1. json JavaScript对象记法
json模块提供了一个与pickle类似的API,可以行化表示,被称为JavaScript对象记法(JavaScript Object Notation,JSON)。不同于pickle,JSON有一个优点,它有多种语言的实现(特别是JavaScript)。JSON对于RESTAPI中Web服务器和客户之间的通信使用最广泛,不过也可以用于满足其他应用间的通信需求。
1.1 编码和解码简单数据类型
默认的,编码器理解Python的一些内置类型(即str、int、float、list、tuple和dict)。
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) data_string = json.dumps(data) print('JSON:', data_string)
对值编码时,表面上类似于Python的repr()输出。

编码然后再重新解码时,可能不会得到完全相同的对象类型。
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA :', data) data_string = json.dumps(data) print('ENCODED:', data_string) decoded = json.loads(data_string) print('DECODED:', decoded) print('ORIGINAL:', type(data[0]['b'])) print('DECODED :', type(decoded[0]['b']))
具体的,元组会变成列表。

1.2 人类可读和紧凑输出
JSON优于pickle的另一个好处是,JSON会生成人类可读的结果。dumps()函数接受多个参数从而使输出更容易理解。例如,sort_keys标志会告诉编码器按有序顺序而不是随机顺序输出字典的键。
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) unsorted = json.dumps(data) print('JSON:', json.dumps(data)) print('SORT:', json.dumps(data, sort_keys=True)) first = json.dumps(data, sort_keys=True) second = json.dumps(data, sort_keys=True) print('UNSORTED MATCH:', unsorted == first) print('SORTED MATCH :', first == second)
排序后,会让人更容易的查看结果,而且还可以在测试中比较JSON输出。
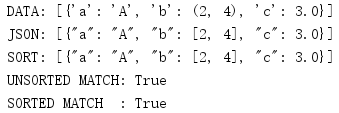
对于高度嵌套的数据结构,还可以指定一个缩进(indent)值来得到格式美观的输出。
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) print('NORMAL:', json.dumps(data, sort_keys=True)) print('INDENT:', json.dumps(data, sort_keys=True, indent=2))
当缩进是一个非负整数时,输出更类似于pprint的输出,数据结构中每一级的前导空格与缩进级别匹配。

这种详细输出会增加传输等量数据所需的字节数,所以生产环境中往往不使用这种输出。实际上,可以调整编码输出中分隔数据的设置,从而使其比默认格式更紧凑。
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) print('repr(data) :', len(repr(data))) plain_dump = json.dumps(data) print('dumps(data) :', len(plain_dump)) small_indent = json.dumps(data, indent=2) print('dumps(data, indent=2) :', len(small_indent)) with_separators = json.dumps(data, separators=(',', ':')) print('dumps(data, separators):', len(with_separators))
dumps()的separators参数应当是一个元组,其中包含用来分隔列表中各项的字符串,以及分隔字典中键和值的字符串。默认为(',',':')。通过去除空白符,可以生成一个更为紧凑的输出。

1.3 编码字典
JSON格式要求字典的键是字符串。如果一个字典以非字符串类型作为键,那么对这个字典编码时,便会生成一个TypeError。要想绕开这个限制,一种办法是使用skipkeys参数告诉编码器跳过非串的键。
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0, ('d',): 'D tuple'}] print('First attempt') try: print(json.dumps(data)) except TypeError as err: print('ERROR:', err) print() print('Second attempt') print(json.dumps(data, skipkeys=True))
这里不会产生一个异常,而是会忽略非串的键。
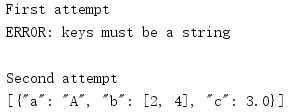
1.4 处理定制类型
目前为止,所有例子都使用Python的内置类型,因为这些类型得到了json的内置支持。通常还需要对定制类编码,有两种办法可以做到。假设以下代码清单中的类需要进行编码。
import json
class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s)
要对MyObj实例编码,一个简单的方法是定义一个函数,将未知类型转换为已知类型。这个函数并不需要具体完成编码,它只是将一个类型的对象转换为另一个类型。
import json class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s) obj = MyObj('instance value goes here') print('First attempt') try: print(json.dumps(obj)) except TypeError as err: print('ERROR:', err) def convert_to_builtin_type(obj): print('default(', repr(obj), ')') # Convert objects to a dictionary of their representation d = { '__class__': obj.__class__.__name__, '__module__': obj.__module__, } d.update(obj.__dict__) return d print() print('With default') print(json.dumps(obj, default=convert_to_builtin_type))
在convert_to_builtin_ type()中,json无法识别的类实例会被转换为字典,其中包含足够多的信息,如果程序能访问这个处理所需的Python模块,就能利用这些信息重新创建对象。

要对结果解码并创建一个MyObj()实例,可以使用loads()的objecthook参数关联解码器,从而可以从模块导入这个类,并将该类用来创建实例。对于从到来数据流解码的各个字典,都会调用object_hook,这就提供了一个机会,可以把字典转换为另外一种类型的对象。hook函数要返回调用应用要接收的对象而不是字典。
import json def dict_to_object(d): if '__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) print('MODULE:', module.__name__) class_ = getattr(module, class_name) print('CLASS:', class_) args = { key: value for key, value in d.items() } print('INSTANCE ARGS:', args) inst = class_(**args) else: inst = d return inst encoded_object = ''' [{"s": "instance value goes here", "__module__": "json_myobj", "__class__": "MyObj"}] ''' myobj_instance = json.loads( encoded_object, object_hook=dict_to_object, ) print(myobj_instance)
由于json将串值转换为Unicode对象,因此,在其被用作类构造函数的关键字参数之前,需要将它们重新编码为ASCII串。

内置类型也有类似的hook,如整数(parse_int)、浮点数(parse_float)和常量(parse_constant)。
1.5 编码器和解码器类
除了之前介绍的便利函数,json模块还提供了一些类来完成编码和解码。直接使用这些类可以访问另外的API来定制其行为。
JSONEncoder使用一个iterable接口生成编码数据“块”,从而更容易将其写至文件或网络套接字,而不必在内存中表示完整的数据结构。
import json encoder = json.JSONEncoder() data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] for part in encoder.iterencode(data): print('PART:', part)
输出按逻辑单元输出,而不是根据某个大小值。

encode()方法基本上等价于''.join(encoder.iterencode()),只不过之前会做一些额外的错误检查。
要对任意的对象编码,需要用一个实现覆盖default()方法,这个实现类似于convert_to _builtin_type()中的实现。
import json class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s) class MyEncoder(json.JSONEncoder): def default(self, obj): print('default(', repr(obj), ')') # Convert objects to a dictionary of their representation d = { '__class__': obj.__class__.__name__, '__module__': obj.__module__, } d.update(obj.__dict__) return d obj = MyObj('internal data') print(obj) print(MyEncoder().encode(obj))
输出与前一个实现的输出相同。
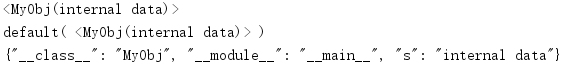
这里要解码文本,然后将字典转换为一个对象,与前面的实现相比,这需要多做一些工作,不过不算太多。
import json class MyDecoder(json.JSONDecoder): def __init__(self): json.JSONDecoder.__init__( self, object_hook=self.dict_to_object, ) def dict_to_object(self, d): if '__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) print('MODULE:', module.__name__) class_ = getattr(module, class_name) print('CLASS:', class_) args = { key: value for key, value in d.items() } print('INSTANCE ARGS:', args) inst = class_(**args) else: inst = d return inst encoded_object = ''' [{"s": "instance value goes here", "__module__": "json_myobj", "__class__": "MyObj"}] ''' myobj_instance = MyDecoder().decode(encoded_object) print(myobj_instance)
输出与前面的例子相同。

1.6 处理流和文件
目前为止,所有例子都假设整个数据结构的编码版本可以一次完全放在内存中。对于很大的数据结构,更合适的做法可能是将编码直接写至一个类似文件的对象。便利函数load()和dump()会接收一个类似文件对象的引用用于读写。
import io import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] f = io.StringIO() json.dump(data, f) print(f.getvalue())
类似于这个例子中使用的StringIO缓冲区,也可以使用套接字或常规的文件句柄。
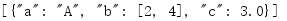
尽管没有优化,即一次只读取数据的一部分,但load()函数还提供了一个好处,它封装了从流输入生成对象的逻辑。
import io import json f = io.StringIO('[{"a": "A", "c": 3.0, "b": [2, 4]}]') print(json.load(f))
类似于dump(),任何类似文件对象都可以被传递到load()。
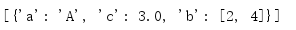
1.7 混合数据流
JS0NDecoder包含一个raw_decode()方法,如果一个数据结构后面跟有更多数据,如带尾部文本的JSON数据,则可以用这个方法完成解码。返回值是对输入数据解码创建的对象,以及该数据的一个索引(指示在哪里结束解码)。
import json decoder = json.JSONDecoder() def get_decoded_and_remainder(input_data): obj, end = decoder.raw_decode(input_data) remaining = input_data[end:] return (obj, end, remaining) encoded_object = '[{"a": "A", "c": 3.0, "b": [2, 4]}]' extra_text = 'This text is not JSON.' print('JSON first:') data = ' '.join([encoded_object, extra_text]) obj, end, remaining = get_decoded_and_remainder(data) print('Object :', obj) print('End of parsed input :', end) print('Remaining text :', repr(remaining)) print() print('JSON embedded:') try: data = ' '.join([extra_text, encoded_object, extra_text]) obj, end, remaining = get_decoded_and_remainder(data) except ValueError as err: print('ERROR:', err)
遗憾的是,这种做法只适用于对象出现在输入起始位置的情况。

1.8 命令行上处理JSON
json.tool模块实现了一个命令行程序来重新格式化JSON数据,使数据更易读。
[{"a": "A", "c": 3.0, "b": [2, 4]}]
输入文件example.json包含一个映射,其中键采用字母表顺序。第一个例子显示了按顺序重新格式化的数据,第二个例子使用了--sort-keys在打印输出之前先对映射键排序。
[ { "a": "A", "c": 3.0, "b": [ 2, 4 ] } ]
[ { "a": "A", "b": [ 2, 4 ], "c": 3.0 } ]