1. 爬虫简介
1.1 爬虫是什么?
什么是爬虫,以下是百度百科上的解析:

很多人都将互联网比喻成一张非常大的网,将世界连接起来。如果说互联网是一张网,那么爬虫就像在网上爬的小虫子,通过网页的链接地址来寻找网页,通过特定的搜索算法来确定路线,通常从网站的某一个页面开始,读取该网页的内容,找到该网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,就这样一直循环下去,直到将该网站的所有网页全部抓取为止。
1.2 爬虫原理
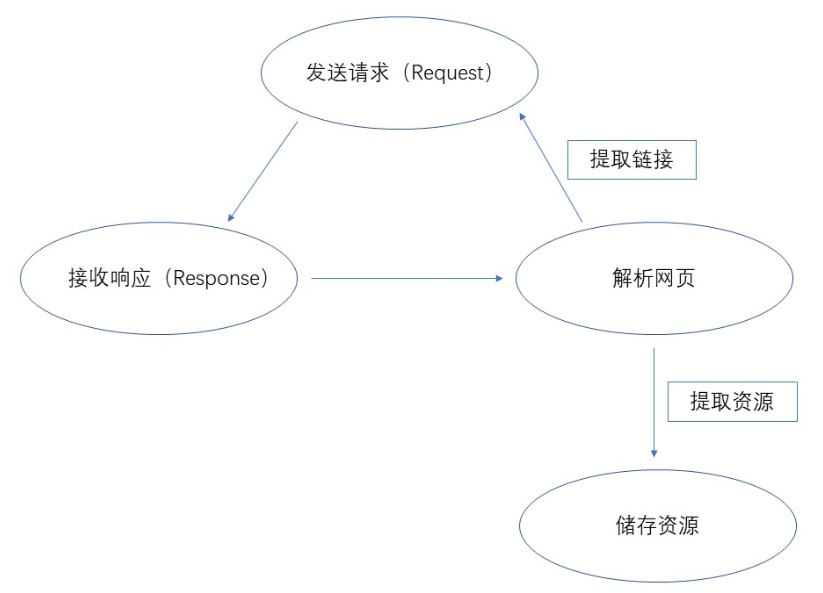
发起请求:
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
接收响应:
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
解析网页:
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
存储资源:
数据库
1.3 发送请求
爬虫的第一个步骤就是对起始 URL 发送请求,以获取其返回的响应
值得注意的是,发送请求实质上是指发送请求报文的过程
请求报文包括以下四个方面:请求行、请求头、空行和请求体。

(1)请求行
请求行由请求方法、请求 URL 和 HTTP 协议版本 3 个字段组成,字段间使用空格分隔
请求方法:请求方法是指对目标资源的操作方式,常见的有 GET 方法和 POST 方法
GET:从指定的资源请求数据,查询字符串包含在 URL 中发送
POST:向指定的资源提交要被处理的数据,查询字符串包含在请求体中发送
请求 URL:请求 URL 是指目标网站的统一资源定位符 (Uniform Resource Locator,URL)
HTTP 协议版本:HTTP 协议是指通信双方在通信流程和内容格式上共同遵守的标准
(2)请求头
请求头被认为是请求的配置信息,以下列举出常用的请求头信息
User-Agent:包含发出请求的用户的信息,设置 User-Agent 常用于处理反爬虫
Cookie:包含先前请求的内容,设置 Cookie 常用于模拟登陆
Referer:指示请求的来源,用于可以防止链盗以及恶意请求
(3)空行
空行标志着请求头的结束
(4)请求体
请求体根据不同的请求方法包含不同的内容
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
1.4 接收响应
爬虫的第二个步骤就是获取特定 URL 返回的响应,以提取包含在其中的数据。
同样的,响应其实是指完整响应报文,它包括四个部分:响应行、响应头、空行和响应体。
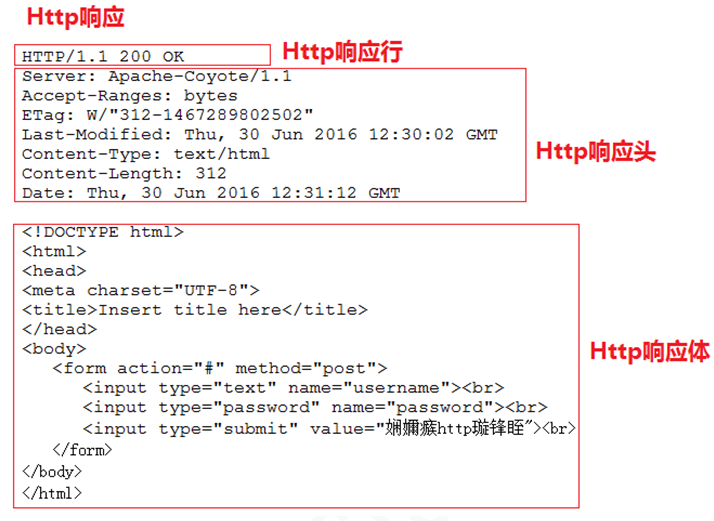
(1)响应行
响应行由 HTTP 协议版本、状态码及其描述组成。
HTTP 协议版本:HTTP 协议是指通信双方在通信流程和内容格式上共同遵守的标准。
状态码及其描述:
100~199:信息,服务器收到请求,需要请求者继续执行操作
200~299:成功,操作被成功接收并处理
300~399:重定向,需要进一步的操作以完成请求
400~499:客户端错误,请求包含语法错误或无法完成请求
500~599:服务器错误,服务器在处理请求的过程中发生错误
(2)响应头
响应头用于描述服务器和数据的基本信息,以下列举出常用的响应头信息
Set-Cookie:设置浏览器 Cookie,以后当浏览器访问符合条件的 URL 时,会自动带上该 Cooike
(3)空行
空行标志着响应头的结束。
(4)响应体
响应体就是网站返回的数据,在下一个步骤中我们需要对其进行分析处理。
1.5 解析网页
解析网页实质上需要完成两件事情,一是提取网页上的链接,二是提取网页上的资源。
(1)提取链接
提取链接实质上是指获取存在于待解析网页上的其他网页的链接。
网络爬虫需要给这些链接发送请求,如此循环,直至把特定网站全部抓取完毕为止。
(2)提取资源
提取数据则是爬虫的目的,常见的数据类型如下:
文本:HTML,JSON 等
图片:JPG,GIF,PNG 等
视频:MPEG-1、MPEG-2 和 MPEG4,AVI 等
最终,我们可以对所获得的资源作进一步的处理,从而提取出有价值的信息。