volatile 变量的运算在并发下是线程安全的”这样的结论。
volatile 变量在各个线程的工作内存中是不存在一致性问题的(从物理存储的角度看,各个线程的工作内存中 volatile 变量也可以存在不一致的情况,但由于每次使用之前都要先刷新,执行引擎看不到不一致的情况,因此可以认为不存在一致性问题),但是 Java 里面的运算操作符并非原子操作,这导致 volatile 变量的运算在并发下一样是不安全的(不能保证原子性)。
如 1.3 节的示例代码,就算给 number 变量加上 volatile 关键字。当 getstatic 指令把 number 的值取到操作栈顶时,volatile 关键字虽然保证了 number 的值在此时是正确的,但是在执行 iconst_1、iadd 这些指令的时候,有可能切换到其他线程去把 number 的值改变,而操作栈顶的值此时就变成了过期的数据,所以 putstatic 指令执行后就可能把较小的 number 值同步回主内存之中。
由于 volatile 变量只能保证可见性,所以仍然要通过加锁(使用 synchronized、juc 包中的锁或原子类)来保证原子性。
3.2 禁止指令重排
普通的变量仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致。因为在同一个线程的方法执行过程中无法感知到这点,这就是 Java 内存模型中描述的所谓“线程内表现为串行的语义”(Within-Thread As-If-Serial Semantics:不管编译器和 CPU 如何重排序,必须保证在单线程情况下程序的结果是正确的)。
内存屏障(Memory Barrier)是一种 CPU 指令,维基百科给出了如下定义:内存屏障也称为“内存栅栏” 或“栅栏指令”,是一种屏障指令,它使 CPU 或编译器对屏障指令之前和之后发出的内存操作执行一个排序约束,禁止在内存屏障前后的指令执行重排序优化。 这通常意味着在屏障之前发布的操作被保证在屏障之后发布的操作之前执行。内存屏障的另一个作用是强制刷出各种 CPU 的缓存数据,因此,任何 CPU 上的线程都能读取到这些数据的最新版本。
内存屏障共分为 4 种类型:
- LoadLoad 屏障
- 抽象场景:Load1; LoadLoad; Load2
- Load1 和 Load2 代表两条读取指令。在 Load2 要读取的数据被访问前,保证 Load1 要读取的数据被读取完毕。
- StoreStore 屏障
- 抽象场景:Store1; StoreStore; Store2
- Store1 和 Store2 代表两条写入指令。在 Store2 写入执行前,保证 Store1 的写入操作对其它处理器可见。
- LoadStore 屏障
- 抽象场景:Load1; LoadStore; Store2
- 在 Store2 被写入前,保证 Load1 要读取的数据被读取完毕。
- StoreLoad 屏障
- 抽象场景:Store1; StoreLoad; Load2
- 在 Load2 读取操作执行前,保证 Store1 的写入对所有处理器可见。StoreLoad 屏障的开销是 4 种屏障中最大的。
volatile 做了什么?在一个变量被 volatile 修饰后,JVM 会为我们做 2 件事:
- 在每个 volatile 读操作前插入 LoadLoad 屏障(从主内存中读取共享变量),在读操作后插入 LoadStore 屏障。
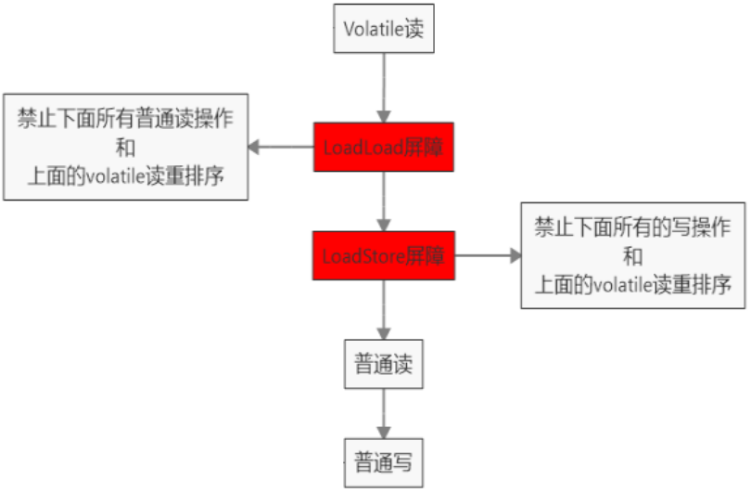
- 在每个 volatile 写操作前插入 StoreStore 屏障,在写操作后插入 StoreLoad 屏障(将工作内存中的共享变量值刷新回到主内存)。
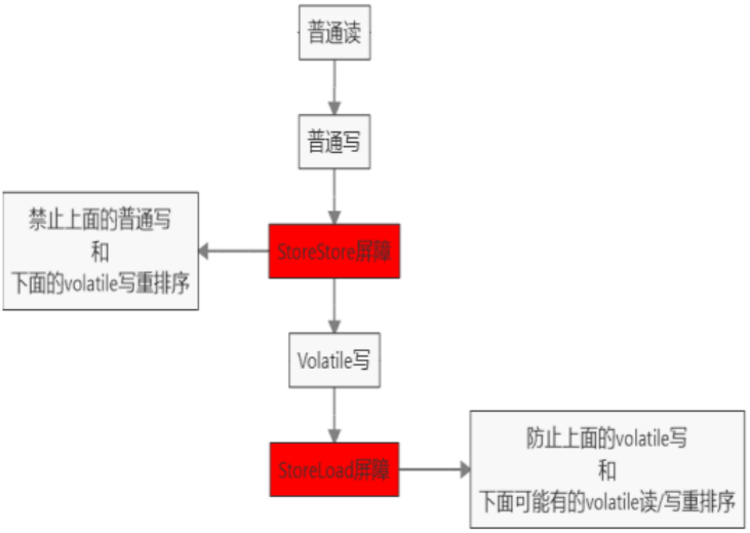
上面说的都是理论,实际 volatile 的实现可不是这样(但肯定能达到相同效果)。下面举例来说下 volatile 的具体实现。
如图是一段标准的双锁检测(Double Check Lock,DCL)单例代码,先来看下 new 操作对应的字节码:
0: new #3 // class cn/edu/nusit/DCLSingleton(分配空间,将引用放入操作数栈顶)
3: dup // (将引用复制一份,栈顶就有两个引用了,然后分别交给如下两个操作去使用)
4: invokespecial #4 // Method "<init>":()V(初始化)
7: putstatic #2 // Field singleton:Lcn/edu/nusit/DCLSingleton;(给静态属性赋值)
其中 4、7 两步是有可能发生指令重排的,如果不用 volatile 修饰变量,多线程环境下就可能会因为指令重排,导致如下后果(红字部分):

但当加入 volatile 关键字后,这段对 instance 变量赋值的汇编代码部分对比未加入 volatile 时所生成的汇编代码的关键变化在于有 volatile 修饰的变量,赋值后多执行了一个 lock ... 操作,这个操作的作用相当于一个内存屏障(Memory Barrier 或 Memory Fence,指重排序时不能把后面的指令重排序到内存屏障之前的位置,注意不要与垃圾收集器用于捕获变量访问的内存屏障互相混淆),只有一个处理器访问内存时,并不需要内存屏障;但如果有两个或更多处理器访问同一块内存,且其中有一个在观测另一个,就需要内存屏障来保证一致性了。
但其实 lock 不是一种内存屏障,但是它能完成类似内存屏障的功能(lock 指令前缀:总线锁,可以对 CPU 总线和高速缓存加锁)。实际上 HotSpot 关于 volatile 的实现就是使用的 lock 指令,只在 volatile 标记的地方加上带 lock 前缀指令操作,并没有参照 JMM 规范的屏障设计而使用对应的 mfence 指令。
结合 DCL 失效说就是,之所以 DCL 失效就是因为初始化成员还没执行就先执行了指向分配的内存,这样我们的实例已经不为 null 了,就导致后面的线程可能拿到没初始化的实例。而加了 volatile 之后,汇编代码因此就多了 lock 前缀,把前面步骤锁住了,如此一来,如果你前面的步骤没做完是无法执行最后一步同步到内存的。换句话说,如果执行到最后一步 lock,说明前面的操作必定都完成了,这样便形成了“指令重排序无法越过内存屏障”的效果。
注意!这里我们就可以看到此内存屏障只保证 lock 前后的顺序不颠倒,但是并没有保证前面的所有顺序都是要顺序执行的,比如我有 1 2 3 4 5 6 7 步,而 lock 在 4 步,那么前面 123 是可以乱序的,只要 123 乱序执行的结果和顺序执行是一样的,后面的 567 也是一样可以乱序的,但是整体上我们是顺序的,把 123 看成一个整体,4 是一个整体,567 又是一个整体,所以整体上我们的顺序的执行的,也达到了看起来禁止重排的效果。
所以,其实“内存屏障禁止重排“就是利用 lock 把 lock 前面的“整体”锁住,当前面的完成了之后 lock 后面“整体”的才能完成,当写完成后,释放锁,把缓存刷新到主内存。
https://juejin.cn/post/6844904106251780109#heading-0
https://blog.csdn.net/Soul_wh/article/details/112738149
https://blog.csdn.net/HJsir/article/details/80713783
4. synchronized
4.1 保证同步
Java 内存模型就是围绕着在并发过程中如何处理原子性、可见性和有序性这三个特征来建立的,现在我们再来逐个来看一下 synchronized 是如何保证这三个特性的。
4.1.1 保证原子性
对 number ++; 增加同步代码块后,保证同一时间只有一个线程操作 number ++;,就不会出现安全问题了。
修改示例代码:
public class AutomaticTest {
private static int number = 0;
public static void main(String[] args) throws InterruptedException {
List<Thread> list = new ArrayList<>();
Runnable r = () -> {
for (int i = 0; i < 1000; i++)
// synchronized 保证只有一个线程拿到锁,能够进入同步代码块。
synchronized (AutomaticTest.class) {
number ++;
}
};
for (int i = 0; i < 5; i++) {
Thread t = new Thread(r);
t.start();
list.add(t);
}
for (Thread t : list) t.join();
System.out.println("number = " + number);
}
}
查看 javap -p -v AutomaticTest.class 结果:

如果应用场景需要一个更大范围的原子性保证(经常会遇到),Java 内存模型还提供了 lock 和 unlock 操作来满足这种需求,尽管虚拟机未把 lock 和 unlock 操作直接开放给用户使用,但是却提供了更高层次的字节码指令 monitorenter 和 monitorexit 来隐式地使用这两个操作。这两个字节码指令反映到 Java 代码中就是同步块 —— synchronized 关键字,因此在 synchronized 块之间的操作也具备原子性。
4.1.2 保证可见性
可见性就是指当一个线程修改了共享变量的值时,其他线程能够立即得知这个修改。上文在讲解 volatile 变量的时候我们已详细讨论过这一点。Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值这种依赖主内存作为传递媒介的方式来实现可见性的,无论是普通变量还是 volatile 变量都是如此。
普通变量与 volatile 变量的区别是,volatile 的特殊规则保证了新值能立即同步到主内存,以及每次使用前必须从主内存刷新。因此我们可以说 volatile 保证了多线程操作时变量的可见性,而普通变量则不能保证这一点。
JMM 关于 synchronized 的两条规定:
- 线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新获取最新的值。
- 线程解锁前,必须把共享变量的最新值刷新到主内存中(加锁与解锁需要统一把锁)
修改示例代码:
public class VisibilityTest {
// private static volatile int run = true;
private static boolean run = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (run) {
synchronized (VisibilityTest.class) {}
// System.out.println("run = " + run); 也能达到同样效果
}
}).start();
Thread.sleep(2000);
new Thread(() -> {
run = false;
System.out.println("修改完毕");
}).start();
}
}
上述示例的 while 循环中若加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到对 run 变量的修改了,想一想为什么?
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是 synchronized 是属于重量级操作,性能相对更低。
4.1.3 保证有序性
为什么要重排序?为了提高程序的执行效率,编译器和 CPU 会对程序中代码进行重排序。

「as-if-serial 语义」:不管编译器和 CPU 如何重排序,必须保证在单线程情况下程序的结果是正确的。
// 写后读
int a = 1;
int b = a;
// 写后写
int a = 1;
int a = 2;
// 读后写
int a = 1;
int b = a;
int a = 2;
编译器和处理器不会对存在数据依赖关系的操作(如上述)做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
int a = 1;
int b = 2;
int c = a + b;
上面 3 个操作的数据依赖关系如图所示:

如上图所示 a 和 c 之间存在数据依赖关系,同时 b 和 c 之间也存在数据依赖关系。因此在最终执行的指令序列中,c 不能被重排序到 a 和 b 的前面。但 a 和 b 之间没有数据依赖关系,编译器和处理器可以重排序 a 和 b 之间的执行顺序。下图是该程序的两种执行顺序。

// 可以这样
int a = 1;
int b = 2;
int c = a + b;
// 也可以重排序成这样
int b = 2;
int a = 1;
int c = a + b;
修改示例代码,使用 synchronized 保证有序性。
@JCStressTest
@Outcome(id={"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id="0", expect = Expect.ACCEPTABLE_INTERESTING, desc="danger")
@State
public class OrderingTest {
int num = 0;
boolean ready = false;
@Actor // Thread-1 执行的代码
public void actor1(I_Result r) {
synchronized (OrderingTest.class) {
if (ready) r.r1 = num + num;
else r.r1 = 1;
}
}
@Actor // Thread-2 执行的代码
public void actor2(I_Result r) {
synchronized (OrderingTest.class) {
num = 2;
ready = true;
}
}
}
使用并发测试工具进行测试:

加 synchronized 后,依然会发生重排序,只不过我们有同步代码块,可以保证只有一个线程执行同步代码中的代码,以保证有序性。
面试题:synchronized 到底是如何保证有序性的呢?
- 为了进一步提升计算机各方面能力,在硬件层面做了很多优化,如处理器优化和指令重排等,但是这些技术的引入就会导致有序性问题。
- 最好的解决有序性问题的办法,就是禁止处理器优化和指令重排,就像 volatile 中使用内存屏障一样。
- 但是,虽然很多硬件都会为了优化做一些重排,但是在 Java 中,要求:排可以,但不管怎么排序,都不能影响单线程程序的执行结果。这就是 as-if-serial 语义,所有硬件优化的前提都是必须遵守 as-if-serial 语义。
- synchronized 是 Java 提供的同步关键字,可以通过它对 Java 中的对象加锁,并且他是一种排他的、可重入的锁。
- 所以,当某个线程执行到一段被 synchronized 修饰的代码之前,会先进行加锁,执行完之后再进行解锁。在加锁之后,解锁之前,其他线程是无法再次获得锁的,只有这条加锁线程可以重复获得该锁。
- synchronized 通过排他锁的方式就保证了同一时间内,被 synchronized 修饰的代码是单线程执行的。所以呢,这就满足了 as-if-serial 语义的一个关键前提,那就是单线程,因为有 as-if-serial 语义保证,单线程的有序性就天然存在了。
4.2 synchronized 语义
其实“锁”本身是个对象,synchronized 这个关键字不是“锁”。硬要说的话,“加 synchronized”仅仅是相当于“加锁”这个操作,加锁操作使得 synchronized 代码块中的代码能够实现同步。

我们通常去使用 synchronized 一般都是用在下面这几种场景:
- 修饰实例方法,对当前实例对象 this 加锁
- 修饰静态方法,对当前类的 Class 对象加锁
- 修饰代码块,指定一个加锁的对象,对该对象加锁
其实就是锁方法、锁代码块和锁对象,那他们是怎么实现“加锁”的呢?
javap 查看字节码,可以看到在加锁的代码块附近多了个 monitorenter , monitorexit。Java 虚拟机正是依靠指令集中的 monitorenter 和 monitorexit 两条指令来支持 synchronized 关键字的语义。
4.2.1 monitorenter
每一个对象都会和一个监视器 monitor 关联。监视器被占用时会被锁住,其他线程无法来获取该 monitor。 当 JVM 执行某个线程的某个方法内部的 monitorenter 时,它会尝试去获取当前对象对应的 monitor 的所有权。其过程如下:
- 如果 monitor 的进入数为 0,则该线程进入 monitor,然后将 recursions(进入数)设置为 1,该线程即为 monitor 的所有者;
- 如果线程已经占有该 monitor,只是重新进入,则进入 monitor 的进入数 +1;
- 如果其他线程已经占用了 monitor,则该线程进入阻塞状态,直到 monitor 的进入数为 0,再重新尝试获取 monitor 的所有权。
synchronized 可重入锁(“可重入”是动词),如果当前线程已获得锁对象,可再次获取该锁对象。即:该锁对象的监视器 monitor 具有可重入性,每进入一次,进入次数 +1。
4.2.2 monitorexit
能执行 monitorexit 的线程必须是锁对象所对应的 monitor 的所有者。
- 指令执行时,monitor 的进入数 -1;如果 -1 后进入数为 0,那线程退出 monitor,不再拥有 monitor 的所有权。
- 此时其他被这个 monitor 阻塞的线程可以尝试去获取这个 monitor 的所有权。
通过以上描述,应该能很清楚的看出 synchronized 的实现原理,synchronized 的语义底层是通过一个 monitor 的对象来完成,其实 wait/notify 等方法也依赖于 monitor 对象,这就是为什么只有在同步的块或者方法中才能调用 wait/notify 等方法,否则会抛出 java.lang.IllegalMonitorStateException 的异常的原因。
4.2.3 小结
摘自《Java 虚拟机规范》
Java虚拟机可以支持方法级的同步和方法内部一段指令序列的同步,这两种同步结构都是使用管程(Monitor)来支持的。
方法级的同步是隐式,即无需通过字节码指令来控制的,它实现在方法调用和返回操作之中。虚拟机可以从方法常量池中的方法表结构中的 ACC_SYNCHRONIZED 访问标志区分一个方法是否同步方法。当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有管程,然后再执行方法,最后在方法完成(无论是正常完成还是非正常完成)时释放管程。在方法执行期间,执行线程持有了管程,其他任何线程都无法再获得同一个管程。如果一个同步方法执行期间抛出了异常,并且在方法内部无法处理此异常,那这个同步方法所持有的管程将在异常抛到同步方法之外时自动释放。
同步一段指令集序列通常是由 Java 语言中的 synchronized 块来表示的,Java 虚拟机的指令集中有 monitorenter 和 monitorexit 两条指令来支持 synchronized 关键字的语义,正确实现 synchronized 关键字需要编译器与 Java 虚拟机两者协作支持。
Java 虚拟机中的同步(Synchronization)基于进入和退出管程(Monitor)对象实现。无论是显式同步(有明确的 monitorenter 和 monitorexit 指令)还是隐式同步(依赖方法调用和返回指令实现的)都是如此。
编译器必须确保无论方法通过何种方式完成,方法中调用过的每条 monitorenter 指令都必须有执行其对应 monitorexit 指令,而无论这个方法是正常结束还是异常结束。为了保证在方法异常完成时 monitorenter 和 monitorexit 指令依然可以正确配对执行,编译器会自动产生一个异常处理器,这个异常处理器声明可处理所有的异常,它的目的就是用来执行 monitorexit 指令。
4.3 Mark Word
当一个线程尝试访问 synchronized 修饰的代码块时,它首先要获得锁,那么这个锁到底存在哪里呢?是存在锁对象的对象头中的。

- 对象头:Hotspot 虚拟机的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)、Array length(数组长度,只有数组类型才有)。
- 实例变量:存放类的属性数据信息,包括父类的属性信息,如果是数组的实例部分还包括数组的长度,这部分内存按 4 字节对齐。其实就是在 Java 代码中能看到的属性和他们的值。
- 填充数据:由于虚拟机要求对象起始地址必须是 8 字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐,这点了解即可。
在 JVM 中,实例对象在内存中的布局分为 3 块区域:对象头、实例变量和填充数据。对象头中的 Mark Word 用于存储对象自身的运行时数据,它是实现轻量级锁和偏向锁的关键。
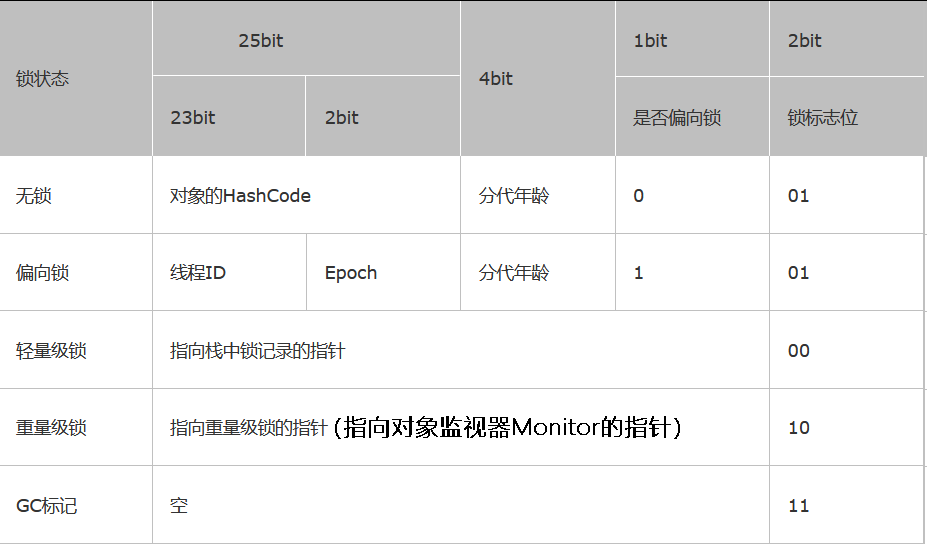
4.4 Monitor
可以看出无论是 synchronized 代码块还是 synchronized 方法,其线程安全的语义实现最终依赖一个叫 monitor 的东西,那么这个神秘的东西是什么呢?
JVM 中的同步是基于进入与退出监视器对象(Monitor,也叫管程对象)来实现的,每个对象实例都会有一个 Monitor 对象,Monitor 对象会和 Java 对象一同创建并销毁。Monitor 对象是由 C++ 来实现的(如下就是通过 openjdk 来分析 C++ 的底层实现的)。
4.4.1 Monitor 监视器锁
在 HotSpot 虚拟机中,monitor 是由 ObjectMonitor 实现的。其源码是用 C++ 来实现的,位于HotSpot 虚拟机源码 ObjectMonitor.hpp 文件中(src/share/vm/runtime/objectMonitor.hpp)。ObjectMonitor 主要数据结构如下:
class ObjectMonitor {
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; // 线程的重入次数
_object = NULL; // 存储该monitor的对象
_owner = NULL; // 标识拥有该monitor的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL;
_succ = NULL;
_cxq = NULL; // 多线程竞争锁时的单向列表
FreeNext = NULL;
_EntryList = NULL; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0;
_SpinClock = 0;
OwnerIsThread = 0;
}
// ...
}
_owner:初始时为 NULL。当有线程占有该 monitor 时,_owner标记为该线程的唯一标识。当线程释放 monitor 时,_owner又恢复为 NULL。_owner是一个临界资源,JVM 是通过 CAS 操作来保证其线程安全的。_cxq:竞争队列,所有请求锁的线程首先会被放在这个队列中(单向链接)。_cxq是一个临界资源,JVM 通过 CAS 原子指令来修改_cxq队列。修改前_cxq的旧值填入了 node 的 next 字段,_cxq指向新值(新线程)。因此,_cxq是一个后进先出的 stack(栈)。_EntryList:_cxq队列中有资格成为候选资源的线程会被移动到该队列中。_WaitSet:因为调用 wait 方法而被阻塞的线程会被放在该队列中。

Monitor 可以类比为一个特殊的房间,这个房间中有一些被保护的数据,Monitor 保证每次只能有一个线程能进入这个房间进行访问被保护的数据,进入房间即为持有 Monitor,退出房间即为释放 Monitor。
当一个线程需要访问受保护的数据(即需要获取对象的 Monitor)时,它会首先在 EntryList 入口队列中排队(这里并不是真正的按照排队顺序),如果没有其他线程正在持有对象的 Monitor,那么它会和 EntryList 队列和 WaitSet 队列中的被唤醒的其他线程进行竞争(即通过 CPU 调度),选出一个线程来获取对象的 Monitor,执行受保护的代码段,执行完毕后释放 Monitor,如果已经有线程持有对象的 Monitor,那么需要等待其释放 Monitor 后再进行竞争。
再说一下 WaitSet 队列。当一个线程拥有 Monitor 后,经过某些条件的判断(比如用户取钱发现账户没钱),这个时候需要调用 Object 的 wait 方法,线程就释放了 Monitor,进入 WaitSet 队列,等待 Object 的 notify 方法(比如用户向账户里面存钱)。当该对象调用了 notify/notifyAll 方法后,WaitSet 中的线程就会被唤醒,然后在 WaitSet 队列中被唤醒的线程和 EntryList 队列中的线程一起通过 CPU 调度来竞争对象的 Monitor,最终只有一个线程能获取对象的 Monitor。
- 当一个线程在 WaitSet 中被唤醒后,并不一定会立刻获取 Monitor,它需要和其他线程去竞争。如果获取到 Monitor,它会先去读取自己保存在 PC 计数器中的地址,从它调用 wait 方法的地方开始继续执行。
- 如果一个 Java 对象被某个线程锁住,则该 Java 对象的 Mark Word 字段中 LockWord 指向 Monitor 的起始地址。
- Monitor 的 Owner 字段会存放拥有相关联对象锁的线程 id。
4.4.2 Monitor 竞争
(1) 执行 monitorenter 时,会调用 InterpreterRuntime.cpp(位于 src/share/vm/interpreter/interpreterRuntime.cpp) 的 InterpreterRuntime::monitorenter 函数。
IRT_ENTRY_NO_ASYNC(void,
InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()), "must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()), "must be NULL or an object");
(2) 对于重量级锁,monitorenter 函数中会调用 ObjectSynchronizer::slow_enter
(3) 最终调用 ObjectMonitor::enter(位于 src/share/vm/runtime/objectMonitor.cpp),源码如下:
void ATTR ObjectMonitor::enter(TRAPS) {
// The following code is ordered to check the most common cases first
// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.
Thread * const Self = THREAD ;
void * cur ;
// 通过 CAS 操作尝试把 monitor 的 _owner 字段设置为当前线程
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
// Either ASSERT _recursions == 0 or explicitly set _recursions = 0.
assert (_recursions == 0, "invariant") ;
assert (_owner == Self , "invariant") ;
// CONSIDER: set or assert OwnerIsThread == 1
return ;
}
// 线程重入,recursions++
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}
// 如果当前线程是第一次进入该 monitor,设置 _recursions 为 1,_owner 为当前线程
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
// Commute owner from a thread-specific on-stack BasicLockObject address to
// a full-fledged "Thread *".
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
// 省略一些代码 ...
for (;;) {
jt->set_suspend_equivalent();
// cleared by handle_special_suspend_equivalent_condition()
// or java_suspend_self()
// 如果获取锁失败,则等待锁的释放;
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
//
// We have acquired the contended monitor, but while we were
// waiting another thread suspended us. We don't want to enter
// the monitor while suspended because that would surprise the
// thread that suspended us.
//
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
}
此处省略锁的自旋优化等操作,统一放在后面 synchronzied 优化中说。以上代码的具体流程概括如下:
- 通过 CAS 尝试把 monitor 的 owner 字段设置为当前线程。
- 如果设置之前的 owner 指向当前线程,说明当前线程再次进入 monitor,即重入锁,执行 recursions ++ ,记录重入的次数。
- 如果当前线程是第一次进入该 monitor,设置 recursions 为 1,_owner 为当前线程,该线程成功获得锁并返回。
- 如果获取锁失败,则等待锁的释放。
4.4.3 Monitor 等待
竞争失败等待调用的是 ObjectMonitor 对象的 EnterI 方法(位于 src/share/vm/runtime/objectMonitor.cpp),源码如下所示:
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
// Try the lock - TATAS
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
if (TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
// 省略部分代码...
// 当前线程被封装成 ObjectWaiter 对象 node,状态设置成 ObjectWaiter::TS_CXQ;
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
// 通过 CAS 把 node 节点 push 到 _cxq (栈)中
ObjectWaiter * nxt ;
for (;;) {
node._next = nxt = _cxq ;
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
}
// 省略部分代码...
for (;;) {
// 线程在被挂起前做一下挣扎,看能不能获取到锁
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
// 通过park将当前线程挂起,等待被唤醒
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
// 省略部分代码...
}
// 省略部分代码...
}
当该线程被唤醒时,会从挂起的点继续执行,通过 ObjectMonitor::TryLock 尝试获取锁,TryLock 方法实现如下:
int ObjectMonitor::TryLock (Thread * Self) {
for (;;) {
void * own = _owner ;
if (own != NULL) return 0 ;
if (Atomic::cmpxchg_ptr (Self , &_owner , NULL) == NULL) {
// Either guarantee _recursions == 0 or set _recursions = 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self , "invariant") ;
// CONSIDER: set or assert that OwnerIsThread == 1
return 1 ;
}
// The lock had been free momentarily, but we lost the race to the lock.
// Interference -- the CAS failed.
// We can either return -1 or retry.
// Retry doesn't make as much sense because the lock was just acquired.
if (true) return -1 ;
}
}
以上代码的具体流程概括如下:
- 当前线程被封装成 ObjectWaiter 对象 node,状态设置成 ObjectWaiter::TS_CXQ。
- 在 for 循环中,通过 CAS 把 node 节点 push 到
_cxq中,同一时刻可能有多个线程把自己的 node 节点 push 到_cxq中。 - node 节点 push 到
_cxq之后,通过自旋尝试获取锁,如果还是没有获取到锁,则通过 park 将当前线程挂起,等待被唤醒。 - 当该线程被唤醒时,会从挂起的点继续执行,通过 ObjectMonitor::TryLock 尝试获取锁。
4.4.4 Monitor 释放
当某个持有锁的线程执行完同步代码块时,会进行锁的释放,给其它线程机会执行同步代码,在 HotSpot 中,通过退出 monitor 的方式实现锁的释放,并通知被阻塞的线程,具体实现位于 ObjectMonitor 的 exit 方法中。(位于 src/share/vm/runtime/objectMonitor.cpp),源码如下所示:
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
Thread * Self = THREAD ;
// 省略部分代码...
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
// 省略部分代码...
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ;
// qmode = 2:直接绕过EntryList队列,从cxq队列中获取线程用于竞争锁
if (QMode == 2 && _cxq != NULL) {
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
ExitEpilog (Self, w) ;
return ;
}
// qmode =3:cxq队列插入EntryList尾部;
if (QMode == 3 && _cxq != NULL) {
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w);
if (u == w) break ;
w = u ;
}
assert (w != NULL, "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
ObjectWaiter * Tail ;
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next);
if (Tail == NULL) {
_EntryList = w ;
} else {
Tail->_next = w ;
w->_prev = Tail ;
}
}
// qmode =4:cxq队列插入到_EntryList头部
if (QMode == 4 && _cxq != NULL) {
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w);
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
}
w = _EntryList ;
if (w != NULL) {
assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
w = _cxq ;
if (w == NULL) continue ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w);
if (u == w) break ;
w = u ;
}
TEVENT (Inflated exit - drain cxq into EntryList) ;
assert ( w != NULL , "invariant") ;
assert (_EntryList == NULL , "invariant") ;
if (QMode == 1) {
// QMode == 1 : drain cxq to EntryList, reversing order
// We also reverse the order of the list.
ObjectWaiter * s = NULL ;
ObjectWaiter * t = w ;
ObjectWaiter * u = NULL ;
while (t != NULL) {
guarantee (t->TState == ObjectWaiter::TS_CXQ, "invariant");
t->TState = ObjectWaiter::TS_ENTER ;
u = t->_next ;
t->_prev = u ;
t->_next = s ;
s = t;
t = u ;
}
_EntryList = s ;
assert (s != NULL, "invariant") ;
} else {
// QMode == 0 or QMode == 2
_EntryList = w ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant");
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
}
if (_succ != NULL) continue;
w = _EntryList ;
if (w != NULL) {
guarantee (w->TState == ObjectWaiter::TS_ENTER, "invariant");
ExitEpilog (Self, w) ;
return ;
}
}
}
- 退出同步代码块时会让
_recursions减 1,当_recursions的值减为 0 时,说明线程释放了锁。 - 根据不同的策略(由 QMode 指定),从
_cxq或_EntryList中获取头节点,通过 ObjectMonitor::ExitEpilog 方法唤醒该节点封装的线程,唤醒操作最终由 unpark 完成,实现如下:
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {
assert (_owner == Self, "invariant") ;
_succ = Knob_SuccEnabled ? Wakee->_thread : NULL ;
ParkEvent * Trigger = Wakee->_event ;
Wakee = NULL ;
// Drop the lock
OrderAccess::release_store_ptr (&_owner, NULL) ;
OrderAccess::fence() ; // ST _owner vs LD in
unpark()
if (SafepointSynchronize::do_call_back()) {
TEVENT (unpark before SAFEPOINT) ;
}
DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self);
Trigger->unpark() ; // 唤醒之前被pack()挂起的线程.
// Maintain stats and report events to JVMTI
if (ObjectMonitor::_sync_Parks != NULL) {
ObjectMonitor::_sync_Parks->inc() ;
}
}
被唤醒的线程,会回到 void ATTR ObjectMonitor::EnterI (TRAPS) 的第 600 行,继续执行 monitor 的竞争。
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
4.5 Monitor 本质
监视器锁(Monitor)本质是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
当多个线程同时访问一段同步代码时,这些线程会被放到一个 _EntrySet 集合中,处于阻塞状态的线程都会被放到该列表当中。接下来,当线程获取到对象的 Monitor 时,Monitor 是依赖于底层操作系统的 Mutex Lock(互斥锁)来实现互斥的,线程获取 mutex 成功,则会持有该 mutex,这时其它线程就无法再获取到该 mutex。
如果线程调用了 wait() 方法,那么该线程就会释放掉所持有的 mutex,并且该线程会进入到 _WaitSet 集合(等待集合)中,等待下一次被其他线程调用 notify/notifyAll 唤醒。如果当前线程顺利执行完毕方法,那么它也会释放掉所持有的 mutex。
互斥锁:用于保护临界区,确保同一时间只有一个线程访问数据。对共享资源的访问,先对互斥量进行加锁,如果互斥量已经上锁,调用线程会阻塞,直到互斥量被解锁。在完成了对共享资源的访问后,要对互斥量进行解锁。
由于 Java 的线程是映射到操作系统的原生线程之上的,如果要阻塞或唤醒一条线程,都需要操作系统来帮忙完成(可以看到 ObjectMonitor 的函数调用中会涉及到 Atomic::cmpxchg_ptr,Atomic::inc_ptr 等内核函数,执行同步代码块,没有竞争到锁的对象会 park() 被挂起,竞争到锁的线程会 unpark() 唤醒),这个时候就会存在操作系统用户态和内核态的转换,这种切换会消耗大量的系统资源及耗费很多的处理器时间。所以 synchronized 是 Java 语言中是一个重量级(HeavyWeight) 的操作。
【小结】同步锁在这种实现方式当中,因为 Monitor 是依赖于底层的操作系统实现,这样就存在用户态和内核态之间的切换,所以会增加性能开销。
用户态和和内核态是什么东西呢?要想了解用户态和内核态还需要先了解一下 Linux 系统的体系架构:

从上图可以看出,Linux 操作系统的体系架构分为:用户空间(应用程序的活动空间)和内核。
- 内核:本质上可以理解为一种软件,控制计算机的硬件资源,并提供上层应用程序运行的环境。
- 用户空间:上层应用程序活动的空间。应用程序的执行必须依托于内核提供的资源,包括 CPU 资源、存储资源、I/O 资源等。
- 系统调用:为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口,即:系统调用。
所有进程初始都运行于用户空间,此时即为用户运行状态(简称:用户态);但是当它调用系统调用执行某些操作时,例如 I/O 调用,此时需要陷入内核中运行,我们就称进程处于内核运行态(简称:内核态)。
「系统调用」的过程可以简单理解为:
- 用户态程序将一些数据值放在寄存器中或者使用参数创建一个堆栈, 以此表明需要操作系统提供的服务。
- 用户态程序执行系统调用。
- CPU 切换到内核态,并跳到位于内存指定位置的指令。
- 系统调用处理器(System Call Handler)会读取程序放入内存的数据参数,并执行程序请求的服务。
- 系统调用完成后,操作系统会重置 CPU 为用户态并返回系统调用的结果。
由此可见用户态切换至内核态需要传递许多变量,同时内核还需要保护好用户态在切换时的一些寄存器值、变量等,以备内核态切换回用户态。这种切换就带来了大量的系统资源消耗,这就是在 synchronized 未优化之前,效率低的原因。在 JDK6 中,虚拟机进行了一些优化,譬如在通知操作系统阻塞线程之前加入一段自旋等待过程,避免频繁地切入到核心态中。
【自旋原理】当发生对 Monitor 的争用时,若 owner 能够在很短的时间内释放掉锁,则那些正在争用的线程就可以稍微等待一下(既所谓的自旋),在 Owner 线程释放锁之后,争用线程可能会立刻获取到锁,从而避免了系统阻塞。不过,当 Owner 运行的时间超过了临界值后,争用线程自旋一段时间后依然无法获取到锁,这时争用线程则会停止自旋而进入到阻塞状态。所以总体的思想是:先自旋,不成功再进行阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码来说有极大的性能提升。显然,自旋在多处理器(多核心)上才有意义 。
5. 先行发生原则
happens-before 是 JSR-133 规范之一,内存屏障是 CPU 指令。可以简单认为前者是最终目的,后者是实现手段。
5.1 概念
JSR-133 使用 happens-before 的概念来指定两个操作之间的偏序关系,比如说 a 操作 happens-before b 操作,其实就是说在发生 b 操作之前,a 操作产生的影响能被 b 操作观察到,“影响”包括修改了内存中共享变量的值、发送了消息、调用了方法等。
由于这两个操作可以在一个线程之内,也可以是在不同线程之间。因此,JMM 可以通过 happens-before 关系向程序员提供跨线程的内存可见性保证(如果 Thread-A 的写操作 a 与 Thread-B 的读操作 b 之间存在 happens-before 关系,尽管 a 操作和 b 操作在不同的线程中执行,但 JMM 向程序员保证 a 操作将对 b 操作可见)。具体的定义为:
- 如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在 happens-before 关系,并不意味着 Java 平台的具体实现必须要按照 happens-before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 happens-before 关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM 允许这种重排序)。
上面的(1)是 JMM 对程序员的承诺。从程序员的角度来说,可以这样理解 happens-before 关系:如果 A happens-before B,那么 Java 内存模型将向程序员保证 —— A 操作的结果将对 B 可见,且 A 的执行顺序排在 B 之前。注意,这只是 Java 内存模型向程序员做出的保证!
上面的(2)是 JMM 对编译器和处理器重排序的约束原则。正如前面所言,JMM 其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。JMM 这么做的原因是:程序员对于这两个操作是否真的被重排序并不关心,程序员关心的是程序执行时的语义不能被改变(即执行结果不能被改变)。因此,happens-before 关系本质上和 as-if-serial 语义是一回事。
下面来比较一下 as-if-serial 和 happens-before:
- as-if-serial 语义保证单线程内程序的执行结果不被改变,happens-before 关系保证正确同步的多线程程序的执行结果不被改变。
- as-if-serial 语义给编写单线程程序的程序员创造了一个幻境:单线程程序是按程序的顺序来执行的;happens-before 关系给编写正确同步的多线程程序的程序员创造了一个幻境:正确同步的多线程程序是按 happens-before 指定的顺序来执行的。
- as-if-serial 语义和 happens-before 这么做的目的,都是为了在不改变程序执行结果的前提下,尽可能地提高程序执行的并行度。
5.2 具体规则
下面是 Java 内存模型下一些“天然的”先行发生关系,这些先行发生关系无须任何同步器协助就已经存在,可以在编码中直接使用。如果两个操作之间的关系不在此列,并且无法从下列规则推导出来,则它们就没有顺序性保障,虚拟机可以对它们随意地进行重排序。
- 程序次序规则(Program Order Rule):在一个线程内,按照控制流顺序,书写在前面的操作 happens-before 书写在后面的操作。
- 管程锁定规则(Monitor Lock Rule):一个 unlock 操作 happens-before 后面(时间上)对同一个锁的 lock 操作。
- volatile 变量规则(Volatile Variable Rule):对一个 volatile 变量的写操作 happens-before 后面(时间上)对这个变量的读操作。
- 传递性(Transitivity):如果 A happens-before B,且 B happens-before C,那么 A happens-before C。
- 线程启动规则(Thread Start Rule):Thread 对象的 start() 方法 happens-before 此线程的每一个动作。
- 线程终止规则(Thread Termination Rule):线程中的所有操作都 happens-before 对此线程的终止检测,我们可以通过 Thread::join() 方法是否结束、Thread::isAlive() 的返回值等手段检测线程是否已经终止执行。
- 线程中断规则(Thread Interruption Rule):对线程 interrupt() 方法的调用 happens-before 被中断线程的代码检测到中断事件的发生,可以通过 Thread::interrupted() 方法检测到是否有中断发生。
- 对象终结规则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束) happens-before 它的 finalize() 方法的开始。
5.3 时间先后/先行发生
下面演示一下如何使用这些规则去判定操作间是否具备顺序性,对于读写共享变量的操作来说,就是线程是否安全。读者还可以从下面这个例子中感受一下“时间上的先后顺序”与“先行发生”之间有什么不同。
private int value = 0;
pubilc void setValue(int value){
this.value = value;
}
public int getValue(){
return value;
}
上述代码中显示的是一组再普通不过的 getter/setter 方法,假设存在 Thread-A 和 Thread-B,Thread-A 先(时间上的先后)调用了 setValue(1),然后 Thread-B 调用了同一个对象的 getValue(),那么 Thread-B 收到的返回值是什么?
我们依次分析一下先行发生原则中的各项规则。
- 由于两个方法分别由 Thread-A 和 Thread-B 调用,不在一个线程中,所以程序次序规则在这里不适用;
- 由于没有同步块,自然就不会发生 lock 和 unlock 操作,所以管程锁定规则不适用;
- 由于 value 变量没有被 volatile 关键字修饰,所以 volatile 变量规则不适用;
- 后面的线程启动、终止、中断规则和对象终结规则也和这里完全没有关系。
- 因为没有一个适用的先行发生规则,所以最后一条传递性也无从谈起。
因此我们可以判定,尽管 Thread-A 在操作时间上先于 Thread-B,但是无法确定 Thread-B 中 getValue() 方法的返回结果,换句话说,这里面的操作不是线程安全的。
那怎么修复这个问题呢?我们至少有两种比较简单的方案可以选择:
- 要么把 getter/setter 方法都定义为 synchronized 方法,这样就可以套用管程锁定规则;
- 要么把 value 定义为 volatile 变量,由于 setter 方法对 value 的修改不依赖 value 的原值,满足 volatile 关键字使用场景,这样就可以套用 volatile 变量规则来实现先行发生关系。
通过上面的例子,我们可以得出结论:一个操作“时间上的先发生”不代表这个操作会是“先行发生”。那如果一个操作“先行发生”,是否就能推导出这个操作必定是“时间上的先发生”呢?很遗憾,这个推论也是不成立的(除了那两个强调“时间”了的规则)。一个典型的例子就是多次提到的“指令重排序”:
// 以下操作在同一个线程中执行
int i = 1;
int j = 2;
如上所示的两条赋值语句在同一个线程之中,根据程序次序规则,“int i=1”的操作先行发生于“int j=2”,但是“int j=2”的代码完全可能先被处理器执行,这并不影响先行发生原则的正确性(回看 5.1 节),因为我们在这条线程之中没有办法感知到这一点。
上面两个例子综合起来证明了一个结论:时间先后顺序与先行发生原则之间基本没有因果关系,所以我们衡量并发安全问题的时候不要受时间顺序的干扰,一切必须以「先行发生原则」为准。