1. collections容器数据类型
collections模块包含除内置类型list、dict和tuple以外的其他容器数据类型。
1.1 ChainMap搜索多个字典
ChainMap类管理一个字典序列,并按其出现的顺序搜索以查找与键关联的值。ChainMap提供了一个很多的“上下文”容器,因为可以把它看作一个栈,栈增长时发生变更,栈收缩时这些变更被丢弃。
1.1.1 访问值
ChainMap支持与常规字典相同的api来访问现有的值。
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Individual Values') print('a = {}'.format(m['a'])) print('b = {}'.format(m['b'])) print('c = {}'.format(m['c'])) print() print('Keys = {}'.format(list(m.keys()))) print('Values = {}'.format(list(m.values()))) print() print('Items:') for k, v in m.items(): print('{} = {}'.format(k, v)) print() print('"d" in m: {}'.format(('d' in m)))
按子映射传递到构造函数的顺序来搜索这些子映射,所以对应键 'c' 报告的值来自a字典。

1.1.2 重排
ChainMap会在它的maps属性中存储要搜索的映射列表。这个列表是可变的,所以可以直接增加新映射,或者改变元素的顺序以控制查找和更新行为。
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print(m.maps) print('c = {} '.format(m['c'])) # reverse the list m.maps = list(reversed(m.maps)) print(m.maps) print('c = {}'.format(m['c']))
要映射列表反转时,与之关联的值将 'c' 更改。
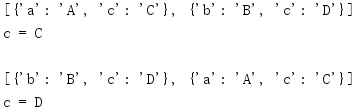
1.1.3 更新值
ChainMap不会缓存子映射中的值。因此,如果它们的内容有修改,则访问ChainMap时会反映到结果中。
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Before: {}'.format(m['c'])) a['c'] = 'E' print('After : {}'.format(m['c']))
改变与现有键关联的值与增加新元素的做法一样。

也可以直接通过ChainMap设置值,不过实际上只有链中的第一个映射会被修改。
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Before:', m) m['c'] = 'E' print('After :', m) print('a:', a)
使用m存储新值时,a映射会更新。

ChainMap提供了一种便利方法,可以用一个额外的映射在maps列表的最前面创建一个新实例,这样就能轻松地避免修改现有的底层数据结构。
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m1 = collections.ChainMap(a, b) m2 = m1.new_child() print('m1 before:', m1) print('m2 before:', m2) m2['c'] = 'E' print('m1 after:', m1) print('m2 after:', m2)
正是基于这种堆栈行为,可以很方便地使用ChainMap实例作为模板或应用上下文。具体地,可以很容易地在一次迭代中增加或更新值,然后再下一次迭代中丢弃这些改变。
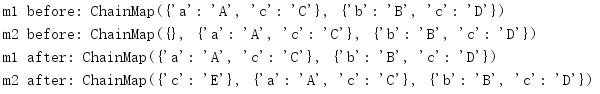
如果新上下文已知或提前构建,还可以向new_child()传递一个映射。
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} c = {'c': 'E'} m1 = collections.ChainMap(a, b) m2 = m1.new_child(c) print('m1["c"] = {}'.format(m1['c'])) print('m2["c"] = {}'.format(m2['c']))
这相当于:
m2 = collections.ChainMap(c, *m1.maps)
并且还会产生:
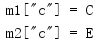
1.2 Counter统计可散列的对象
Counter是一个容器,可以跟踪等效值增加的次数。这个类可以用来实现其他语言中常用包(bag)或多集合(multiset)数据结构实现的算法。
1.2.1 初始化
Counter支持3种形式的初始化。调用Counter的构造函数时可以提供一个元素序列或者一个包含键和计数的字典,还可以使用关键字参数将字符串名映射到计数。
import collections print(collections.Counter(['a', 'b', 'c', 'a', 'b', 'b'])) print(collections.Counter({'a': 2, 'b': 3, 'c': 1})) print(collections.Counter(a=2, b=3, c=1))
这3种形式的初始化结果都是一样的。

如果不提供任何参数,则可以构造一个空Counter,然后通过update()方法填充。
import collections c = collections.Counter() print('Initial :', c) c.update('abcdaab') print('Sequence:', c) c.update({'a': 1, 'd': 5}) print('Dict :', c)
计数值只会根据新数据增加,替换数据并不会改变计数。在下面的例子中,a的计数会从3增加到4。
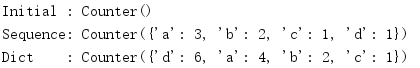
1.2.2 访问计数
一旦填充了Counter,便可以使用字典API获取它的值。
import collections c = collections.Counter('abcdaab') for letter in 'abcde': print('{} : {}'.format(letter, c[letter]))
对于未知的元素,Counter不会产生KeyError。如果在输入中没有找到某个值(此例中的e),则其计数为0.

elements()方法返回一个迭代器,该迭代器将生成Counter知道的所有元素。
import collections c = collections.Counter('extremely') c['z'] = 0 print(c) print(list(c.elements()))
不能保证元素的顺序不变,另外计数小于或等于0的元素不包含在内。
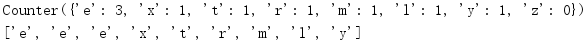
使用most_common()可以生成一个序列,其中包含n个最常遇到的输入值及相应计数。
import collections c = collections.Counter() with open('test.txt', 'rt') as f: for line in f: c.update(line.rstrip().lower()) print('Most common:') for letter, count in c.most_common(3): print('{}: {:>7}'.format(letter, count))
这个例子要统计系统字典内所有单词中出现的字母,以生成一个频度分布,然后打印3个最常见的字母。如果不向most_common()提供参数,则会生成由所有元素构成的一个列表,按频度排序。
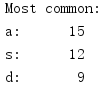
1.2.3 算术操作
Counter实例支持用算术和集合操作来完成结果的聚集。下面这个例子展示了创建新Counter实例的标准操作符,不过也支持+=,-=,&=和|=等原地执行的操作符。
import collections c1 = collections.Counter(['a', 'b', 'c', 'a', 'b', 'b']) c2 = collections.Counter('alphabet') print('C1:', c1) print('C2:', c2) print(' Combined counts:') print(c1 + c2) print(' Subtraction:') print(c1 - c2) print(' Intersection (taking positive minimums):') print(c1 & c2) print(' Union (taking maximums):') print(c1 | c2)
每次通过一个操作生成一个新的Counter时,计数为0或负数的元素都会被删除。在c1和c2中a的计数相同,所以减法操作后它的计数为0。

1.3 defaultdict缺少的键返回一个默认值
标准字典包括一个setdefault()方法,该方法被用来获取一个值,如果这个值不存在则建立一个默认值。与之相反,初始化容器时defaultdict会让调用者提前指定默认值。
import collections def default_factory(): return 'default value' d = collections.defaultdict(default_factory, foo='bar') print('d:', d) print('foo =>', d['foo']) print('bar =>', d['bar'])
只要所有键都有相同的默认值,那么这个方法就可以被很好的使用。如果默认值是一种用于聚集或累加值的类型,如list、set或者int,那么这个方法尤其有用。标准库文档提供了很多以这种方式使用defaultdict的例子。

1.4 deque双端队列
双端队列或deque支持从任意一端增加和删除元素。更为常用的两种结构(即栈和队列)就是双端队列的退化形式,它们的输入和输出被限制在某一端。
import collections d = collections.deque('abcdefg') print('Deque:', d) print('Length:', len(d)) print('Left end:', d[0]) print('Right end:', d[-1]) d.remove('c') print('remove(c):', d)
由于deque是一种序列容器,因此同样支持list的一些操作,如用__getitem__()检查内容,确定长度,以及通过匹配标识从队列中间删除元素。
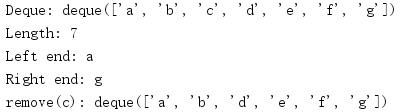
1.4.1 填充
可以从任意一端填充deque,其在Python实现中被称为"左端"和"右端" 。
import collections # Add to the right d1 = collections.deque() d1.extend('abcdefg') print('extend :', d1) d1.append('h') print('append :', d1) # Add to the left d2 = collections.deque() d2.extendleft(range(6)) print('extendleft:', d2) d2.appendleft(6) print('appendleft:', d2)
extendleft()函数迭代处理其输入,对各个元素完成与appendleft()同样的处理。最终结果是deque将包含逆序的输入序列。
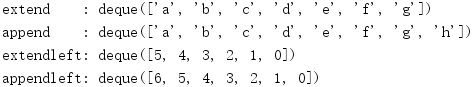
1.4.2 消除
类似地,可以从两端或任意一端消除deque的元素,这取决于所应用的算法。
import collections print('From the right:') d = collections.deque('abcdefg') while True: try: print(d.pop(), end='') except IndexError: break print() print(' From the left:') d = collections.deque(range(6)) while True: try: print(d.popleft(), end='') except IndexError: break print()
使用pop()可以从deque的右端删除一个元素,使用popleft()可以从左端取一个元素。

由于双端队列是线程安全的,所以甚至可以在不同线程中同时从两端消除队列的内容。
import collections import threading import time candle = collections.deque(range(5)) def burn(direction, nextSource): while True: try: next = nextSource() except IndexError: break else: print('{:>8}: {}'.format(direction, next)) time.sleep(0.1) print('{:>8} done'.format(direction)) return left = threading.Thread(target=burn, args=('Left', candle.popleft)) right = threading.Thread(target=burn, args=('Right', candle.pop)) left.start() right.start() left.join() right.join()
这个例子中的线程交替处理两端,删除元素,直至这个deque为空。

1.4.3 旋转
deque的另一个很有用的方面是可以按任意一个方向旋转,从而跳过一些元素。
import collections d = collections.deque(range(10)) print('Normal :', d) d = collections.deque(range(10)) d.rotate(2) print('Right rotation:', d) d = collections.deque(range(10)) d.rotate(-2) print('Left rotation :', d)
将deque向右旋转(使用一个正旋转值)会从右端取元素,并且把它们移到左端。向左旋转(使用一个负值)则从左端将元素移至右端。可以形象地把deque中的元素看作是刻在拨号盘上,这对于理解双端队列很有帮助。

1.4.4 限制队列大小
配置deque实例时可以指定一个最大长度,使它不会超过这个大小。队列达到指定长度时,随着新元素的增加会删除现有的元素。如果要查找一个长度不确定的流中的最后n个元素,那么这种行为会很有用。
import collections import random # Set the random seed so we see the same output each time # the script is run. random.seed(1) d1 = collections.deque(maxlen=3) d2 = collections.deque(maxlen=3) for i in range(5): n = random.randint(0, 100) print('n =', n) d1.append(n) d2.appendleft(n) print('D1:', d1) print('D2:', d2)
不论元素增加到哪一端,队列长度都保持不变。

1.5 namedtuple带命名字段的元组子类
标准tuple使用数值索引来访问其成员。
bob = ('Bob', 30, 'male') print('Representation:', bob) jane = ('Jane', 29, 'female') print(' Field by index:', jane[0]) print(' Fields by index:') for p in [bob, jane]: print('{} is a {} year old {}'.format(*p))
对于简单的用途,tuple是很方便的容器。

另一方面,使用tuple时需要记住对应各个值要使用哪个索引,这可能会导致错误,特别是当tuple有大量字段,而且构造元和使用元组的位置相距很远时。namedtuple除了为各个成员指定数值索引外,还为其指定名字。
1.5.1 定义
与常规的元组一样,namedtuple实例在内存使用方面同样很高效,因为它们没有每一个实例的字典。
各种namedtuple都由自己的类表示,这个类使用namedtuple()工厂数来创建。参数就是新类名和一个包含元素名的字符串。
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print(' Representation:', bob) jane = Person(name='Jane', age=29) print(' Field by name:', jane.name) print(' Fields by index:') for p in [bob, jane]: print('{} is {} years old'.format(*p))
如这个例子所示,除了使用标准元组的位置索引外,还可以使用点记发(obj.attr)按名字访问namedtuple的字段。

与常规tuple类似,namedtuple也是不可修改的。这个限制允许tuple实例具有一致的散列值,这使得可以把它们用作字典中的键并包含在集合中。
import collections Person = collections.namedtuple('Person', 'name age') pat = Person(name='Pat', age=12) print(' Representation:', pat) pat.age = 21
如果试图通过命名属性改变一个值,那么这会导致一个AttributeError。

1.5.2 非法字段名
如果字段名重复或者与Python关键字冲突,那么其就是非法字段名。
import collections try: collections.namedtuple('Person', 'name class age') except ValueError as err: print(err) try: collections.namedtuple('Person', 'name age age') except ValueError as err: print(err)
解析字段名时,非法值会导致ValueError异常。

如果要基于程序控制之外的值创建一个namedtuple(如表示一个数据库查询返回的记录行,而事先并不知道数据库模式),那么这种情况下应把rename选项设置为True,以对非法字段重命名。
import collections with_class = collections.namedtuple( 'Person', 'name class age', rename=True) print(with_class._fields) two_ages = collections.namedtuple( 'Person', 'name age age', rename=True) print(two_ages._fields)
重命名字段的新名字取决于它在元组中的索引,所以名为class的字段会变成_1,重复的age字段则变成_2。
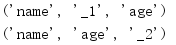
1.5.3 指定属性
namedtuple提供了很多有用的属性和方法来处理子类和实例。所有这些内置属性名都有一个下划线(_)前缀,按惯例在大多数Python程序中,这都会指示一个私有属性。不过,对于namedtuple,这个前缀是为了防止这个名字与用户提供的属性名冲突。
传入namedtuple来定义新类的字段名会保存在_fields属性中。
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('Representation:', bob) print('Fields:', bob._fields)
尽管参数是一个用空格分隔的字符串,但储存的值却是由各个名字组成的一个序列。
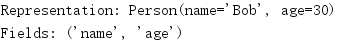
可以使用_asdict()将namedtuple实例转换为OrderedDict实例。
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('Representation:', bob) print('As Dictionary:', bob._asdict())
OrderedDict的键与相应namedtuple的字段顺序相同。
_replace()方法构建一个新实例,在这个过程中会替换一些字段的值。
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print(' Before:', bob) bob2 = bob._replace(name='Robert') print('After:', bob2) print('Same?:', bob is bob2)
尽管从名字上看似乎会修改现有的对象,但由于namedtuple实例是不可变的,所以实际上这个方法会返回一个新对象。

1.6 OrderedDict记住向字典中添加键的顺序
OrderedDict是一个字典子类,可以记住其内容增加的顺序。
import collections print('Regular dictionary:') d = {} d['a'] = 'A' d['b'] = 'B' d['c'] = 'C' for k, v in d.items(): print(k, v) print(' OrderedDict:') d = collections.OrderedDict() d['a'] = 'A' d['b'] = 'B' d['c'] = 'C' for k, v in d.items(): print(k, v)
常规dict并不跟踪插入顺序,迭代处理时会根据散列表中如何存储键来按顺序生成值,而散列表中键的存储会受一个随机值的影响,以减少冲突。OrderedDict中则相反,它会记住元素插入的顺序,并在创建迭代器时使用这个顺序。

1.6.1 相等性
常规的dict在检查相等性时会查看其内容。OrderedDict还会考虑元素增加的顺序。
import collections print('dict :', end=' ') d1 = {} d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d2 = {} d2['c'] = 'C' d2['b'] = 'B' d2['a'] = 'A' print(d1 == d2) print('OrderedDict:', end=' ') d1 = collections.OrderedDict() d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d2 = collections.OrderedDict() d2['c'] = 'C' d2['b'] = 'B' d2['a'] = 'A' print(d1 == d2)
在这个例子中,由于两个有序字典由不同顺序的值创建,所以认为这两个有序字典是不同的。

1.6.2 重排
在OrderedDict中可以使用move_to_end()将键移至序列的起始或末尾位置来改变键的顺序。
import collections d = collections.OrderedDict( [('a', 'A'), ('b', 'B'), ('c', 'C')] ) print('Before:') for k, v in d.items(): print(k, v) d.move_to_end('b') print(' move_to_end():') for k, v in d.items(): print(k, v) d.move_to_end('b', last=False) print(' move_to_end(last=False):') for k, v in d.items(): print(k, v)
last参数会告诉move_to_end()要把元素移动为键序列的最后一个元素(参数值为True)或者第一个元素(参数值为Flase)。

1.7 collections.abc容器的抽象基类
collections.abc模块包含一些抽象基类,其为Python内置容器数据结构以及collections模块定义的容器数据结构定义了API。
| 类 | 基类 | API 用途 |
|---|---|---|
| Container | 基本容器特性,如in操作符 | |
| Hashable | 增加了散列支持,可以为容器实例提供散列值 | |
| Iterable | 可以在容器内容上创建一个迭代器 | |
| Iterator | Iterable | 这是容器内容上的一个迭代器 |
| Generator | Iterator | 为迭代器扩展了生成器协议 |
| Sized | 为知道自己大小的容器增加方法 | |
| Callable | 可以作为函数来调用的容器 | |
| Sequence | Sized, Iterable, Container | 支持获取单个元素以及迭代和改变元素顺序 |
| MutableSequence | Sequence | 支持创建一个实例之后增加和删除元素 |
| ByteString | Sequence | 合并bytes和bytearray的API |
| Set | Sized, Iterable, Container | 支持集合操作,如交集和并集 |
| MutableSet | Set | 增加了创建集合后管理集合内容的方法 |
| Mapping | Sized, Iterable, Container | 定义dict使用的只读API |
| MutableMapping | Mapping | 定义创建映射后管理映射内容的方法 |
| MappingView | Sized | 定义从迭代器访问映射内容的方法 |
| ItemsView | MappingView, Set | 视图API的一部分 |
| KeysView | MappingView, Set | 视图API的一部分 |
| ValuesView | MappingView | 视图API的一部分 |
| Awaitable | await表达式中可用的对象的API,如协程 | |
| Coroutine | Awaitable | 实现协程协议的类的API |
| AsyncIterable | 与async for兼容的iterable的API | |
| AsyncIterator | AsyncIterable | 异步迭代器的API |
除了明确的定义不同的容器的API,这些抽象基类还可以在调用对象前用isinstance()测试一个对象是否支持一个API。有些类还提供了方法实现,它们可以作为“混入类”(min-in)构造定制容器类型,而不必从头实现每一个方法。