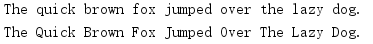1. string:通用字符串操作
string模块在很早的Python版本中就有了。以前这个模块中提供的很多函数已经移植为str对象的方法,不过这个模块仍保留了很多有用的常量和类来处理str对象。
1.1 常量
string.ascii_letters
下文所述ascii_lowercase和ascii_uppercase常量的拼接。该值不依赖于语言区域。
string.ascii_lowercase
小写字母‘abcdefghijklmnopqrstuvwxyz’。此值不依赖于语言环境,并且不会更改。
string.ascii_uppercase
大写字母‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’。此值不依赖于语言环境,并且不会更改。
string.digits
字符串‘0123456789’。
string.hexdigits
字符串‘0123456789abcdefABCDEF’。
string.octdigits
字符串‘01234567’
string.punctuation
ASCII字符的字符串,在C区域设置中被视为标点符号。
string.printable
视为可打印的ASCII字符字符串。这是一个组合digits,ascii_letters,punctuation和whitespace。
string.whitespace
一个字符串,其中包含所有被视为空格的ASCII字符。这包括字符空格,制表符,换行符,返回符,换页符和垂直制表符。
打印出string模块中的常量:
import inspect import string def is_str(value): return isinstance(value, str) for name, value in inspect.getmembers(string, is_str): if name.startswith('_'): continue print('%s=%r ' % (name, value))
结果:

这些常量在处理ASCII数据时很有用,但是由于以某种形式的Unicode遇到非ASCII文本越来越普遍,因此它们的应用受到限制。
1.2 自定义字符串格式化
Formatter类实现了与str的format()方法同样的布局规范语言。它的功能包括类型强制,对齐,属性和域引用、命名和位置模板参数以及特定于类型的格式设置选项。在大多数情况下,该format()方法都能更便利地访问这些特功能,不过也可以利用Formatter构建子类,以备需要改动的情况。
class string.Formatter
Formatter类包含下列公有方法:
- format(format_string, /, *args, **kwargs)
- 首要的 API 方法。 它接受一个格式字符串和任意一组位置和关键字参数。 它只是一个调用vformat()的包装器。
- 在 3.7 版更改: 格式字符串参数现在是仅限位置参数。
- vformat(format_string, args, kwargs)
- 此函数执行实际的格式化操作。 它被公开为一个单独的函数,用于需要传入一个预定义字母作为参数,而不是使用
*args和**kwargs语法将字典解包为多个单独参数并重打包的情况。vformat()完成将格式字符串分解为字符数据和替换字段的工作。 它会调用下文所述的几种不同方法。
此外,Formatter还定义了一些旨在被子类替换的方法:
- parse(format_string)
- 循环遍历format_string并返回一个由可迭代对象组成的元组(literal_text, field_name, format_spec, conversion)。它会被vformat()用来将字符串分解为文本字面值或替换字段。
- 元组中的值在概念上表示一段字面文本加上一个替换字段。如果没有字面文本(如果连续出现两个替换字段就会发生这种情况),则literal_text将是一个长度为零的字符串。如果没有替换字段,则field_name,format_spec和conversion的值将为None。
- get_field(field_name, args, kwargs)
- 给定 field_name 作为parse()的返回值,将其转换为要格式化的对象。 返回一个元组 (obj, used_key)。 默认版本接受在 PEP 3101 所定义形式的字符串,例如 "0[name]" 或 "label.title"。args 和 kwargs 与传给vformat()的一样。返回值used_key与get_value()的 key 形参具有相同的含义。
- get_value(key, args, kwargs)
- 提取给定的字段值。 key 参数将为整数或字符串。 如果是整数,它表示 args 中位置参数的索引;如果是字符串,它表示kwargs中的关键字参数名。
- args 形参会被设为vformat()的位置参数列表,而kwargs形参会被设为由关键字参数组成的字典。
- 对于复合字段名称,仅会为字段名称的第一个组件调用这些函数;后续组件会通过普通属性和索引操作来进行处理。
- 因此举例来说,字段表达式 '0.name' 将导致调用get_value()时附带key参数值0。在get_value()通过调用内置的getattr()函数返回后将会查找name属性。
- 如果索引或关键字引用了一个不存在的项,则将引发
IndexError或KeyError。
- check_unused_args(used_args, args, kwargs)
- 在必要时实现对未使用参数进行检测。 此函数的参数是是格式字符串中实际引用的所有参数键的集合(整数表示位置参数,字符串表示名称参数),以及被传给vformat的args和kwargs的引用。未使用参数的集合可以根据这些形参计算出来。如果检测失败则check_unused_args()应会引发一个异常。
- format_field(value, format_spec)
-
format_field()会简单地调用内置全局函数format()。提供该方法是为了让子类能够重载它。
- convert_field(value, conversion)
- 使用给定的转换类型(来自parse()方法所返回的元组)来转换(由get_field()所返回的)值。默认版本支持's'(str),'r'(repr)和'a'(ascii)等转换类型。
1.3 模板字符串
字符串模板是作为内置拼接语法的替代做法。使用string.Template拼接时,要在名字前加前缀$来标识变量(例如,${var}) 。
模板字符串支持基于$的替换,使用以下规则:
$$为转义符号;它会被替换为单个的$。
$identifier为替换占位符,它会匹配一个名为"identifier"的映射键。在默认情况下,"identifier"限制为任意 ASCII 字母数字(包括下划线)组成的字符串,不区分大小写,以下划线或ASCII字母开头。在$字符之后的第一个非标识符字符将表明占位符的终结。
${identifier}等价于$identifier。当占位符之后紧跟着有效的但又不是占位符一部分的标识符字符时需要使用,例如"${noun}ification"。
在字符串的其他位置出现$将导致引发ValueError。
class string.Template(template)
该构造器接受一个参数作为模板字符串。
- substitute(mapping={}, /, **kwds)
- 执行模板替换,返回一个新字符串。mapping为任意字典类对象,其中的键将匹配模板中的占位符。 或者你也可以提供一组关键字参数,其中的关键字即对应占位符。当同时给出mapping和kwds并且存在重复时,则以kwds中的占位符为优先。
- safe_substitute(mapping={}, /, **kwds)
- 类似于safe_substitute(),不同之处是如果有占位符未在mapping和kwds中找到,不是引发
KeyError异常,而是将原始占位符不加修改地显示在结果字符串中。另一个与substitute()的差异是任何在其他情况下出现的$将简单地返回$而不是引发ValueError。 - 此方法被认为“安全”,因为虽然仍有可能发生其他异常,但它总是尝试返回可用的字符串而不是引发一个异常。从另一方面来说,safe_substitute()也可能根本算不上安全,因为它将静默地忽略错误格式的模板,例如包含多余的分隔符、不成对的花括号或不是合法Python标识符的占位符等等。
下面例子使用%操作符将简单模板与相似的字符串插值进行比较,并使用来比较新格式的字符串语法str.format()。
import string values = {'var': 'foo'} t = string.Template(""" Variable : $var Escape : $$ Variable in text: ${var}iable """) print('TEMPLATE:', t.substitute(values)) s = """ Variable : %(var)s Escape : %% Variable in text: %(var)siable """ print('INTERPOLATION:', s % values) s = """ Variable : {var} Escape : {{}} Variable in text: {var}iable """ print('FORMAT:', s.format(**values))
在前两种情况下,触发字符($或%)通过重复两次来进行转义。在格式化语法中,需要重复{和}来转义。
结果:

模板与字符串拼接或格式化的一个关键区别是,它不考虑参数的类型。值会转换为字符串,而将字符串插入结果中。这里没有提供格式化选项。例如,无法控制使用几位有效数字来表示一个浮点值。
但是,这样做的好处是,通过使用safe_substitute()方法,可以避免未能向模板提供所需的所有参数值时可能产生的异常。
import string values = {'var': 'foo'} t = string.Template("$var is here but $missing is not provided") try: print('substitute() :', t.substitute(values)) except KeyError as err: print('ERROR:', str(err)) print('safe_substitute():', t.safe_substitute(values))
由于value字典中没有missing的值,所以substitute()会产生一个KeyError。safe_substitute()则不同,它不会抛出这个错误,而是会捕捉这个错误并保留文本中的变量表达式。
结果:

进阶用法:你可以派生Template的子类来自定义占位符语法、分隔符,或用于解析模板字符串的整个正则表达式。 为此目的,你可以重载这些类属性:
delimiter -- 这是用来表示占位符的起始的分隔符的字符串字面值。 默认值为 $。 请注意此参数 不能 为正则表达式,因为其实现将在必要时对此字符串调用 re.escape()。 还要注意你不能在创建类之后改变此分隔符(例如在子类的类命名空间中必须设置不同的分隔符)。
idpattern -- 这是用来描述不带花括号的占位符的模式的正则表达式。 默认值为正则表达式 (?a:[_a-z][_a-z0-9]*)。 如果给出了此属性并且 braceidpattern 为 None 则此模式也将作用于带花括号的占位符。
注解:由于默认的 flags 为 re.IGNORECASE,模式 [a-z] 可以匹配某些非 ASCII 字符。 因此我们在这里使用了局部旗标 a。
在 3.7 版更改: braceidpattern 可被用来定义对花括号内部和外部进行区分的模式。
braceidpattern -- 此属性类似于 idpattern 但是用来描述带花括号的占位符的模式。 默认值 None 意味着回退到 idpattern (即在花括号内部和外部使用相同的模式)。 如果给出此属性,这将允许你为带花括号和不带花括号的占位符定义不同的模式。
3.7 新版功能.
flags -- 将在编译用于识别替换内容的正则表达式被应用的正则表达式旗标。 默认值为 re.IGNORECASE。 请注意 re.VERBOSE 总是会被加为旗标,因此自定义的 idpattern 必须遵循详细正则表达式的约定。
3.2 新版功能.
作为另一种选项,你可以通过重载类属性 pattern 来提供整个正则表达式模式。 如果你这样做,该值必须为一个具有四个命名捕获组的正则表达式对象。 这些捕获组对应于上面已经给出的规则,以及无效占位符的规则:
escaped -- 这个组匹配转义序列,在默认模式中即
$$。named -- 这个组匹配不带花括号的占位符名称;它不应当包含捕获组中的分隔符。
braced -- 这个组匹配带有花括号的占位符名称;它不应当包含捕获组中的分隔符或者花括号。
invalid -- 这个组匹配任何其他分隔符模式(通常为单个分隔符),并且它应当出现在正则表达式的末尾。
string.Template可以通过调整用于在模板主体中查找变量名称的正则表达式模式来更改其默认语法。一种简单的方法是更改delimiter和idpattern类属性。
import string class MyTemplate(string.Template): delimiter = '%' idpattern = '[a-z]+_[a-z]+' template_text = ''' Delimiter : %% Replaced : %with_underscore Ignored : %notunderscored ''' d = { 'with_underscore': 'replaced', 'notunderscored': 'not replaced', } t = MyTemplate(template_text) print('Modified ID pattern:') print(t.safe_substitute(d))
在这个例子中,替换规则已经改变,定界符是%而不是$,而且变量名中间的某个位置必须包含一个下划线。模式%notunderscored不会被替换为任何字符串,因此它不包含下划线字符。
结果:

要完成更复杂的修改,可以覆盖pattern属性并定义一个全新的正则表达式。所提供的模式必须包含4个命名组,分别捕获转义定界符、命名变量、加括号的变量名和不合法的定界符模式。
import string t = string.Template('$var') print(t.pattern.pattern)
t.pattern的值是一个已编译正则表达式,不过可以通过它的pattern属性得到原来的字符串。
结果:

下面这个例子定义了一个新模式以创建一个新的模板类型,这个使用{{var}}作为变量语法。
import re import string class MyTemplate(string.Template): delimiter = '{{' pattern = r''' {{(?: (?P<escaped>{{)| (?P<named>[_a-z][_a-z0-9]*)}}| (?P<braced>[_a-z][_a-z0-9]*)}}| (?P<invalid>) ) ''' t = MyTemplate(''' {{{{ {{var}} ''') print('MATCHES:', t.pattern.findall(t.template)) print('SUBSTITUTED:', t.safe_substitute(var='replacement'))
必须分别提供named和braced模式,尽管它们实际上是一样的。
结果:

1.4 辅助函数
string.capwords(s,sep=None)
使用str.split()将参数拆分为单词,使用str.capitalize()将单词转为大写形式,使用str.join()将大写的单词进行拼接。 如果可选的第二个参数 sep 被省略或为None,则连续的空白字符会被替换为单个空格符并且开头和末尾的空白字符会被移除,否则 sep 会被用来拆分和拼接单词。
import string s = 'The quick brown fox jumped over the lazy dog.' print(s) print(string.capwords(s))
结果: