2.1 K8S API Server分析
API Server总结:
- 提供集群管理的API接口。
- 成为集群内各个功能模块之间数据交互和通信的中心枢纽。
- 拥有完备的安全机制。
2.1.1 如何访问K8S API
K8S API通过K8S apiserver的进程提供服务,运行在单个master节点上。默认情况下,有两个端口:
- 本地端口
1. 该端口用于接收HTTP请求
2. 端口默认值为8080,修改启动参数"--insecure-port"的值修改端口号。
3. 默认IP地址是"localhost",修改"--insecure-bind-address"修改IP地址。
4. 非认证或授权的HTTP请求通过该端口访问API Server。 - 安全端口
- 该端口用于接收HTTPS请求
- 端口的默认值是6443,修改启动参数"--secure-port"的值修改端口号。
- 默认的IP地址为非本地(Non-Localhost)网络接口,通过修改"--bind-address"修改IP地址。
- 用于基于Token文件或客户端证书及HTTP Base的认证。
- 用于基于策略的授权
- K8S默认不启动HTTPS安全访问机制。
API Server既可以通过编程的方式进行访问,也可以通过curl命令直接访问。
[root@hdss7-21 ~]# curl 127.0.0.1:8080/api --header "Authorization: Bearer $TOKEN" -insecure \
> { \
> "version": [ \
> "v1" \
> ] \
> } \
>
HTTP/1.1 200 OK
Cache-Control: no-cache, private
Content-Type: application/json
Date: Tue, 21 Dec 2021 10:41:05 GMT
Content-Length: 185
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "192.168.50.21:6443"
}
]
}
参数$TOKEN为用户的token,用于安全验证机制。K8S另外还提供了kube proxy作为代理程序,既可以为K8S API Server提供反向代理,也能给客户端访问API Server提供代理,以下命令就是通过Master节点的8080端口启动代理程序。
kubectl proxy --port=8080 &
kubectl其实就是将API Server的APi进行封装,然后发起远程调用请求,可以通过kubectl --help查看具体参数。
2.1.2 通过API Server访问相关服务
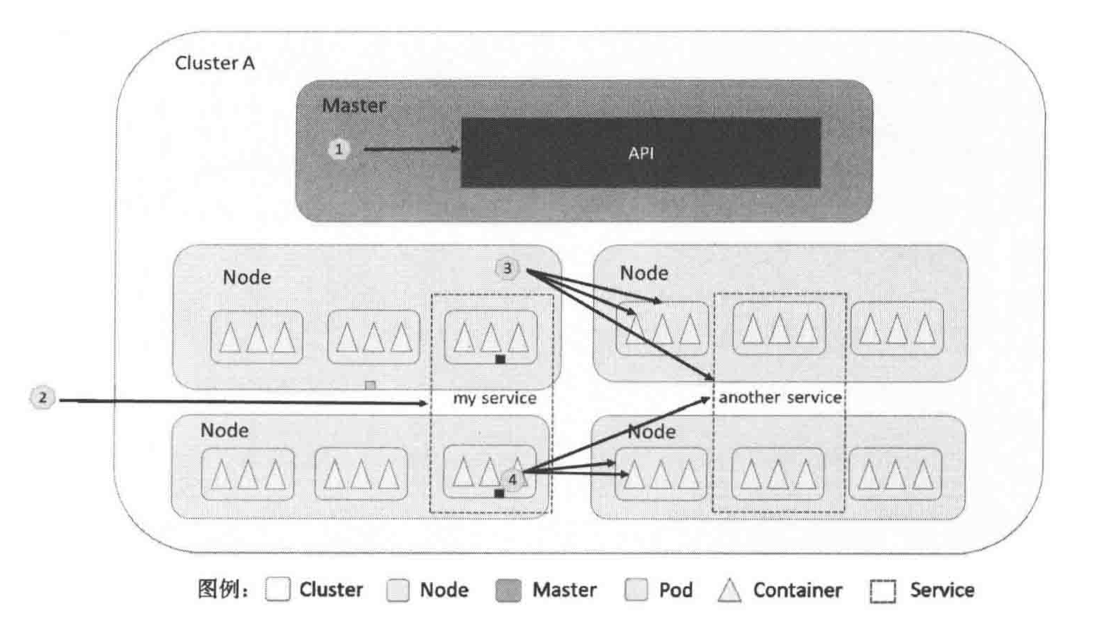
- 集群内部各组件、应用或集群外部应用访问API Server。
- 集群外部系统访问Service。
- 集群内跨节点访问Pod、Node、Service
- 集群内容器访问Pod、访问其他集群内容器、访问Service
集群外系统可以通过访问API Server提供接口管理Node节点,访问路径为/api/v1/proxy/nodes/{name},name为节点的名称或IP地址,该接口除了支持增删改查的方法,还有其他接口,可以查阅文档。
2.1.3 集群功能模块之间的通信
API Server作为集群的核心,负责集群个功能模块之间的通信。比如Node节点上的kubelet每隔一个时间周期,通过API Server报告自身状态,API Server将接收到的信息保存到etcd中,Controller Manager中的Node Controller通过API Server定期读取etcd中的相关信息去做进一步处理。
为了缓解集群各模块对API Server的访问压力,各功能模块都采用缓存机制来缓存数据。
2.2 调度控制原理
Controller Manager作为集群内的管理控制中心,负责集群内的Node、Pod Replication、EndPoint,NameSpace、ServiceAccount、ResourceQuota、Token、Service的管理并执行自动化修复流程,确保集群处于预期的工作状态。
2.2.1 Replication Controller
Replication Controller确保在任何时候集群中一个RC所关联的Pod都保持一定数量的Pod副本处于正常运行状态。实现自动创建、补足、替换和删除Pod副本。即使集群的应用程序只用到一个Pod副本,也强烈建议使用RC来定义Pod。
而Service可能由被不同RC管理的多个Pod副本组成,Service自身及其客户端应该不需要关注RC。
Pod状态:
- pending:API Server已经创建该Pod,但Pod内还有一个或多个容器的镜像没有创建。
- running:Pod内所有的容器均已创建,且至少有一个容器处于运行状态或正在启动或重启。
- succeeded:Pod内所有容器均成功中止,且不会再重启。
- failed:Pod内所有容器均已退出,且至少有一个容器因为发生错误而退出。
Pod重启策略(RestartPolicy):
- Always
- OnFailure
- Never
当Pod处于succeeded或failed状态的时间过长(超时参数由系统设定)时,且RestartPolicy = Always,管理该Pod的副本控制器将在其他工作节点上重新创建、运行该Pod副本。
RC模板
Pod实例都是通过RC里定义的Pod模板(Template)创建,其中包含一个Label Selector,表明了该RC所关联的Pod。通过RC创建的Pod副本在初始阶段状态是一致的,从某种意义上讲完全可以互相替换,这种特性非常适合副本无状态服务。
Pod模板相当于创建Pod的模具,一旦Pod被创建,无论模板如何变化,也不会影响到已经创建的Pod。Pod还可以通过修改它的标签来脱离RC的管控,可以用于将Pod从集群中前一、数据修复等调试。
删除一个RC并不会影响它所创建的Pod,如果想删除一个RC所控制的Pod,可以将RC的副本数(Replicas)的值设为0。
RC常用使用模式
-
Rescheduling(重新调度)
-
Scaling(弹性伸缩)
kubectl scale --replicas=3 replicationcpntrollers foo -
Rolling Updates
通过逐个替换Pod的方式来辅助服务的滚动更新。比如:创建一个新的只有一个Pod副本的RC,如果新的RC副本数量加一,则旧的RC副本数减一,直到旧的RC副本数为0,然后删除旧的RC。
kubectl rolling-update frontend-v1 -f frontend-v2.json
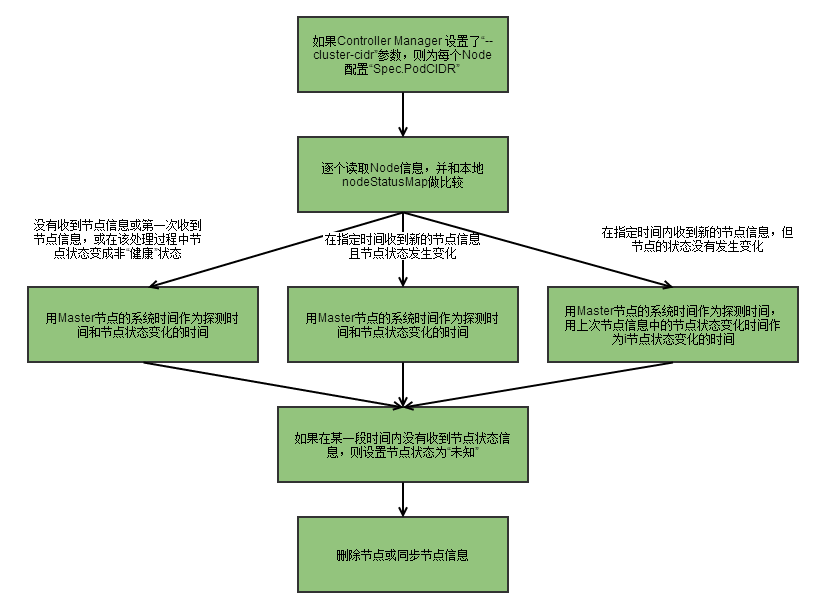
2.2.2 Node Controller
Node Controller负责发现、管理和监控集群中的各个Node节点。kubelet定时发送到API Server的节点信息包括健康状态、节点名称、节点资源等。节点健康状态包括就绪(True)、未就绪(False)和未知(Unknown),可以使用如下命令获取node的详细信息,并以json格式输出。
kubectl get no -ojson
Node Controller处理流程:
-
Controller Manager在启动时如果设置了
--cluster-cidr参数,那么为每个没有设置spec.PodCIDR的Node节点生成一个CIDR地址,并用该CIDR地址设置节点的spec.PodCIDR属性,防止不同节点的CIDR地址冲突。 -
逐个读取节点信息,将该节点的信息和Node Controller的nodeStatusMap中保存的节点信息做比较,如果没有收到kubelet发送的节点信息,或者是第一次接收到信息,又或者在该处理过程中节点状态变成非“健康”状态,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化的时间。如果收到信息,但是和上次对比没有发生变化,则修改探测时间,而不修改变化时间。
如果在某一段时间内(gracePeriod)没有收到节点状态信息,则修改节点状态为Unknown,并通过API Server保存节点状态。
-
逐个读取节点信息,如果节点状态变为非“就绪”态,则将节点加入待删除队列。如果节点变为非“就绪态”,且系统指定了Cloud Provider,则Node Controller调用Cloud Provider查看节点,如果发现节点故障,则删除etcd中的信息,并删除和该节点相关的Pod等资源信息。
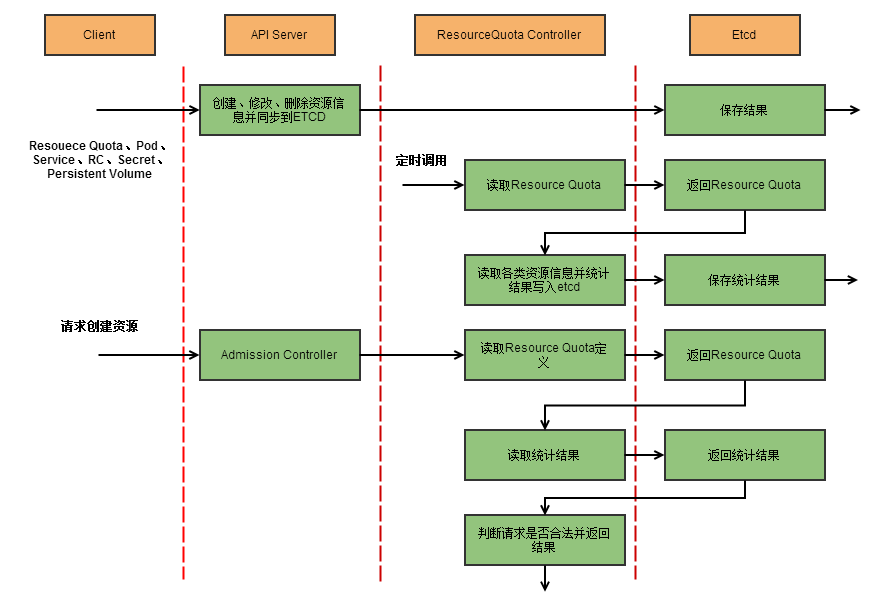
2.2.3 ResourceQuota Controller
资源配额管理
-
容器级别:可以对CPU、Memory限制
-
Pod级别:可以对一个Pod内所有容器的可用资源进行限制
-
Namespace级别:为Namespace(可以用于多租户)级别的资源限制,包括:
Pod数量、RC数量、Service数量、ResourceQuota数量、Secret数量、可持有的P V(Persistant Volume)数量
K8S配额管理是通过准入机制(Admission Control)来实现,与配额相关的两种准入控制器是LimitRange和ResourceQuota,前者作用于容器和Pod,后者作用于Namespace。
2.2.4 Namespace Controller
关键词:Terminating、Deletion Timestam、spec.finalizers阈值为空
2.2.5 ServiceAccount Controller与Token Controller
ServiceAccount Controller在Controller manager启动时被创建,它监听Service Account的删除事件、Namespace的创建、修改事件,并且当default Service Account不存在时会自动创建。
在API Server启动参数中添加"--admission_control=ServiceAccount"后,API Server在启动时会自动创建key和crt(/var/kubernetes/apiserver.crt和apiserver.key),启动controller manager时指定key和crt的路径,可以发现在创建Service Account时,会自动创建一个Secret。
Token Controller对象监听Service Account的创建、修改和删除事件,根据不同的事件做不同的处理。
2.2.6 Service Controller与Endpoint Controller
K8S中的Service也是一种资源对象。
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"tatgetPort": 8080
}
]
}
}
pod集合中的每个pod的80端口被映射到本地节点的8080端口。
某些场景下,需要创建一个不带标签选择器的Service。
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 8080
}
]
}
}
系统不会自动创建Endpoint,因此需要手动创建一个和该Service同名的Endpoint,用于指向实际的后端访问地址。
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"subsets": [
{
"addresses": [{ "IP": "10.4.21.3", }],
"ports": [{ "port": 80 }]
}
]
}
在K8S集群中,每个节点上都运行着“kube-proxy”的进程,该进程会监听K8S Master节点添加和删除Service和Endpoint的行为,kube proxy在本地主机上为每个Service随机开一个端口,并通过Round Robin算法及Session Affinity决定选择哪个Pod,然后kube proxy在本机的Iptables上安装相关规则,这些规则使得Iptables将捕获的流量重定向到开通的随机端口上,通过该端口的流量在被kube proxy转到相应的后端Pod上。
如果用户手动为Service指定集群IP,需要在定义Service时,在spec.clusterIP域中设置IP即可,设置的IP必须在集群的CIDR范围内,否则API Server会返回HTTP 422状态码。
K8S支持两种主要的模式来找到Service:容器的Service环境变量、DNS。
K8S既支持Docker links变量,也支持"{SVCNAME_SERVICE_HOST}"的变量,Service Name中包含的"-"会转换成"_"符号。通过环境变量来找到Service,需要与Pod相关的Service优先于Pod被创建,否则,和这个后创建的Service相关的环境变量,都不会被加入到该Pod的容器中。
另一个通过名字找到服务的方式是DNS,DNS服务器通过K8S API监控与Service相关的活动,当监控到添加了新的Service时,DNS服务器会为每个Service创建一系列DNS记录,DNS返回的查找结果时集群IP(虚拟IP、Cluster IP)。
集群外部用户访问集群内的Service,可以通过"NodePort"和"LoadBalancer"来实现,每个Service定义的"spec.type",有三个参数:
- ClusterIP:默认值,仅使用集群内部虚拟IP(集群IP、Cluster IP)
- NodePort:使用虚拟IP,同时通过在每个节点上暴露相同的端口来暴露Service。
- LoadBalancer:使用虚拟IP和NodePort,同时请求云服务商作为转向Service的负载均衡器。
通过定义spec.type为NodePort后,再定义spec.ports.nodePort实现自定义暴露端口,注意,不同K8S版本的端口范围不一样。通过这种方式,可以自由的配置负载均衡器。
2.2.7 kube Scheduler
kube Scheduler负责接收Controller Manager创建的Pod,按照特定的算法和策略绑定(Binding)到集群的某个Node上,并将绑定信息写入etcd中,然后由目标Node上的Kubelet服务进程接管后续工作。
kube Scheduler默认调度流程:
- 预选调度过程,遍历所有的目标Node,筛选出符合要求的候选节点(K8S内置来多种筛选策略)。
- 确定最优节点,采用相关策略计算出候选节点的积分,最优者胜出。
kube Scheduler的调度流程是通过插件的方式加载的“调度算法提供者”(AlgorithmProvider)实现的,其实就是包括了一组“预选策略”和一组“优选策略”的结构体。
相关策略有很多,就不一一举例,请查阅相关文档。
2.3 Kubelet运行机制分析
每个Node上的Kubelet进程会在API Server上注册节点和自身信息,定期向Master节点汇报节点资源使用情况,并通过cAdvise监控容器和节点资源。
2.3.1 节点管理
节点通过设置Kubelet的启动参数"--register-node",来决定是否向API Server注册自己,如果为false,则需要手动配置Node的资源信息等,其他参数:
- --api-servers:告诉Kubelet API Server的位置
- --kubeconfig,告诉Kubelet证书位置
- --cloud-provider:告诉Kubele如何从云服务商获取相关元数据
- --node-status-update-frequency:设置上报节点状态间隔时间,默认10秒
2.3.2 Pod管理
kubelet通过一下几种方式获取自身Node上所要运行的Pod清单。
- 文件:Kubelet启动参数"--config"指定的配置文件目录(默认为"/etc/kubernetes/mainfests")。通过--file-check-frequency设置检查该文件目录的时间间隔,默认为20秒。
- HTTP端点:--manifest-url,时间间隔默认为20秒。
- API Server
所有以非API Server方式创建的Pod都叫做static Pod。
Kubelet创建和修改Pod请求处理流程:
-
为该Pod创建一个数据目录
-
从API Server读取Pod清单
-
为该Pod挂载外部卷(External Volume)
-
下载Pod用到的Secret
-
检查节点中已经在运行的Pod,如果该Pod没有容器或Pause容器(kubernetes/pause镜像创建的容器)没有启动,则先停止Pod里所有容器的进程。如果在Pod中有需要删除的容器,则先删除。
-
每个Pod创建之前,都会先用pause镜像为每个Pod创建一个容器,该pause容器用于接管Pod中所有其他容器的网络。
-
为Pod中每个容器做如下处理:
- 为容器计算一个hash值,用容器的名字去Docker查询对应容器的hash值。如果找到容器且两者hash值不同,则停止Docker中的容器与Pause容器。
- 如果容器被终止了,且容器没有指定的重启策略,则不做处理。
- 调用Docker Client下载容器镜像,调用Docker Client运行容器。
2.3.3 容器健康检查
Pod通过两类探针来检查容器的健康状态:
- LivenessProbe:如果LivenessProbe探测到容器不健康,则通知Kubelet,Kubelet将删除该容器,并根据重启策略做处理。如果一个容器没有该探针,则Kubelet认为该容器的LivenessProbe探针的返回值永远为"Success"。
- ReadinessProbe:用于判断容器是否启动完成,且准备接收请求。如果ReadinessProbe探针检测到失败,则Pod的状态将被修改,Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP地址的Endpoint条目。
ReadinessProbe三种实现方式:
- ExecAction:在容器内部执行一个命令,返回的状态码为0则表示容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果端口能访问,则表示容器健康。
- HTTPGetAction:通过容器的IP地址和端口号及路径调用HTTP Get方法,如果状态码大于等于200且小于等于400,则认为容器健康。
2.4 安全机制的原理
集群的安全性考虑指标:
- 保证容器与其所在的宿主机的隔离
- 限制容器给基础设施及其他容器带来的消极影响的能力
- 最小权限原则——组件的权限
- ˜明确组件间边界的划分
- 普通用户与管理员的角色划分
- 在必要的时候允许将管理员权限赋给普通用户
- 允许拥有"Secret"数据(Keys、Certs、Passwords)的应用在集群中运行
2.4.1 Authtication
K8S对API调用使用CA(Client Authentication)、Token、和HTTP Base方式实现用户认证。
CA是PKI系统中通信双方都信任的实体(Trusted Third Party,TTP)。CA作为可信第三方的重要条件之一就是CA的行为具有“不可否认性”。
K8S中的CA认证方式通过添加API Server的启动参数"--client_auth_files=证书文件"实现,该证书文件包含一个或多个证书颁发机构(CA Certificates Authorities)。
Token认证方式通过添加API Server启动参数"--token_auth_file=Token文件"实现,Token认证中的Token是永久有效的,而且Token列表不能被修改,除非重启API Server。Token文件是一个包含三个字断的CSV文件,第一个字段为Token,第二个为用户名,第三个为用户UID。
2.4.2 Authorization授权
在K8S中,授权(Authorization)是认证(Authentication)后的一个独立步骤,作用于API Server主要端口的所有HTTP访问。授权流程通过访问策略比较请求上下文的属性(例如:用户名、资源、Namespace)。通过API访问资源之前,必须通过访问策略进行校验。访问策略通过API Server的启动参数"--authorization_mode"配置,三个参数值:
-
"--authorization_mode=AlwaysDeny"
-
"--authorization_mode=AlwaysAllow"
-
"--authorization_mode=ABAC"
Attribute-Based Access Control,使用用户配置的授权策略去管理访问API Server的请求,ABAC为基于属性的访问控制。
在K8S中,一个HTTP请求包含如下4个能被授权进程识别的属性:
- 用户名
- 是否是只读请求
- 被访问的资源类型
- 被访问的对象所属Namespace,如果这被访问的资源不支持Namespace,则是空字符串。
如果请求中不带某些属性,则这些属性的值该根据值的类型设置成对应类型的零值。
如果选用ABAC模式,那么需要设置API Server的"--authorization_policy_file=策略文件"来指定。授权策略文件的每一行都是一个Map类型的JSON对象,这个Map内不包含List和Map,该对象包含4个属性:
- user,string
- readonly,bool类型,当为true时,表明该策略允许GET请求通过。
- resource,string,来自于URL的资源,比如:pods。
- namespace,string,表明该策略允许访问某个Namespace。
如果请求中不带某些属性,则这些属性的值该根据值的类型设置成对应类型的零值。
{
{"user":"alice"}, # 允许alice做任何事
{"user": "kubelet", "resource": "pods"}, # kubelet能读写pods资源
{"user": "bob", "resouce": "event", "readonly": "true"}
}
2.4.3 Adminssion Control准入控制
Admimssion Control用于拦截所有经过认证和鉴权后的访问API Server请求的插件(可插入代码,必须被编译成二进制文件)。在API Server的启动参数"admission_control"中加入需要加载的Admission Control插件列表,各插件的名称之间用逗号隔开。
Admission Control插件列表
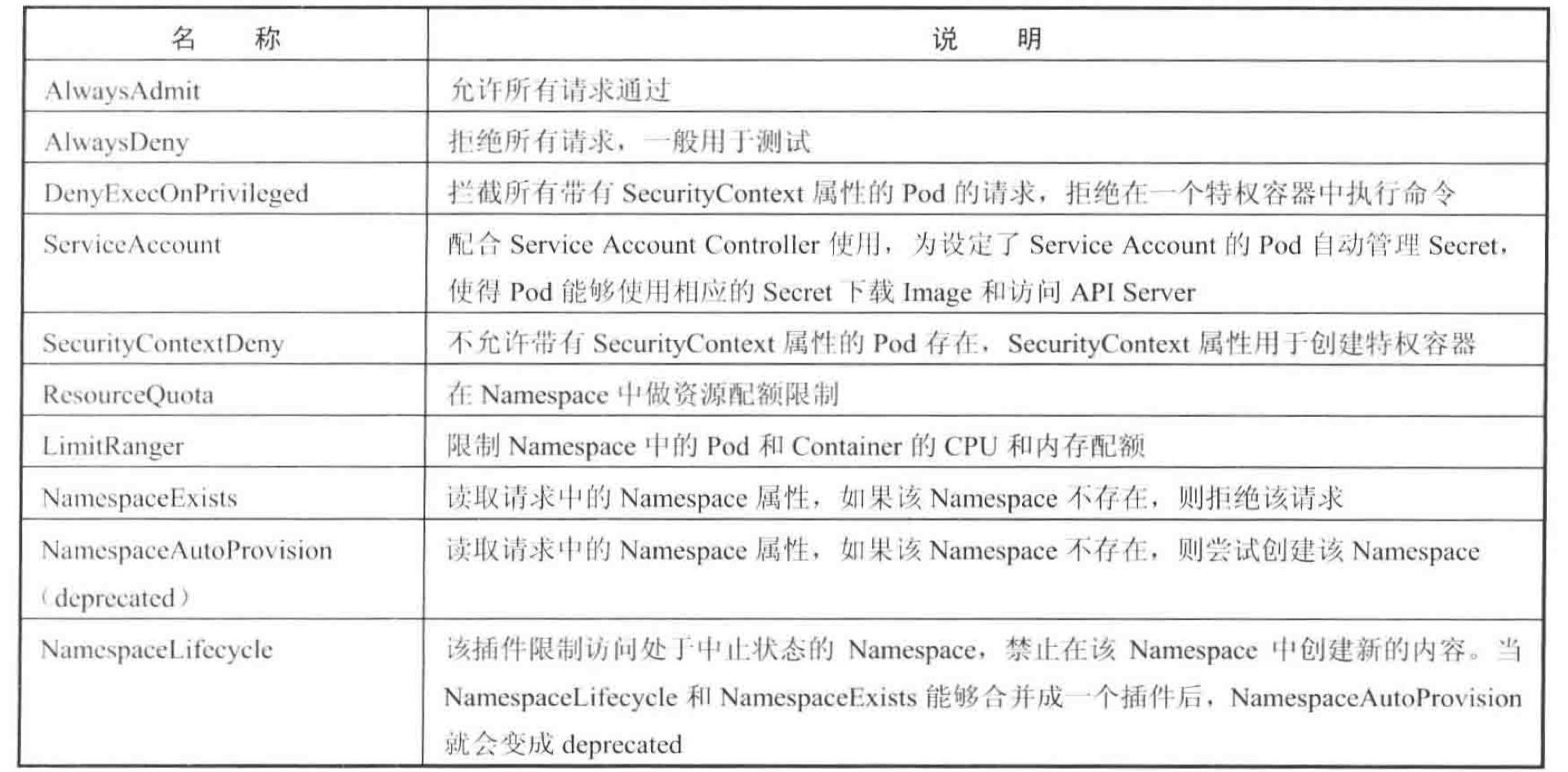
-
Security Context:是运用于容器的操作系统安全设置(uid、gid、capabilities、SELinux role等)。
-
ResourceQuota:能限制某个Namespace中被Pod所请求的资源总量,实现对资源配额管理。
资源配额数量不仅包括pods、services、replicationscontrollers等数量
还包括cpu、内存
-
LimitRange:限制Namespace中Pod和container资源的范围及默认值。
cpu、内存
2.4.4 Secret
Secret主要作用是用于保管密码、OAuth Tokens等私密数据。
apiVersion: v1
kind: secret
metadata:
name: mysecret
type: Opaque
data:
# data中的值必须是base64的值
username: dXNlcm5hbWUK # username
password: cGFzc3dvcmQK # password
一旦Secret被创建,则可以通过三种方式使用它:
- 创建Pod时,通过为Pod指定Service Account来自动使用。
- 通过挂载Secret到Pod上。
- 创建Pod时,指定Pod的spec.ImagePullSecrets来引用它。
以下是第二种——通过挂载来实现
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "mypod",
"namespace": "myns"
},
"spec": {
"containers": [{
"name": "mycontainers",
"image": "redis",
"volumemounts": [{
"name": "foo",
"mountPath": "/etc/foo",
"readOnly": true
}]
}],
"volumes": [{
"name": "foo",
"secret": {
"secretName": "mysecret"
}
}]
}
}
第三种则是手动使用imagePullSecret,具体流程:
- 执行login命令,登录私有仓库(registry)
- 首次登录的话,相关信息会写入
~/.dockercfg文件中 - 文件中内容被base64编码后,配置到secret中的"data.dockercfg"域中,以此来创建一个secret
- 创建Pod时,引用该Secret
注意:
-
Pod创建时会验证所挂载的Secret是否真的指向一个Secret对象,因此,Secret对象必须在任何引用它的Pod之前被创建。Secret对象属于Namespace,它们只能被同一个Namespace中的Pod所引用。
-
每个单独的Secret大小不能超过1MB,K8S不鼓励创建大的Secret,否则会占用大量API Server和Kubelet内存。(多个小的Secret同样也会占用大量资源)。
-
Kubelet只支持Pod使用由API Server创建的Secret。Pod包括Kubectl创建的Pod或简洁被Replication Controller创建的Pod。
Secret类型:
- Opaque
- Service Account
- Dockercfg
2.4.5 Service Account
Service Account是多个Secret的集合,它包含两类Secret:
- 普通Secret,用于访问API Server,也被称为Service Account Secret
- ImagePullSecret,用于下载容器镜像
通过下面命令查询service Account列表
kubectl get serviceAccounts
创建Pod时,可以通过spec.serviceAccountName来指定名称,如果不指定,则系统会自动指定在同一命名空间(Namespace)下的名为“default”的Service Account。
在系统自动化的过程中,Service Account会和下面三个功能一起工作:
- Admission Controller
- Token Controller
- Service Account Controller
2.5 网络原理
2.5.1 K8S网络模型
K8S网络模型设计的一个基础原则是:每个Pod都有一个独立的IP地址(从docker0网卡进行分配),一个Pod内部所有容器共享一个网络堆栈(实际上就是一个网络命名空间,包括它们的IP地址、网络设备、配置等都是共享的),按照这个网络原则抽象出来的一个Pod一个IP的设计模型也被称作为IP-per-Pod模型。因此,同一个Pod内的不同容器,可以通过localhost进行访问。
在Docker原生的端口映射中,会因为NAT导致服务自身很难知道自己对外暴露的真实的服务IP和端口,而外部应用也无法通过服务所在容器的私有IP地址和端口来访问服务。而IP-per-Pod模型可以被看作为是一台独立的“虚拟机”或“物理机”。
因此,K8S对集群的网络要求是:
- 所有容器都可以在不同NAT的方式下与别的容器通信。
- 所有节点都可以在不同NAT的方式下与所有容器通信,反之亦然。
- 容器地址和别人看到的地址是同一个地址。
2.5.2 Docker的网络基础
1、网络的命名空间
为了支持网络协议栈的多个实例,Linux在网络栈中引入了网络命名空间(Network Namespace),这些独立的协议栈被隔离到不同的命名空间中。不同命名空间的网络栈是完全隔离的,相互之间无法通信。在Linux网络命名空间内,可以有自己独立的路由表和独立的IPtables/Netfilter设置来提供包转发、NAT及IP包过滤等功能。
命名空间中的元素包括:进程、套接字、网络设备等。
1、网络命名空间的实现
Linux的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须修改为协议栈私有,通过协议栈的函数调用加入一个Namespace参数,就是Linux实现网络命名空间的核心。
新生成的私有命名空间只有停止状态的回环lo设备,其他设备则需要手工建立,Docker容器中的各类网络栈设备都是Docker Daemon在启动时自动创建和配置的。
Veth设备对可以让不同命名空间的网络相互通信,甚至和外部网络进行通信。
2、网络命名空间操作
# 添加命名空间
ip netns add <name>
# 在命名空间内执行命令
ip netns exec <name> <command>
# 进入网络命名空间
ip netns exec <name> bash
其他,略。
2、Veth设备对
略。
3、网桥
网桥是一个二层网络设备,可以解析收发的报文,读取目标MAC地址信息,和自己记录的MAC表相结合,来决策报文的转发端口。
Linux内核支持网口的桥接(目前只支持以太网接口),和单纯的交换机不同,交换机只是一个二层设备,对于接收到的报文,要么转发,要么丢弃。运行着Linux内核的机器本身就是一台主机,有可能是网络报文的目的地,其收到的报文除了转发和丢弃报文外,还可能被送到网络协议栈的上层(网络层),从而被自己(这台主机本身的协议栈)消化。
1、Linux网桥的实现
Linux内核时通过一个虚拟的网桥设备(Net Device)来实现桥接的。这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。
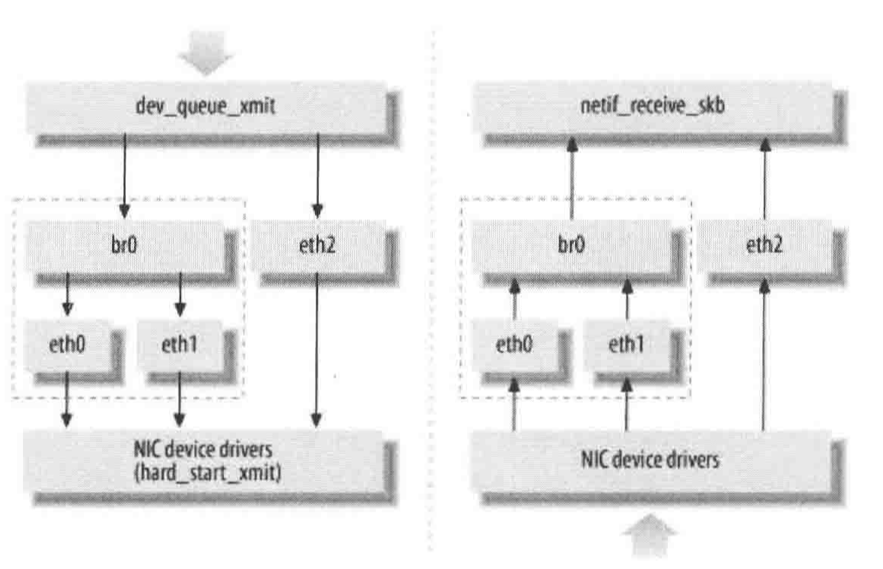
对于上图,网桥设备br0绑定了eth0和eth1.对于网络协议栈的上层来说,只看得到br0。因为桥接是在数据链路层实现的,上层不需要关心桥接的细节,于是协议栈上层需要发送的报文被送到br0,网桥设备的处理代码判断报文该被转发到eth0还是eth1,或者都转发。而有时eth0、eth1也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收,从而绕过网桥。
2、网桥的常用操作命令
略。
4、Iptables/Netfilter
Netfilter负责在内核中执行各种挂接的规则,运行在内核模式中,而Iptables是在用户模式下运行的进程,负责协助维护内核中Netfilter的各种规则表。通过二者的配合来实现整个Linux网络协议栈中灵活的数据包处理机制。
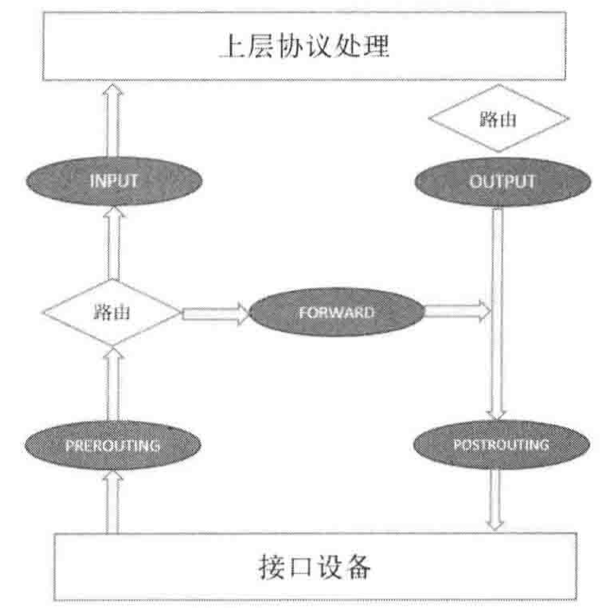
Netfilter可以挂接的规则点有五个,包括:INPUT、OUTPUT、FORWARD、PERROUTING、POSTROUTING。
2.5.3 Docker网络实现
在K8S中,通常只会使用bridge模式。
在bridge模式下,Docker Daemon第一次启动时会创建一个虚拟的网桥,缺省的名字是docker0,然后按照RPC1918模型,在私有网络空间中给这个网桥分配一个子网。由Docker创建出来的容器,都会创建一个虚拟的以太网设备(Veth设备对),其中一段关联到网桥上,另一端使用Linux的网络命名空间技术,映射到容器内的eth0设备,然后从网桥的地址段内给eth0接口分配一个IP地址。
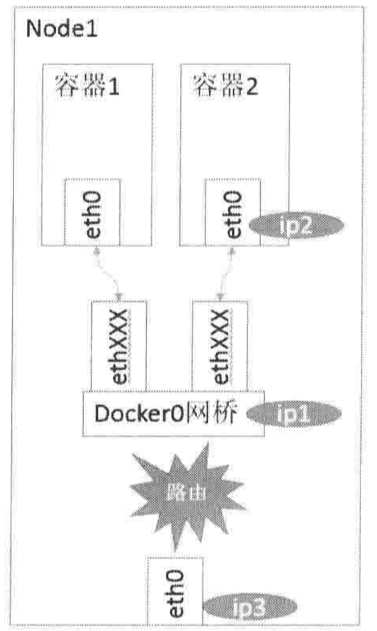
根据上图可以知道,同一台机器的不同机器之间可以通过Docker0网桥实现通信,而不同主机上的容器不能相互通信,即使Docker0网桥地址段范围相同。
1、查看Docker启动后的系统情况
通过查看iptables规则可以发现其中一条规则是:
-A POSTROUTING -s 172.7.0.0/16 ! -o docker0 -j MASQUERADE
若本地数据包不是发网docker0的,而是发往宿主机之外的设备的,都要进行动态地址修改(MASQUERADE),将源地址从容器的地址(172.7段)修改为宿主机网卡的IP地址之后再发送。
Linux的ip_forward功能也会被Docker Daemon打开:
~] cat /proc/sys/net/ipv4/ip_forward
1
2.5.4 K8S的网络实现
K8S网络的设计主要致力于解决一下场景:
- 紧密耦合的容器到容器之间的直接通信。
- 抽象的Pod到Pod之间的通信。
- Pod到Service之间的通信。
- 集群外部与内部组件之间的通信。
1、容器到容器的通信
在同一个Pod内的容器(Pod内的容器默认情况下是不会跨宿主机的)共享同一个网络命名空间,共享同一个Linux协议栈。
2、Pod之间的通信
每一个Pod都有一个真实的全局IP地址(Pod-per-IP),同一个Node内的不同Pod之间可以直接使用对方Pod的IP地址通信,且不需要其他发现机制,例如DNS或etcd等。
1、同一个Node内的Pod之间的通信
通过Docker0网桥。
2、不同Node内的Pod之间的通信
Pod的地址是与docker0在同一个网段内的,和docker0是不同的网段,不同Node之间的通信只能通过宿主机的网卡进行。
K8S会记录所有正在运行Pod的IP分配信息,并保存在etcd中(Service Endpoint)。
因此,想要支持在不同Node上的Pod之间的通信,需要有两个条件:
- K8S的集群中,对Pod的IP的分配不能有冲突。
- 将Pod的IP和所在Node的IP关联起来,使不同Node之间的Pod能够互相访问。
3、Pod到Service之间的通信
之前已经提到,为了支持集群的水平扩展、高可用性,K8S抽象出Service的概念。K8S在创建服务时,会为服务分配一个虚拟的IP地址,客户端通过这个虚拟的IP地址来访问服务,而服务端则负责将请求转发到后端的Pod上。
Service只是一个概念,真正将Service的作用落实的是kube-proxy进程。在K8S集群的每个Node上都会运行一个kube-porxy服务进程,kube-proxy相当于是Service的透明代理兼负载均衡器,核心功能就是将到某个Service的请求转发到后端的多个Pod实例上。
对每一个TCP类型的K8S Service,kube-proxy都会在本地Node上建立一个SocketServer来负责接收请求,然后均匀发送到后端某个Pod的端口上,K8S也提供修改Service的service.spec.sessionAffinity参数的值来实现会话保持性的定向转发,如果设置的值为"ClientIP",则将来自同一个ClientIP的请求都转发到同一个后端Pod上。
此外,Service的Cluster IP与NodePort等概念是kube-proxy通过Iptables的NAT转换实现的,kube-proxy在运行中动态创建与Service相关的Iptables规则,这些规则实现了Cluster IP及NodePort的请求流量重定向到kube-proxy进程上对应服务的代理端口的功能。一般每个K8S的Node节点上都会运行kube-proxy组件。
4、外部到内部的访问
K8S支持两种对外提供服务的Service的Type定义:NodePort和LoadBalance。
1、NodePort
在定义Service时指定spec.type=NodePort,并指定spec.ports.nodePort的值,系统就会在K8S集群中的每个Node上打开一个主机上的真实端口号,这样,通过访问Node的该端口号就能访问到内部的Service了。
2、LoadBalance
如果云服务商支持外接负载均衡器,则可以通过spec.type=LoadBalance定义Service,同时需要指定负载均衡器的IP地址,使用这种类型需要指定Service的nodePort和clusterIP。
2.5.5 开源的网络组件
需要自己实现一个网络,能将不同节点上的Docker容器之间的互相访问打通,然后运行K8S。
1、Flanner
Flannel能实现以下两点:
- Flannel能协助K8S,给每一个Node上的容器分配互相不冲突的IP地址。
- 能在这些IP地址之间建立一个叠加网络(Overlay Network),通过这个叠加网络,将数据包原封不动的传递到目标容器内。
flanneld处理流程:
flanneld首先连接上etcd,利用etcd来管理可分配的IP地址段资源,同时监控etcd中每个Pod的实际地址,并在内存中建立一个Pod节点路由表,然后下连docker0和物理网络,使用内存中的Pod节点路由表,将docker0发给它的数据包进行包装,利用物理网络的连接将数据包投递到目标flanneld上,从而完成Pod到Pod之间的直接的地址通信。
Flannel之间的底层通信协议有:UDP、VxLan、AWS VPS等,常用的是UDP。
flannel之所以能做到不同Node上的Pod分配的IP不产生冲突,是因为它每次分配的地址段通过etcd去获取,flannel通过修改Docker的启动参数(/etc/docker/daemon.json)将分配给它的地址段传递出去
--bip=172.7.21.1/24
这样就保障了所有Pod的IP地址不产生冲突。引入flannel后,会有一定的网络时延的损耗。
2、Open Switch
略。
3、直接路由
部署MultiLayer Switch实现。(添加静态路由表)。