1. 代理IP
代理IP这个功能呢,在urllib和requests中都存在,但是这个在大的爬虫项目中是非常重要的,所以我拿出来单独讲解。
对于某些网站,如果同一个 IP 短时间内发送大量请求,则可能会将该 IP 判定为爬虫,进而对该 IP 进行封禁
所以我们有必要使用随机的 IP 地址来绕开这一层检查。我们可以去找那些提供免费IP地址的网站,但是这些网站的免费代理IP基本上是不稳定的,随时可能会更新,如果是自己小规模的爬取,可以使用免费代理IP。如果是那种大型的,就需要付费代理IP了。
1.1 urllib使用IP代理
import urllib.request import random ip_list = [ {'http':'61.135.217.7:80'}, {'http':'182.88.161.204:8123'} ] proxy_handler = urllib.request.ProxyHandler(random.choice(ip_list)) opener = urllib.request.build_opener(proxy_handler) response = opener.open('https://www.httpbin.org/ip') print(response.read().decode('utf-8'))
结果:

1.2 requests使用IP代理
使用requests添加代理也非常简单,只要在请求的方法中(比如get或者post)传递proxies参数就可以了。
import requests url = 'https://httpbin.org/get' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } proxy = { 'http':'222.217.124.162:8118' } resp = requests.get(url,headers=headers,proxies=proxy) with open('ip.html','w',encoding='utf-8') as fp: fp.write(resp.text)
结果:
ip.html:
{ "args": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" }, "origin": "183.14.76.230, 183.14.76.230", "url": "https://httpbin.org/get" }
2. cookie
我以前学java的时候学过cookie了,一直以为自己博客中也写了,这里就来补充一下cookie基础知识了。
2.1 什么是cookie
在网站中,http请求是无状态的,也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能做到当前请求的是哪个用户。cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(cookie)给浏览器,然后浏览器保存在本地,当该用户发送第二层请求的时候,就会自动的把上一次请求存储的cookie数据自动的携带给服务器,服务器通过浏览器携带的数据就能判断当前用户是谁了。cookie存储的数据量邮箱,不同的浏览器有不同的存储大小,但一般不超过4KB,因此使用cookie只能存储少量的数据。
cookie的格式:
Set-Cookie: NAME=VALUE; Expires/Max-age=DATE; Path=PATH; Domain=DOMAIN_NAME; SECURE
参数意义:
NAME:cookie的名字。
VALUE:cookie的值。
Expires:cookie的过期时间。
Path:cookie作用的路径。
Domain:cookie作用的域名。
SECURE:是否只在https协议下起作用。
2.2 urllib操作cookie
一些需要登录的网站,实际上就是因为没有cookie信息。我们想要用代码的形式访问这种网站,就必须要有正确的cookie信息才能访问。
最简单的方法就是先使用浏览器,然后用抓包软件将数据包中的cookie信息复制下来,放到headers中。
from urllib import request targetUrl = 'http://www.baidu.com/' headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36", "Cookie": "BAIDUID=734868BB44ACDCE4FB2C49DB3AA14669:FG=1 for .baidu.com,BIDUPSID=734868BB44ACDCE4FC561F4D84999535 for .baidu.com,H_PS_PSSID=1429_21101_30211 for .baidu.com,PSTM=1576550373 for .baidu.com,delPer=0 for .baidu.com,BDSVRTM=0 for www.baidu.com,BD_HOME=0 for www.baidu.com" } reqObj = request.Request(url=targetUrl, headers=headers) resp = request.urlopen(reqObj) print(resp.read().decode('utf-8'))
http.cookiejar模块主要的类有 CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。这四个类的作用分别如下:
CookieJar
管理HTTPcookie的值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
FileCookieJar (filename, delayload=None, policy=None)
从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问文件,即只有在需要时才读取文件或在文件中存储数据。
MozillaCookieJar (filename, delayload=None, policy=None)
从FileCookieJar派生而来,创建与Mozilla浏览器cookies.txt兼容的FileCookieJar实例。
LWPCookieJar (filename, delayload=None, policy=None)
从FileCookieJar派生而来,创建与libwww-per标准的Set-Cookie3文件格式兼容的FileCookieJar实例。
利用http.cookiejar和request.HTTPCookieProcessor获取Cookie:
import urllib.request
import http.cookiejar
cookie = http.cookiejar.CookieJar()
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(cookie_handler)
response = opener.open('http://www.baidu.com/')
for item in cookie:
print(item.name + '=' + item.value)
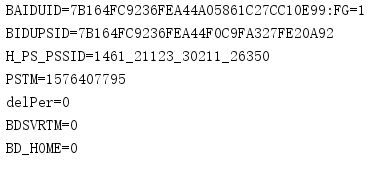
保存Cookie到本地文件,并调用本地文件来进行请求:
import urllib.request
import http.cookiejar
# 将 Cookie 保存到文件
cookie = http.cookiejar.MozillaCookieJar('cookie.txt')
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(cookie_handler)
response = opener.open('http://www.baidu.com/')
cookie.save(ignore_discard=True,ignore_expires=True)
# 从文件读取 Cookie 并添加到请求中
cookie2 = http.cookiejar.MozillaCookieJar()
cookie2 = cookie2.load('cookie.txt',ignore_discard=True,ignore_expires=True)
cookie_handler = urllib.request.HTTPCookieProcessor(cookie2)
opener = urllib.request.build_opener(cookie_handler)
response = opener.open('http://www.baidu.com/')
# 此时已经得到带有 Cookie 请求返回的响应

2.3 requests操作cookie
和代理IP一样,如果响应中包含了cookie,那么可以利用cookies属性拿到这个返回的cookie值。
import requests url = 'http://www.httpbin.org/cookies' cookies = { 'name1':'value1', 'name2':'value2' } response = requests.get(url=url,cookies=cookies) print(response.text)

session:
urllib库,是可以使用opener发送多个请求,多个请求之间是可以共享cookie的。那么如果使用requests,也要达到共享cookie的目的,那么可以使用requests库给我们提供的session对象。注意,这里的session不是Web开发中的那个session,这个地方只是一个会话的对象而已。import requests url = 'http://www.httpbin.org/cookies' cookies = { 'name1':'value1', 'name2':'value2' } session = requests.session() response = session.get(url=url,cookies=cookies) print(response.text)
