网络性能评估
在Linux中常见的网络性能指标如下
l 带宽
表示链路的最大传输速率,单位是b/s 比特/秒,在位服务器选网卡时,带宽就是最核心的参考指标,常用的带宽有1000M,10G,40G,100G等
网络带宽测试,测试的不是带宽,而是网络吞吐量,Linux服务器的网络吞吐量一般会比带宽小,而对交换机等专门的网络设备来说,吞吐量一般会接近带宽
l 吞吐量
表示没有丢包时最大的数据传输速率,单位通常是b/s比特/秒,或B/s字节/秒,吞吐量受带宽的限制,吞吐量/带宽也是该网络链路的使用率
l 延迟
表示从网络请求发出后,一直到收到远端响应所需要的时间延迟,这个指标在不同场景中有不同含义,它可以表示建立连接需要的时间(TCP握手延时),或者一个数据包往返所需时间RTT
l PPS
Packet Per Second,表示已网络包为单位的传输速率,PPS通常用来评估网络的转发能力,基于Linux服务器的转发,很容易受到网络包大小的影响(交换机通常不会受太大影响,交换机可以线性转发)
PPS,通常用在需要大量转发的场景中,而对TCP或者Web服务器来说,更多会用并发连接数和每秒请求数(QPS Query per Second)等指标,他们更能反映实际应用程序的性能
网络测试基准
Linux网络基于TCP/IP协议栈,不同协议层的行为不同,在测试之前,根据应用程序基于的协议层进行针对性网络性能评估,比如:
基于HTTP或HTTPS的Web应用程序,属于应用层,需要我们测试HTTP/HTTPS的性能
大多数游戏服务器,为了支持更大的同时在线人数,通常会基于TCP或UDP,与客户端交互,这时就需要测试TCP/UDP的性能
针对把Linux作为一个软交换机或路由器来用的场景,需要关注网络包的处理能力PPS,重点关注网络层的转发性能
低层协议是其上的各层网络协议的基础,低层协议的性能,也就决定了高层网络性能
转发性能
网络接口层和网络层,主要负责网络包的封装,寻址,路由,转发和接收,在这两个网络协议层中,每秒可以处理的网络包数PPS,就是最终的性能指标,特别是64B小包的处理能力,值得我们特别关注?????
PPS包转发率
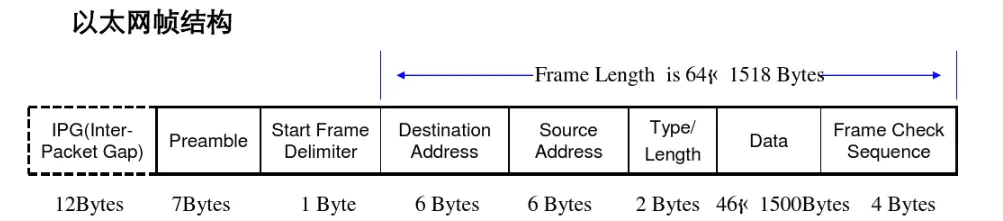
传输过程中,帧之间有间距(12个字节),每个帧前面还有前导(7个字节)、帧首界定符(1个字节)。
帧理论转发率= BitRate/8 / (帧前导+帧间距+帧首界定符+报文长度)
最大吞吐量(最大帧大小:1538B,最大以太帧大小:1518B)
最大的以太网吞吐量是通过单个传输节点实现的,当以太网帧处于最大大小时,该传输节点不会发生任何冲突。
以太网的帧开销是18字节,目的MAC(6)+源MAC(6)+Type(2)+CRC(4)。局域网规定IP最大传输单元1500字节,实际上加上以太网帧的18字节,再加上8B就是1518字节
最大帧率(最小帧大小:84B,最小以太帧:64B,最小以太网帧有效载荷:46B)
以太网是无连接的,不可靠的服务,采用尽力传输的机制。IEEE标准,一个碰撞域内,最远的两台机器之间的round-trip time 要小于512bit time.(来回时间小于512位时,所谓位时就是传输一个比特需要的时间)。这也是我们常说的一个碰撞域直径。512个位时,也就是64字节的传输时间,如果以太网数据包大于或等于64个字节,就能保证碰撞信号到达A的时候,数据包还没有传完。这就是为什么以太网要最小64个字节,同样,在正常的情况下,碰撞信号应该出现在64个字节之内,这是正常的以太网碰撞,如果碰撞信号出现在64个字节之后,叫 late collision。这是不正常的。
以太网链路的最大帧速率和吞吐量计算
|
框架部分 |
最小镜框尺寸 |
最大画面尺寸 |
|
帧间间隙(9.6毫秒) |
12字节 |
12字节 |
|
MAC前置码(+ SFD) |
8字节 |
8字节 |
|
MAC目标地址 |
6个字节 |
6个字节 |
|
MAC源地址 |
6个字节 |
6个字节 |
|
MAC类型(或长度) |
2字节 |
2字节 |
|
有效载荷(网络PDU) |
46个字节 |
1,500字节 |
|
校验序列(CRC) |
4字节 |
4字节 |
|
总框物理尺寸 |
84字节 |
1,538字节 |
理论上限
百兆端口线速包转发率=100Mbps/672=0.1488095Mpps,约等于0.14881Mpps,14万pps
千兆端口线速包转发率=1000Mbps/672=1.488095Mpps,约等于1.4881Mpps,148万pps
万兆端口线速包转发率=10000Mbps/672=14.88095Mpps,约等于14.881Mpps,1488万pps
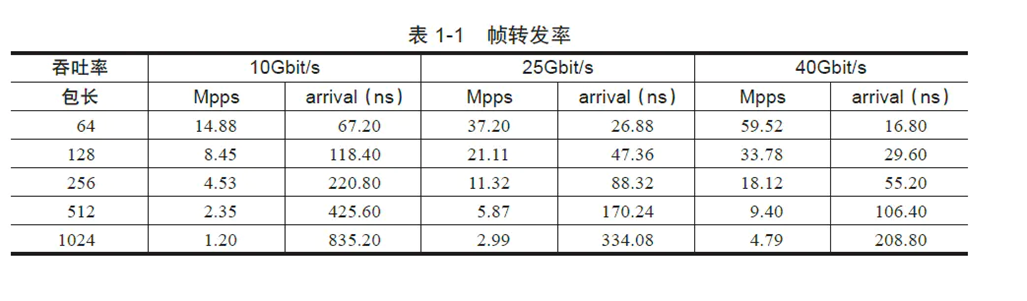
arrival为每个数据包之间的时间间隔。
rte:runtime environment 即运行环境。
eal: environment abstraction layer 即抽象环境层。
测试方法
pktgen是linux内核自带的发包工具,省却了用户态socket的参与,纯粹在内核构造skb送netdev的txqueue上,可以达到极高pps。pktgen只有UDP协议,适合做吞吐量测试。
基线测试
在性能测试中首先要做的是建立基线(Baseline),这样后续的调整才会有一个参考标准。值得注意的是,在测试基线的时候,一定要保证系统工作在正常的状态下。
测试结果


测试结论
64B小包,千兆网卡可以达到带宽,万兆网卡远远达不到带宽,前者受限于带宽,后者受限于cpu包中断处理
单个cpu ksoftirqd占用100%
结论分析
万兆网卡包收发瓶颈:是cpu而不是网卡带宽
1) 网络数据包来了之后通过中断模式进行通知,而cpu处理中断的能力是一定的,如果网络中有大量的小数据包,造成了网络的拥堵,cpu处理不及时。
2) 操作系统的协议栈是单核处理,没办法利用现在操作系统的多核。
网络数据包从网卡到内核空间,再到用户空间,进行了多次数据拷贝,性能比较差。
Linux + x86网络IO瓶颈
- 数据必须从内核态用户态之间切换拷贝带来大量CPU消耗,全局锁竞争。
- 收发包都有系统调用的开销。
- 内核工作在多核上,为可全局一致,即使采用Lock Free,也避免不了锁总线、内存屏障带来的性能损耗。
- 从网卡到业务进程,经过的路径太长,有些其实未必要的,例如netfilter框架,这些都带来一定的消耗,而且容易Cache Miss。一次Cache Miss,不管是TLB、数据Cache、指令Cache发生Miss,回内存读取大约65纳秒,NUMA体系下跨Node通讯大约40纳秒
网卡收包流程
多队列网卡硬件实现
2.6.21后网卡驱动实现
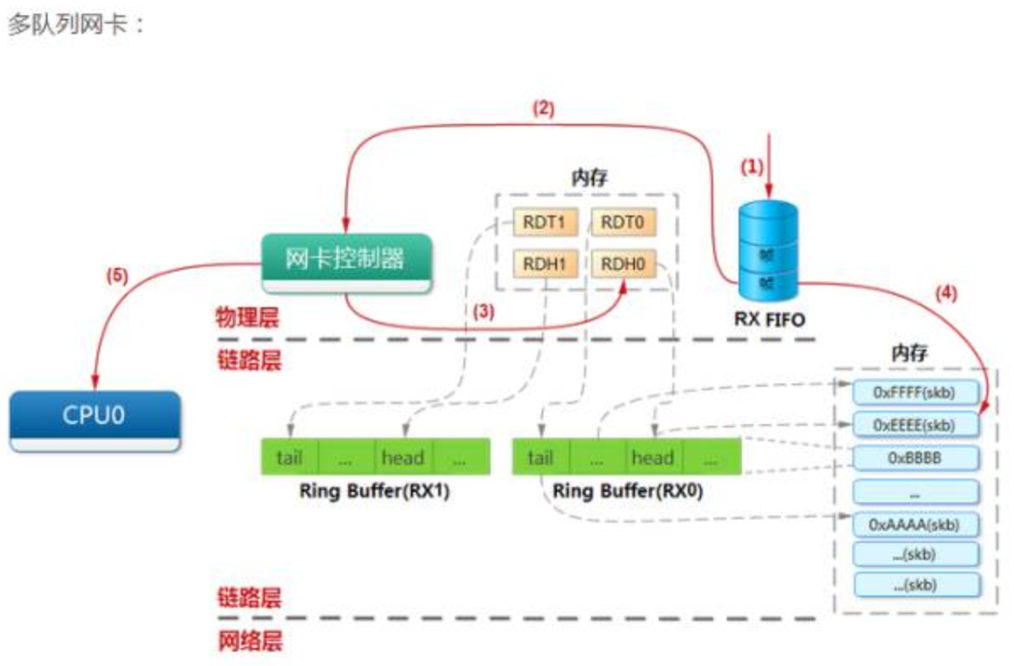
2.6.21开始支持多队列特性,当网卡驱动加载时,通过获取的网卡型号,得到网卡的硬件queue的数量,并结合CPU核的数量,最终通过Sum=Min(网卡queue,CPU core)得出所要激活的网卡queue数量(Sum),并申请Sum个中断号,分配给激活的各个queue。
如图1,当某个queue收到报文时,触发相应的中断,收到中断的核,将该任务加入到协议栈负责收包的该核的NET_RX_SOFTIRQ队列中(NET_RX_SOFTIRQ在每个核上都有一个实例),在NET_RX_SOFTIRQ中,调用NAPI的收包接口,将报文收到CPU中如图2的有多个netdev_queue的net_device数据结构中。
这样,CPU的各个核可以并发的收包,就不会应为一个核不能满足需求,导致网络IO性能下降。
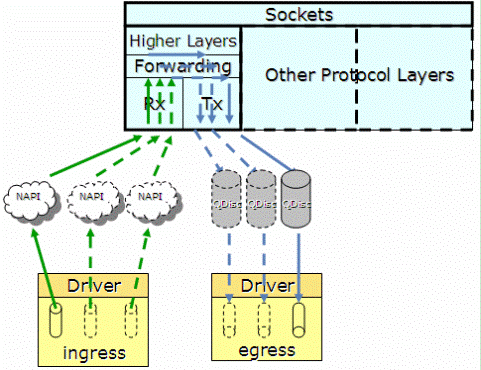
2.6.21之后内核协议栈
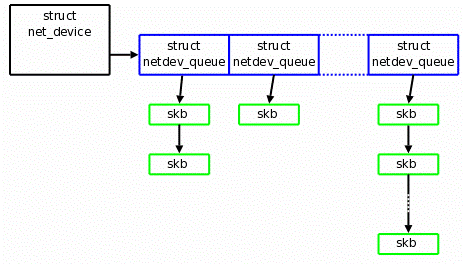
2.6.21之后net_device
中断绑定
cat /proc/interrupts|grep enp134s0f1-TxRx
当CPU可以平行收包时,就会出现不同的核收取了同一个queue的报文,这就会产生报文乱序的问题,解决方法是将一个queue的中断绑定到唯一的一个核上去,从而避免了乱序问题。同时如果网络流量大的时候,可以将软中断均匀的分散到各个核上,避免CPU成为瓶颈。
多队列网卡识别
# lspci -vvv -s 86:00.1
Ethernet controller的条目内容,如果有MSI-X && Enable+ && TabSize > 1,则该网卡是多队列网卡
Message Signaled Interrupts(MSI)是PCI规范的一个实现,可以突破CPU 256条interrupt的限制,使每个设备具有多个中断线变成可能,多队列网卡驱动给每个queue申请了MSI。MSI-X是MSI数组,Enable+指使能,TabSize是数组大小。
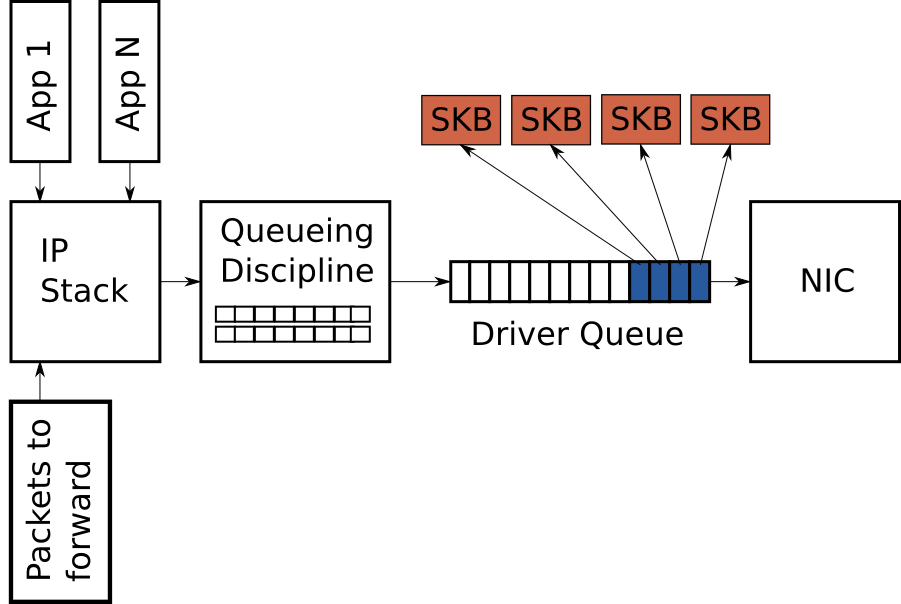
驱动程序队列(又名环形缓冲区)
驱动程序队列位于IP堆栈和网络接口控制器(NIC)之间。此队列通常实现为先进先出(FIFO) 环形缓冲区 –只需将其视为固定大小的缓冲区即可。驱动程序队列不包含数据包数据。相反,它由指向其他数据结构的描述符组成,这些数据结构称为套接字内核缓冲区(SKB) ,用于保存分组数据并在整个内核中使用。
网卡好文
https://www.cnblogs.com/yangykaifa/p/7398833.html
https://cloud.tencent.com/developer/article/1030881
https://www.coverfire.com/articles/queueing-in-the-linux-network-stack/
https://tech.meituan.com/2018/03/16/redis-high-concurrency-optimization.html
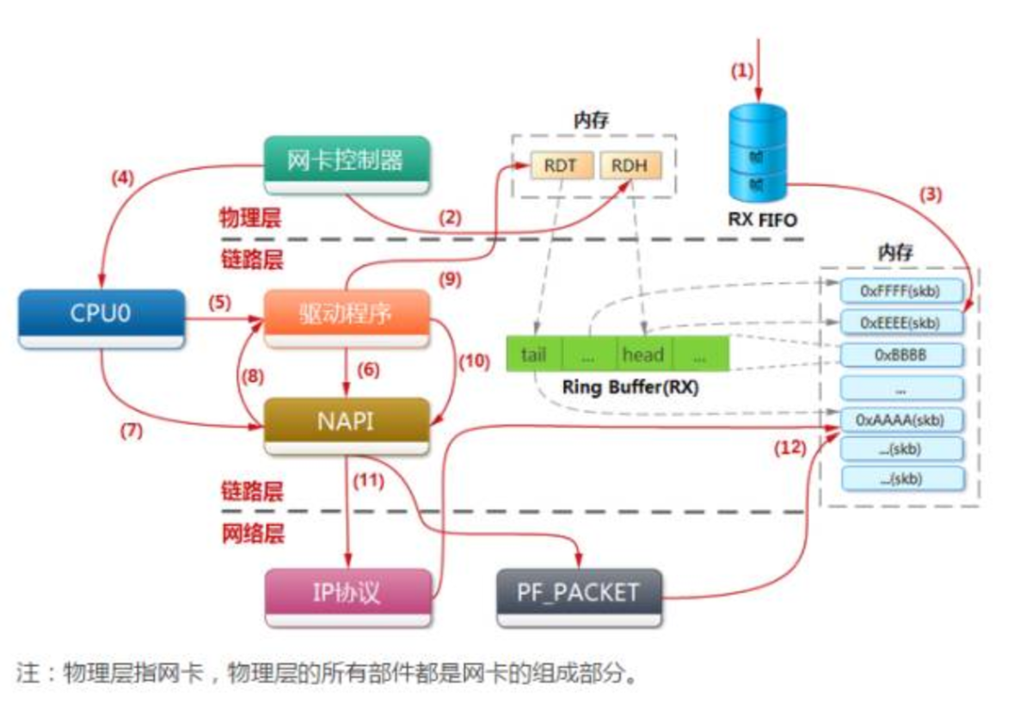
网卡收包从整体上是网线中的高低电平转换到网卡FIFO存储再拷贝到系统主内存(DDR3)的过程,其中涉及到网卡控制器,CPU,DMA,驱动程序,在OSI模型中属于物理层和链路层,如下图所示。
关键数据结构
在内核中网络数据流涉及到的代码比较复杂,见图1(原图在附件中),其中有3个数据结构在网卡收包的流程中是最主要的角色,它们是:sk_buff,softnet_data,net_device。
sk_buff
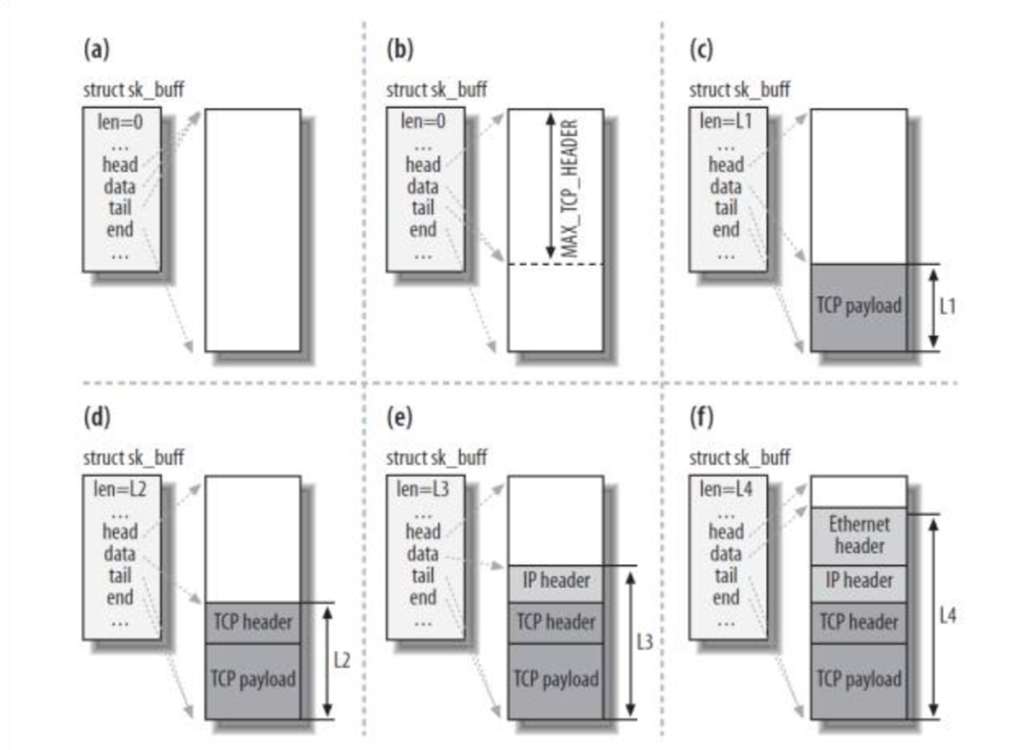
sk_buff结构是Linux网络模块中最重要的数据结构之一。sk_buff可以在不同的网络协议层之间传递,为了适配不同的协议,里面的大多数成员都是指针,还有一些union,其中data指针和len会在不同的协议层中发生改变,在收包流程中,即数据向上层传递时,下层的首部就不再需要了。图2即演示了数据包发送时指针和len的变化情况。(linux源码不同的版本有些差别,下面的截图来自linux 2.6.20)。
softnet_data
softnet_data 结构内的字段就是 NIC 和网络层之间处理队列,这个结构是全局的,每个cpu一个,它从 NIC中断和 POLL 方法之间传递数据信息。图3说明了softnet_data中的变量的作用。
net_device
net_device中poll方法即在NAPI回调的收包函数。
net_device代表的是一种网络设备,既可以是物理网卡,也可以是虚拟网卡。在sk_buff中有一个net_device * dev变量,这个变量会随着sk_buff的流向而改变。在网络设备驱动初始化时,会分配接收sk_buff缓存队列,这个dev指针会指向收到数据包的网络设备。当原始网络设备接收到报文后,会根据某种算法选择某个合适的虚拟网络设备,并将dev指针修改为指向这个虚拟设备的net_device结构。
3.网络收包原理
本节主要引用网络上的文章,在关键的地方加了一些备注,腾讯公司内部主要使用Intel 82576网卡和Intel igb驱动,和下面的网卡和驱动不一样,实际上原理是一样的,只是一些函数命名和处理的细节不一样,并不影响理解。
网络驱动收包大致有3种情况:
no NAPI:mac每收到一个以太网包,都会产生一个接收中断给cpu,即完全靠中断方式来收包
缺点是当网络流量很大时,cpu大部分时间都耗在了处理mac的中断。
netpoll:在网络和I/O子系统尚不能完整可用时,模拟了来自指定设备的中断,即轮询收包。
缺点是实时性差
NAPI:采用中断 + 轮询的方式:mac收到一个包来后会产生接收中断,但是马上关闭。
直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断
通过sysctl来修改 net.core.netdev_max_backlog
或者通过proc修改 /proc/sys/net/core/netdev_max_backlog
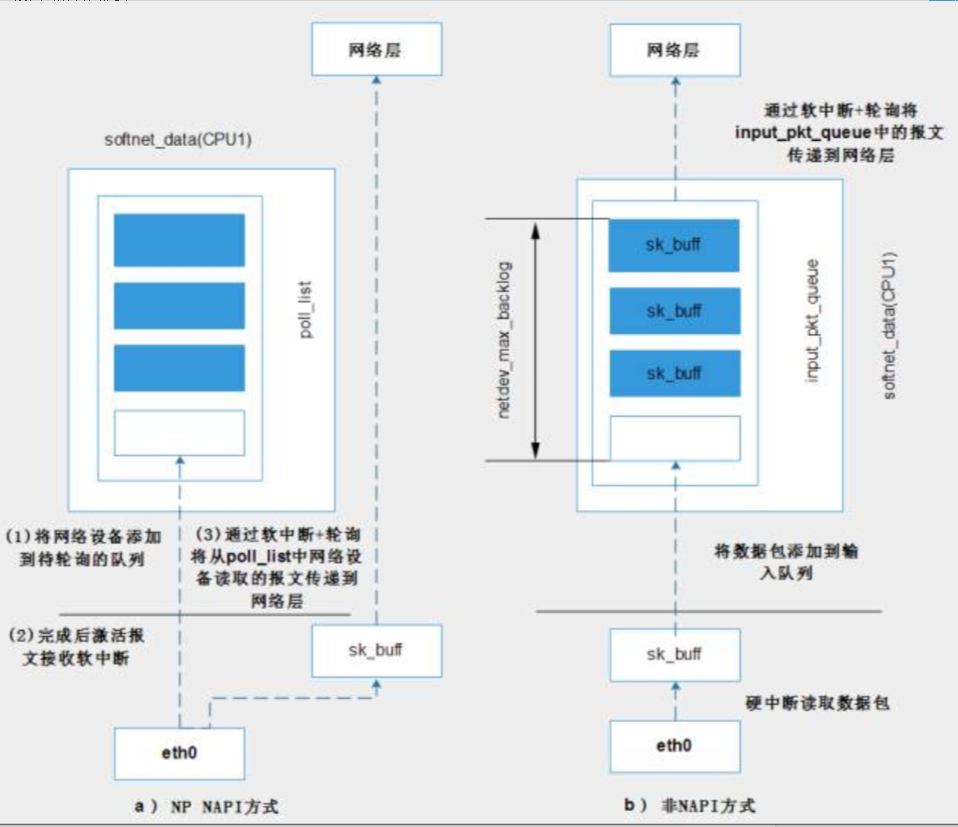
softnet_data与接口层
和网络层之间的关系
下面只写内核配置成使用NAPI的情况,只写TSEC驱动。内核版本 linux 2.6.24。
NAPI相关数据结构
解决方案
DPDK

PMD
PMD, Poll Mode Driver 即轮询驱动模式 ,DPDK用这种轮询的模式替换中断模式
RSS
RSS(Receive Side Scaling)是一种能够在多处理器系统下使接收报文在多个CPU之间高效分发的网卡驱动技术。
网卡对接收到的报文进行解析,获取IP地址、协议和端口五元组信息,网卡通过配置的HASH函数根据五元组信息计算出HASH值,取HASH值的低几位(这个具体网卡可能不同)作为RETA(redirection table)的索引,根据RETA中存储的值分发到对应的CPU,运行在不同CPU的应用程序就从不同的接收队列接收报文,这样就达到了报文分发的效果。
当RSS功能开启后,报文对应的rte_pktmbuf中就会存有RSS计算的hash值,可以通过pktmbuf.hash.rss来访问。 这个值可以直接用在后续报文处理过程中而不需要重新计算hash值,如快速转发,标识报文流等。
Hugepages大页内存
操作系统中,内存分配是按照页为单位分配的,页面的大小一般为4kB,如果页面大小固定内存越大,对应的页项越多,通过多级内存访问越慢,TLB方式访问内存更快,
但是TLB存储的页项不多,所以需要减少页面的个数,那么就通过增加页面大小的办法,增大内存页大小到2MB或1GB等。
DPDK主要分为2M和1G两种页面,具体支持要靠CPU,可以从cpu的flags里面看出来,举个例子:
如果flags里面有pse标识,标识支持2M的大内存页面;
如果有pdge1gb 标识,说明支持1G的大内存页。
cat /proc/meminfo|grep -i page
NUMA
NUMA(Non-Uniform Memory Architecture 非一致性内存架构)系统。
特点是每个处理器都有本地内存、访问本地的内存块,访问其他处理器对应的内存需要通过总线,慢。
NUMA的几个概念(Node,socket,core,thread)
socket就是主板上的CPU插槽; (物理cpu)
Core就是socket里独立的一组程序执行的硬件单元,比如寄存器,计算单元等; (逻辑cpu)
Thread:就是超线程hyperthread的概念,逻辑的执行单元,独立的执行上下文,但是共享core内的寄存器和计算单元。(超线程)
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题,具体参见下图来理解(图中的OS CPU可以理解thread,那么core就没有在图中画出),从图中可以看出每个Socket里有两个node,共有4个socket,每个socket 2个node,每个node中有8个thread,总共4(Socket)× 2(Node)× 8 (4core × 2 Thread) = 64个thread。
每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量,因为Node内有自己内部总线,所以增加CPU数量可以通过增加Node的数目来实现,如果单纯的增加CPU的数量,会对总线造成很大的压力,所以UMA结构不可能支持很多的核
由于每个node内部有自己的CPU总线和内存,所以如果一个虚拟机的vCPU跨不同的Node的话,就会导致一个node中的CPU去访问另外一个node中的内存的情况,这就导致内存访问延迟的增加。在有些特殊场景下,比如NFV环境中,对性能有比较高的要求,就非常需要同一个虚拟机的vCPU尽量被分配到同一个Node中的pCPU上,所以在OpenStack的Kilo版本中增加了基于NUMA感知的虚拟机调度的特性
查看机器的NUMA拓扑结构lscpu
VFIO
VFIO是一个可以安全的吧设备IO、中断、DMA等暴露到用户空间(usespace),从而在用户空间完成设备驱动的框架。用户空间直接访问设备,虚拟设备的分配可以获得更高的IO性能。
参考(https://blog.csdn.net/wentyoon/article/details/60144824)
重要模块划分
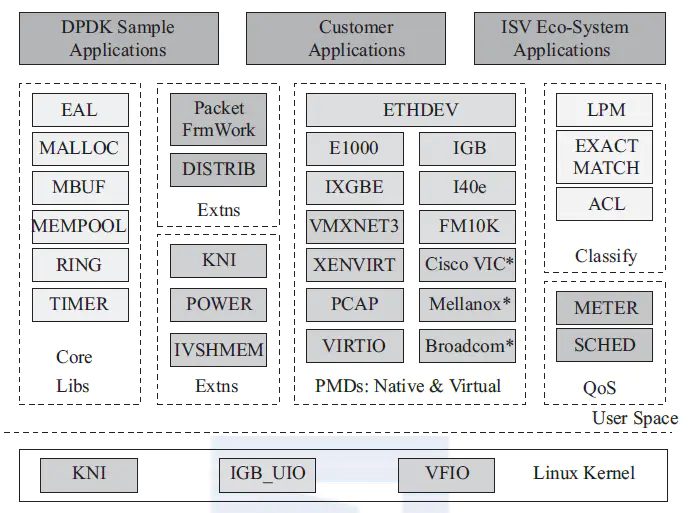
dpdk 为 Intel 处理器架构下用户空间高效的数据包处理提供了库函数和驱动的支持,它不同于 Linux 系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。
也就是 dpdk 绕过了 Linux 内核协议栈对数据包的处理过程,在用户空间实现了一套数据平面来进行数据包的收发与处理。在内核看来,dpdk 就是一个普通的用户态进程,它的编译、连接和加载方式和普通程序没有什么两样。
dpdk 的突破
相对传统的基于内核的网络数据处理,dpdk 对从内核层到用户层的网络数据流程进行了重大突破,我们先看看传统的数据流程和 dpdk 中的网络流程有什么不同。
传统 Linux 内核网络数据流程:
Copy
硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层
用户层收包-->网络层--->逻辑层--->业务层
dpdk 网络数据流程:
Copy
硬件中断--->放弃中断流程
用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
其他基础
单个cpu ksoftirqd占用100%
ksoftirqd是一个cpu内核线程,当机器在软中断负载很重时运行。计算机通过IRQ (中断请求)与连接到它的设备通信,当设备中断时,操作系统会暂停它正在做的事情,并开始处理中断。当高速网卡在短时间内接收大量数据包时,由于到达操作系统(因为他们到达的速度太快了)时无法处理IRQ,所以,操作系统将它们排队,让一个名为ksoftirqd的特殊内部进程在后台处理。这表明机器在中断负载很重。
内核中实现的方案不会立即处理处理重新触发的软中断。而作为改进,当大量软中断出现的时候,内核会唤醒一组内核线程来处理这些负载。这些线程在最低的优先级上运行(nice值是19),这能避免它们跟其他重要的任务抢夺资源。但它们最终肯定会被执行,所以这个折中方案能够保证在软中断负担很重的时候用户程序不会因为得不到处理时间处于饥饿状态。相应的,也能保证”过量“的软中断终究会得到处理。
每个处理器都有一个这样的线程。所有线程的名字都叫做ksoftirq/n,区别在于n,它对应的是处理器的编号。在一个双CPU的机器上就有两个这样的线程,分别叫做ksoftirqd/0和ksoftirqd/1。为了保证只要有空闲的处理器,它们就会处理软中断,所以给每个处理器都分配一个这样的线程。一旦该线程被初始化,它就会执行类似下面这样的死循环:
在<Softirq.c(kernel)>中
static int ksoftirqd(void * __bind_cpu)
只要有待处理的软中断(由softirq_pending()函数负责发现),ksoftirq就会调用do_softirq去处理它们。通过重复执行这样的操作,重新触发的软中断也会被执行。如果有必要,每次迭代后都会调用schedule()以便让更重要的进程得到处理机会。当所有需要执行的操作都完成以后,该内核线程将自己设置为TASK_INTERRUPTIBLE状态,唤起调度程序选择其他可执行进程投入运行。
只要do_softirq()函数发现已经执行过的内核线程重新触发了它自己,软中断内核线程就会被唤醒。
1、软中断
UN1X系统提供软中断机制作为进程通信的一种手段。软中断是通过发送规定的信号到指定进程,对方进程定时地查询有无外来信号,若有则按约定进行处理,处理完毕,返回断点继续执行原来的指令。可见,软中断是对硬中断的一种模拟。软中断存在较大的时延,不象硬中断能获得及时响应。例如,对方进程若处在阻塞队列,那么只有等到该进程执行时才能查询软中断信号。显然,从软中断信号发出到对方响应,时间可能拖得很长。此外,软中断处理程序运行在用户态,硬中断处理程序则运行在核心态。
各种UNIX版本设置的软中断信号一般不超过32种,其中部分信号已规定了它们的意义,另一部分留给用户自己定义。信号由键盘产生或由进程中的错误(例如不合理的存储访问)或由许多异步事件(例如时钟或来自C-Shell的作业控制)产生。
1)主要数据结构
软中断通信涉及进程的proc和user结构,有关部分介绍如下:
(1)p_clktim
它是报警时钟时间计数器,由系统调用alarm来设置它,时间一到就发送14号信号。
(2)p_sigign
它是忽略信号标记,共32位,每位对应一个信号。当进程需要忽略某些信号时,就把p_sigign中与这些信号对应的位置上1。
(3)p_sig
它是本进程接收信号的地方,共32位,正好对应32种不同的信号(因为信号只有27种,所以有5位未用)。第0位对应信号 1,第1位对应信号2,…,当本进程收到一个信号时,就在p_sig的对应位上置1。
(4)u_signal[NSIG]
它是一个有32个元素的一维数组,每个元素占32位,正好存放一个地址值。此地址为软中断处理程序的入口。当u_signal[i](i =1 , 2 , ... , 32)的值为非零偶数时,表明它是信号软中断处理程序入口地址,本进程按该处理程序来响应软中断;当u_signal[i]的值为0时,则终止进程本身;当u_signal[i]的值为非零奇数时,该软中断不起作用,本进程忽略它,不予处理。
2)信号发送
供用户进程发送软中断信号的系统调用是kill(pid, sig),其中pid为对方进程的标识号,sig为信号名称。如果pid为正整数,则把sig发给pid 号进程;如果pid 为0,则把sig发给同一进程组内的所有进程;如果pid 为-1,则把sig发送给自己或发送给除进程0和进程1之外的每个进程(用户是超级用户时)。具体发送工作由程序_psignal(&proc, sig)和_signal(p_pgrp, sig)完成。
_psignal(&proc, sig)中的参数&proc是对方进程的proc首址,sig为信号名。当对方进程未忽略sig时,就在对方进程的p_sig中相应的位上设置sig 。为尽快处理软中断信号,当对方进程处于睡眠态SSLEEP且它的优先数p_pri大于25时,则唤醒它,并把它排入就绪队列中。
_signal(p_pgrp, sig)中的第1参数p_pgrp为同组进程的组标识号,sig为信号名。该程序把信号发给同组其他进程,其实现比较简单:查找所有proc数组,凡其中proc结构中p_pgrp与第1参数相同者,就调用_psignal程序将sig发送给它。
3)信号接收与处理
UN1X系统V有一条系统调用signal(sig, func)用于软中断信号的接收与处理。正在执行的进程遇到时钟中断或核心态转至用户态或进入睡眠态之前或它退出低优先级睡眠之时,总要执行signal(sig, func)。
signal(sig, func)中的第1参数sig为信号名,第2参数func为对该信号的处理方式。当func为 1时,忽略该信号;当func为0 时,终止本进程;当func非奇数,非零的正整数时,按u_signal[sig]中的入口地址转软中断处理程序。软中断处理程序必须预先设计好。
当进程处于核心态时,即使收到软中断信号也不予理睬,只有当它返回用户态后,才处理收到的软中断信号。对于3号和12号软中断,则在调用_exit自我终止(因func=0)之前,还需要调用_core程序,将进程的数据段转贮到文件core中,转贮成功时置成功标记,该标记连同信号一起作为参数提供给_exit程序,由该程序负责返回给接受进程。
4)27种软中断信号
27种软中断信号的注释部分即为它的功能说明
#define SIGHUP 1 /* hangup */
#define SIGINT 2 /* interrupt */
#define SIGQUIT 3 /* quit */
#define SIGILL 4 /* illegal instruction (not reset when caught ) */
#define SIGTRAP 5 /* trace trap (not reset when caught ) */
#define SIGIOT 6 /* IOT instruction */
#define SIGEMT 7 /* EMT instr uction */
#define SIGFPE 8 /* floating point exception */
#define SIGKILL 9 /* kill (cannot be caught or ignored) */
#define SIGBUS 10 /* bus error */
#define SIGSEGV 11 /* segmentation violation */
#define SIGSYS 12 /* bad argument to system call */
#define SIGPIPE 13 /* write on a pipe with no one to read it */
#define SIGALAM 14 /* alarm clock */
#define SIGTERM 15 /* software termination signal from kill */
#define SIGSTOP 17 /* sendoble stop signal not from tty */
#define SIGTSTP 18 /* stop signal from tty */
#define SIGCONT 19 /* continue a stopped process */
#define SIGCHLD 20 /* to parent on child stop or exit */
#define SIGTTIN 21 /* to readers pgrp upon background tty read */
#define SIGTTOOU 22 /* like TTIN for output it (tp→t-local &LTOSTOP) */
#define SIGTINT 23 /* to pgrp on every input character if LINTRUP */
#define SIGXCPU 24 /* exceeded CPU time limit */
#define SIGXFSZ 25 /* exceeded file size limit */
#define SIGSTAT 26 /* status update requsted */
#define SIGMOUS 27 /* mouse interrupt */
#define NSIG 32
上述信号中,中断信号SIGNT(信号2)通常是从终端键盘上打入^c字符所产生的,该信号常用于停止一条未完成的命令。退出信号SIGQUIT通常由打入^字符所产生,该信号还要使得有关的进程把它当前的存储器映象写入当前目录下的称之为core 的文件中, 以便于诊断程序使用。信号SIGSTOP和SIGCONT用于C-Shell的作业控制中停止和重新启动某个进程;信号SIGILL是由非法指令所产生的,SIGSEGV是由访问的存储器超出了进程的合法虚拟存储器空间所产生的。
在下列地方会执行软中断:
1. 从一个硬件中断代码中返回
2. 在ksoftirqd内核线程中
3. 在显示检查和执行待处理的软中断代码中,如网络子系统.
cat /proc/interrupts
我们测试的系统,总的来说可分为二类:
- IO Bound,这类系统会大量消耗内存和底层的存储系统,它并不消耗过多的CPU和网络资源(除非系统是网络的)。IO bound系统消耗CPU资源用来接受IO请求,然后会进入休眠状态。数据库通常被认为是IO bound系统。
- CPU Bound,这类系统需要消耗大量的CPU资源。他们往往进行大量的数学计算。高吞吐量的Web server,Mail Server通常被认为是CPU Bound系统。
系统负载过重时往往会引起其它子系统的问题,比如:
->大量的读入内存的IO请求(page-in IO)会用完内存队列;
->大量的网络流量会造成CPU的过载;
->CPU的高使用率可能正在处理空闲内存队列;
->大量的磁盘读写会消耗CPU和IO资源。
pps不是网络设备唯一重要的指标
对于路由,pps是最重要的参数之一,但是对于其他设备,例如防火墙,负载平衡,入侵防御系统,NAT转换设备和其他有状态系统,也必须考虑不同的指标。根据其性质,有状态设备会在每个连接上创建和管理唯一信息。例如,新的TCP连接可以通过TCP SYN数据包的到达来识别,并且设备维护的状态信息通常包括源IP地址,目标IP地址,源端口,目标端口和协议号(五元组)用于连接。一旦此状态连接信息被缓存,设备就可以自由执行其设计所针对的功能(例如,防火墙,负载平衡等)。
在这种情况下,可以描述几个不同的指标:
每秒连接数
每秒连接数(cps)是指设备可以为新连接建立状态参数的速率。如前所述,有状态设备必须在传输该设备的所有唯一IP流上创建和管理连接信息。通常,设备必须以不同于所有后续数据包的方式处理新连接的第一个数据包,以便设备可以为新连接建立状态参数。因为此过程是专门的,所以它通常发生在设备的软件过程中,这与常规的基于硬件的转发过程相反。设备可以为新连接建立状态的速率与诸如处理器(CPU)速度,内存速度,体系结构,TCP / IP堆栈效率等因素有关。就数据包处理性能而言,建立状态参数时,设备可以处理数据包的速率通常是一旦建立状态参数,同一设备就可以在硬件中转发数据包的速率的一小部分。例如,列出了用于Cisco Catalyst 6500系列交换机和Cisco 7600系列路由器的Cisco应用控制引擎(ACE),每个模块可提供16 Gb / s和6.5 Mp / s的吞吐量。思科ACE还被列为每秒支持325,000个新连接(c / s)。每个模块的吞吐量为5 Mp / s。思科ACE还被列为每秒支持325,000个新连接(c / s)。每个模块的吞吐量为5 Mp / s。思科ACE还被列为每秒支持325,000个新连接(c / s)。
最大并发连接
最大并发连接数(mcc)是指设备可以同时维持状态的会话(连接)总数。此值主要与专用于此任务的内存量有关。但是,即使内存价格便宜,当c / s速率较低时,添加内存以支持更多的并发连接也没有多大意义。例如,如果某个设备具有足够的内存来处理一百万个并发连接,但该设备的最大连接建立速率为10 c / s,则要完全利用所有此状态将花费超过100,000秒(或28个小时)。因此,具有低c / s速率的设备通常也具有较低的mcc值。继续以Cisco ACE为例,Cisco ACE支持四百万个并发连接,这与其新的325的连接速率兼容,000 c / s。以最大c / s速率,可以在12秒内建立最大并发连接数。(其他信息,例如单个连接的寿命,在设计需要状态的系统时非常重要。)
每秒交易
每秒事务数(t / s)是指每秒可以执行的特定类型的完整动作的数量。t / s度量不仅涉及单个数据包的处理,甚至还涉及新连接的建立。它指的是完成特定动作的整个周期。在数据库设计中,t / s是一个常用指标,它表示每秒执行的数据库事务数。在联网中,某些设备使用此度量来描述某些复杂过程对数据包的应用,以构成完整的会话。例如,Cisco ACE XML网关通过处理XML消息和强制执行XML模式来帮助确保XML应用程序和Web服务的部署,被列为行业领先的性能,超过30,000 t / s。
这些度量中的每一个都可能与某种类型的网络设备有关。但是,在适当时,这些指标对于正确评估网络设备性能和正确设计可以支持所需服务的网络体系结构至关重要。
例如,假设一个新的防火墙服务被设计为使用1Gbps以太网接口,并且为该服务设计的正常流量配置文件每秒用于5,000个合法客户流量的新连接。如果这些标准是用于确定防火墙服务的大小和规模的唯一度量标准,则最终设计可能会得出结论,一种特定类型或大小的防火墙可以处理负载。但是,先前的数学示例表明,可以预期该设备可以处理高达1.4 Mp / s的入口流量(假设有小数据包)。考虑到所有这些流量都可能是新的连接尝试,例如在闪存人群或分布式拒绝服务(DDoS)事件中,很明显,最终设计应该选择一个合适的设备,并且还要考虑该指标。或者,也可以将此度量转换为用于定义此服务的其他设计选择。可能考虑的选项可能包括增加已部署的防火墙服务的容量,或部署其他上游机制,例如速率限制或 Clean-Pipes 服务,以保护防火墙部署。尽管在某些情况下防火墙可能需要其自身的保护的说法似乎很奇怪,但在高带宽环境中经常需要使用防火墙。实际上,必须评估所有有状态设备的意外负载和状况。
性能测试工具
mpstat
是 Multiprocessor Statistics,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。mpstat -P ALL 1
top 后1更清晰
vmstat
是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。该命令通过使用knlist子程序和/dev/kmen伪设备驱动器访问这些数据,输出信息直接打印在屏幕。
sar
System Activity Reporter(系统活跃情况报告)的缩写。顾名思义,sar工具将对系统当前的状态进行采样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统采样,获得大量的采样数据;采样数据和分析的结果都可以存入文件,所需的负载很小。sar的数据是一段时间保存的内容,因此可以察看过去的信息。 lastcomm可以现在系统最近被执行的命令。这些可以用在系统审计中。sar可以在*BSD和Linux中找到,它给用户在系统审计中更多的选项来收集信息。
MEMORY
首先说说虚拟内存和物理内存:
虚拟内存就是采用硬盘来对物理内存进行扩展,将暂时不用的内存页写到硬盘上而腾出更多的物理内存让有需要的进程来用。当这些内存页需要用的时候在从硬盘读回内存。这一切对于用户来说是透明的。通常在Linux系统说,虚拟内存就是swap分区。在X86系统上虚拟内存被分为大小为4K的页。
每一个进程启动时都会向系统申请虚拟内存(VSZ),内核同意或者拒就请求。当程序真正用到内存时,系统就它映射到物理内存。RSS表示程序所占的物理内存的大小。用ps命令我们可以看到进程占用的VSZ和RSS。
iostat –x
网络工具
网络是所有子系统中最难监控的了。首先是由于网络是抽象的,更重要的是许多影响网络的因素并不在我们的控制范围之内。这些因素包括,延迟、冲突、阻塞等等。
网络方向的性能分析既包括主机测的网络配置查看、监控,又包括网络链路上的包转发时延、吞吐量、带宽等指标分析。包括但不限于以下分析工具:
ip:网络接口统计信息
netsat:多种网络栈和接口统计信息
ifstat:接口网络流量监控工具
tcpdump:抓包工具
sar:统计信息历史
pathchar:确定网络路径特征
dtrace:TCP/IP 栈跟踪
iperf / netperf / netserver:网络性能测试工具
perf 性能分析神器
ping
ping 发送 ICMP echo 数据包来探测网络的连通性,除了能直观地看出网络的连通状况外,还能获得本次连接的往返时间(RTT 时间),丢包情况,以及访问的域名所对应的 IP 地址(使用 DNS 域名解析)
ifconfig
ifconfig 命令被用于配置和显示 Linux 内核中网络接口的统计信息。通过这些统计信息,我们也能够进行一定的网络性能调优。性能调优时可以重点关注 MTU(最大传输单元) 和 txqueuelen(发送队列长度),比如可以用下面的命令来对这两个参数进行微调:
ifconfig eth0 txqueuelen 2000
ifconfig eth0 mtu 1500
ip
ip 命令用来显示或设置 Linux 主机的网络接口、路由、网络设备、策略路由和隧道等信息,是 Linux 下功能强大的网络配置工具,旨在替代 ifconfig 命令,如下显示 IP 命令的强大之处,功能涵盖到 ifconfig、netstat、route 三个命令。
https://linoxide.com/linux-command/use-ip-command-linux/
netstat
netstat 可以查看整个 Linux 系统关于网络的情况,是一个集多钟网络工具于一身的组合工具。
常用的选项包括以下几个:
默认:列出连接的套接字
-a:列出所有套接字的信息
-s:各种网络协议栈统计信息
-i:网络接口信息
-r:列出路由表
-l:仅列出有在 Listen 的服务状态
-p:显示 PID 和进程名称
各参数组合使用实例如下:
netstat -at 列出所有 TCP 端口
netstat -au 列出所有 UDP 端口
netstat -lt 列出所有监听 TCP 端口的 socket
netstat -lu 列出所有监听 UDP 端口的 socket
netstat -lx 列出所有监听 UNIX 端口的 socket
netstat -ap | grep ssh 找出程序运行的端口
netstat -an | grep ':80' 找出运行在指定端口的进程
1)netstat 默认显示连接的套接字数据
整体上来看,输出结果包括两个部分:
Active Internet connections :有源 TCP 连接,其中 Recv-Q 和 Send-Q 指的是接收队列和发送队列,这些数字一般都是 0,如果不是,说明请求包和回包正在队列中堆积。
Active UNIX domain sockets:有源 UNIX 域套接口,其中 proto 显示连接使用的协议,RefCnt 表示连接到本套接口上的进程号,Types 是套接口的类型,State 是套接口当前的状态,Path 是连接到套接口的进程使用的路径名。
2)netstat -i 显示网络接口信息
接口信息包括网络接口名称(Iface)、MTU,以及一系列接收(RX-)和传输(TX-)的指标。其中 OK 表示传输成功的包,ERR 是错误包,DRP 是丢包,OVR 是超限包。
这些参数有助于我们对网络收包情况进行分析,从而判断瓶颈所在。
3)netstat -s 显示所有网络协议栈的信息
可以看到,这条命令能够显示每个协议详细的信息,这有助于我们针对协议栈进行更细粒度的分析。
4)netstat -r 显示路由表信息
这条命令能够看到主机路由表的一个情况。当然查路由我们也可以用 ip route 和 route 命令,这个命令显示的信息会更详细一些。
ifstat#
ifstat 主要用来监测主机网口的网络流量,常用的选项包括:
-a:监测主机所有网口
-i:指定要监测的网口
-t:在每行输出信息前加上时间戳
-b:以 Kbit/s 显示流量数据,而不是默认的 KB/s
-delay:采样间隔(单位是 s),即每隔 delay 的时间输出一次统计信息
-count:采样次数,即共输出 count 次统计信息
比如,通过以下命令统计主机所有网口某一段时间内的流量数据:
可以看出,分别统计了三个网口的流量数据,前面输出的时间戳,有助于我们统计一段时间内各网口总的输入、输出流量。
除了网络工具,cpu和内存也是网络瓶颈可能的上限,也需要监控
监控CPU调度程序运行队列
linux可以使用vmstat命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。该命令通过使用knlist子程序和/dev/kmen伪设备驱动器访问这些数据,输出信息直接打印在屏幕。vmstat反馈的与CPU相关的信息包括:
(1)多少任务在运行
(2)CPU使用的情况
(3)CPU收到多少中断
(4)发生多少上下文切换
监控锁竞争
使用 sysstat包中的pidstat命令来监控
监控网络I/O使用率
nicstat原本是Solaris平台下显示网卡流量的工具,Tim Cook将它移植到linux平台