Scanner类:
从键盘获取不同类型的变量,就需要使用Scanner类
具体实现步骤:
1.导包:import java.util.Scanner;
2.Scanner的实例化:Scanner xx = new Scanner(system.in);
3.调用Scanner类的相关方法(String类型是:next()。。。其他xx类型都是nextxx(),没有char类型,因为被String代替了),来获取指定类型的变量。
注意:
根据相应的方法,来输入指定类型的值。如果输入的数据类型与要求类型不匹配时,会报异常:InputMisMatchException导致程序终止。
关于循环分支判断语句:
关于switch-case结构:
1.根据switch表达式中的值,以此匹配各个case中的常量。一旦匹配成功,则进入相应case结构中,调用其执行语句。当调用完执行语句之后,则依然继续向下执行其他case结构中的执行语句,知道遇到break关键字或此机构末尾结束为止。
2.break。可以使用在swich-case结构中,表示一旦执行到此关键字,就跳出swith-case结构
3.switch结构中的表达式,只能如下的6中数据类型之一:byte、short、int、枚举类型(JDK5.0新增)、String类型(JDK7.0新增)。
4.break关键字是可选的
5.case之后只能声明常量,不能声明范围。
6.default:相当于if-else结构中的else,default结构是可选的,而且位置灵活。
说明:
一.凡是可以使用switch-case的结构,都可以转换为if-else。反之,不成立。
二.写分支结构时,当发现既可以使用swith-case,又可以使用if-else时,优先使用switch-case,因为它的执行效率稍高一点。
对于循环结构的说明:
1.不在循环条件部分限制次数的结构:for(;;)或while(true)
2.结束循环有几种方式?
方式一:循环条件部分返回false
方式二:在循环体中,执行break
3.嵌套循环:
需要注意点:
一、内层循环结构遍历一遍,只相当于外层循环循环体执行了一次。
二、假设外层循环需要执行m次,内层循环需要执行n次。此时内层循环的循环体一共执行了m*n次。
三、外层循环控制行数,内层控制列数
关于优化方面,举个例子:
boolean iflag = true;
for (int i = 2; i < 100000; i++) {
for (int j = 2; j <= Math.sqrt(i); j++) {//优化二:减少循环范围
if (i % j == 0) {
iflag = false;
break;//优化一:被除尽了,一定不是质数了,就跳出不判断后面的j了。
}
}
if (iflag == true) {
System.out.println(i);//优化三:打印很耗时,去掉收益很高
}
iflag = true;
}
}
注意:如果不加上这些优化,效率天差地别。
关于循环的两个关键字说明:
continue和break的作用都是结束循环,但是不同的是:
contiune是结束当次循环,整体循环继续。
break是结束当前循环,直接跳出整体循环。
另外continue还有跳转用法,在一个语句前面设置一个标签xxx,然后使用continue xxx;跳转到xxx语句所在位置。
所以上述的那个例子,也可以把i%j == 0的那个判断内部换成continue xxx;xxx在第一层for循环位置。
数组的概述:
数组(Array),是多个相同类型数据按一定的顺序排列的集合,并使用一个名字命名,通过编号的方式对这些数据进行统一管理。
数组本身是引用数据类型,而数组中的元素可以是任何数据类型,包括基本数据类型和引用数据类型。
创建数组对象会在内存中开辟一整块连续的空间,而数组名中引用的是这块连续空间的首地址。
数组的长度一旦确定,就不能更改。
通过下标或索引的方式调用指定位置的元素,速度很快。
数组的分类:
按照维度:一维数组、二维数组、三维数组.....
按照元素的数据类型分:基本数据类型元素的数组、引用数据类型元素的数组(即对象数组)。
一维数组的使用:
一、数组的初始化和声明:
1.静态初始化:数组的初始化和数组元素的赋值操作同时进行。
如:int 【】xxx = new int【】{1,2,3,4};
2.动态初始化:数组的初始化和数组元素的赋值操作分开进行。
如:String 【】xxx = new String【5】;
二、如何调用数组的指定位置的元素:
通过下标(角标、索引)的方式调用。数组的索引是从0开始到数组长度-1结束。
如:xxx【0】
三、如何获得数组的长度:
属性:length,如:xxx.length获取数组长度
四、数组元素的默认初始化值:
---数组元素是整型:初始化值都是0,不管是byte、short、int、long。
---数组元素是浮点型:初始化值都是0.0,不管是float还是double
---数组元素是char型:0或者‘u0000’,而非‘0’,但是它遍历后输出出来却是类似于空格的效果,不过数值确实等于0。
---数组元素是boolean型:初始值是false。
---数组元素时引用数据类型:初始值是null
五、数组的内存解析:
先建立起一个内存结构的简单印象,如下图:
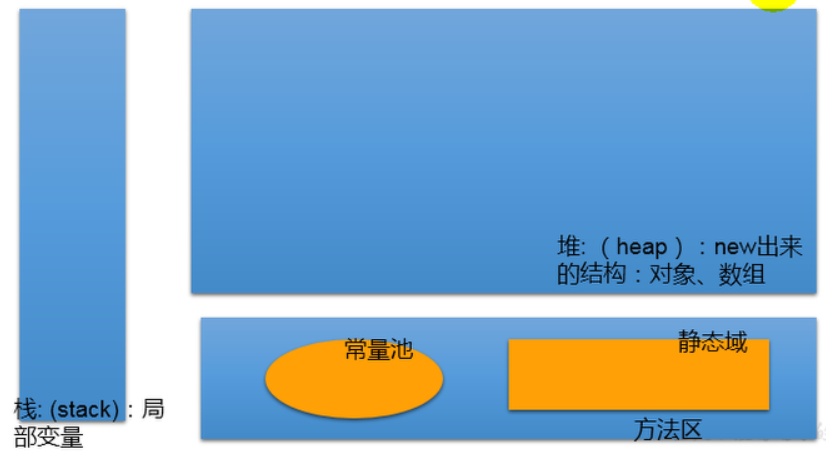
一维数组的内存过程图:
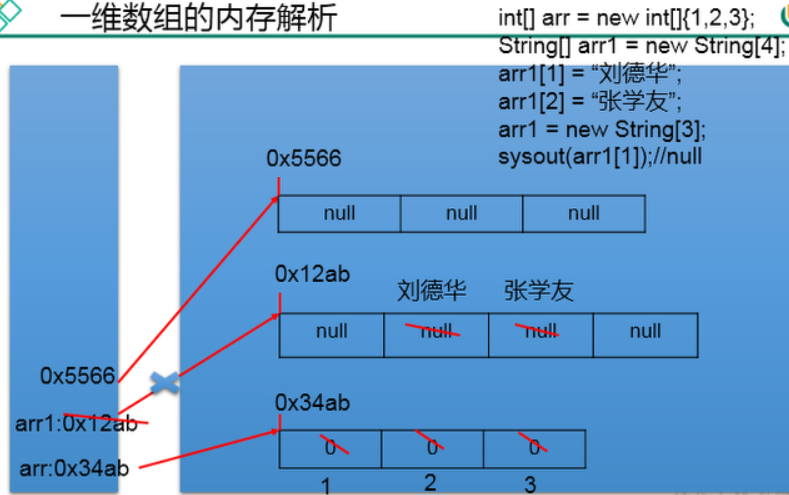
需要说明的是,图中的刘德华和张学友其实不是放在0x12ab地址中的,这个问题以后再讨论,其实他们是放在常量池里面的。
二维数组的使用:
对于二维数组的理解,可以看成是一维数组array1又作为另一个一维数组array2的元素存在。其实,从数组底层的运行机制来看,并没有多维数组,只不过是数组中的元素为数组,嵌套叠成的。
一、数组的初始化和声明:
1.静态初始化:
int [ ] [ ] xxx = new int [ ][ ]{ {1},{1,2},{1,2,3}}
2.动态初始化:
String [ ][ ] xxx = new int [2][3];
小贴士:通过类型推断还可以这么写:
String [ ][ ]xxx ={ {1},{1,2},{1,2,3}} 省略new int [ ][ ],此方法也适用与一维数组。
二、如何调用数组的指定位置的元素:
xxx【第x个数组的索引】【x数组中第x个元素】
三、如何获得数组的长度:
xxx.length 长度是有多少个数组元素,而不是有多少个元素。
xxx[0].length 这个表示第一个数组元素,它的长度。
四、如何遍历二维数组:
for(int i = 0;i < xxx.length;i++){
for(int j = 0;j < xxx[i].length;j++){
System.out.print(xxx[i][j]);
}}
五、数组元素的默认初始化值:
通过例子来看看:
int [ ] [ ] xxx = new int[4][3];
System.out.print(xxx[0]);输出的是一个地址值
System.out.print(xxx[0][0]);输出为0
由此可见,第一次输出的是外层元素的地址值,它就是数组的地址。
第二次输出就是一维数组一样理解。
二位数组的内存解析:
如图所示:
