一、概述
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
Prometheus+Grafana环境部署可以参考我这篇文章:【云原生】Prometheus+Grafana on K8s 环境部署
二、监控架构

-
通过
cadvisor采集容器、Pod相关的性能指标数据,并通过暴露的/metrics接口用prometheus抓取。 -
通过
node-exporter采集主机的性能指标数据,并通过暴露的/metrics接口用prometheus抓取。 -
通过
kube-state-metrics采集k8s资源对象的状态指标数据,并通过暴露的/metrics接口用prometheus抓取。 -
应用侧自己采集容器中进程主动暴露的指标数据(暴露指标的功能由应用自己实现,并添加平台侧约定的
annotation,平台侧负责根据annotation实现通过Prometheus的抓取)。 -
通过etcd、kubelet、kube-apiserver、kube-controller-manager、kube-scheduler自身暴露的/metrics获取节点上与k8s集群相关的一些特征指标数据。
三、给Grafana配置Prometheus数据源
有许多与 Grafana Alerting 兼容的数据源。每个数据源都由一个插件支持。您可以使用下面列出的内置数据源之一,使用外部数据源插件,或创建自己的数据源插件。以下就是与 Grafana Alerting 兼容并支持的数据源:
- AWS CloudWatch
- Azure Monitor
- Elasticsearch
- Google Cloud Monitoring
- Graphite
- InfluxDB
- Loki
- Microsoft SQL Server MSSQL
- MySQL
- Open TSDB
- PostgreSQL
Prometheus- Jaeger
- Zipkin
- Tempo
- Testdata
Grafana web地址:https://alertmanager.k8s.local/
账号:admin,密码通过下面命令获取0D0NfEWWFx9qsBiKR8PuFVxf6PPa9o8YGhZZaNXY
kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
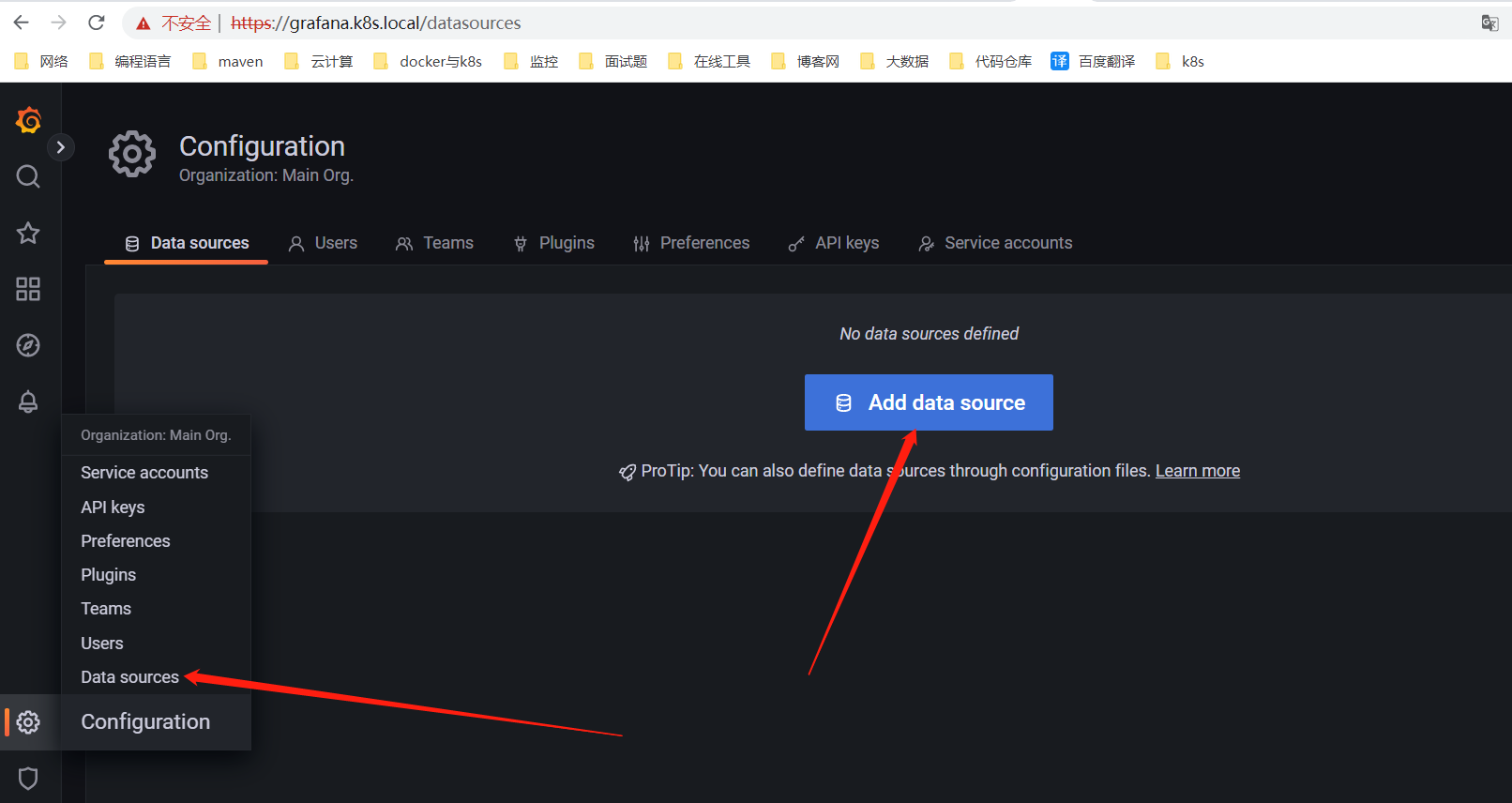


# 配置这个内网地址(推荐)
http://prometheus-server.prometheus:80
# 或者配置对外地址
https://prometheus.k8s.local
配置对外地址时,如果域名是通过hosts配置的,得需要在values.yaml文件配置这个hostAliases,IP对应宿主机的IP。就会将这个配置加载到pod里的/etc/hosts文件中。
...
hostAliases:
- ip: "192.168.182.110"
hostnames:
- "prometheus.k8s.local"
...
滚动更新
helm upgrade grafana -n grafana ./grafana

四、cAdvisor 介绍
cAdvisor是Google开源的容器资源监控和性能分析工具,它是专门为容器而生,在Kubernetes中,我们不需要单独去安装,cAdvisor作为kubelet内置的一部分程序可以直接使用,也就是我们可以直接使用cadvisor采集数据,可以采集到和容器运行相关的所有指标,数据路径为
/api/v1/nodes/[节点名称]/proxy/metrics/cadvisor。

- kubelet的节点使用
cAdvisor提供的metrics接口获取该节点所有容器相关的性能指标数据。 - cAdvisor 是一个开源容器资源使用收集器。它专为容器而构建,支持本地 Docker 容器。cAdisor 会自动发现给定节点中的所有容器,并收集CPU、内存、文件系统和网络使用情况统计信息,不过它仅会收集基本资源利用率。
- 仅当容器具有 X%CPU 利用率时,cAdvisor 才能告诉我们应用程序的实际性能。cAdvisor 本身并不提供任何长期存储或分析功能。
cadvisor中获取到的典型监控指标如下:
| 指标名称 | 类型 | 含义 |
|---|---|---|
| container_cpu_load_average_10s | gauge | 过去10秒容器CPU的平均负载 |
| container_cpu_usage_seconds_total | counter | 容器在每个CPU内核上的累积占用时间 (单位:秒) |
| container_cpu_system_seconds_total | counter | System CPU累积占用时间(单位:秒) |
| container_cpu_user_seconds_total | counter | User CPU累积占用时间(单位:秒) |
| container_fs_usage_bytes | gauge | 容器中文件系统的使用量(单位:字节) |
| container_fs_limit_bytes | gauge | 容器可以使用的文件系统总量(单位:字节) |
| container_fs_reads_bytes_total | counter | 容器累积读取数据的总量(单位:字节) |
| container_fs_writes_bytes_total | counter | 容器累积写入数据的总量(单位:字节) |
| container_memory_max_usage_bytes | gauge | 容器的最大内存使用量(单位:字节) |
| container_memory_usage_bytes | gauge | 容器当前的内存使用量(单位:字节) |
| container_spec_memory_limit_bytes | gauge | 容器的内存使用量限制 |
| machine_memory_bytes | gauge | 当前主机的内存总量 |
| container_network_receive_bytes_total | counter | 容器网络累积接收数据总量(单位:字节) |
| container_network_transmit_bytes_total | counter | 容器网络累积传输数据总量(单位:字节) |
cadvisor 常用容器监控指标:
- 查询容器内存使用量(单位:字节)
container_memory_usage_bytes{image!=""}
- 查询容器网络接收量(速率)(单位:字节/秒)
sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without (interface)
- 容器网络传输量 字节/秒
sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without (interface)
- 容器文件系统读取速率 字节/秒
sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without (device)
- 容器文件系统写入速率 字节/秒
sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without (device)
- 网络流量监控
##容器网络接收的字节数(1分钟内),根据名称查询 name=~".+"
sum(rate(container_network_receive_bytes_total{name=~".+"}[1m])) by (name)
##容器网络传输的字节数(1分钟内),根据名称查询 name=~".+"
sum(rate(container_network_transmit_bytes_total{name=~".+"}[1m])) by (name)
- 容器 CPU相关监控
### 容器CPU使用率
sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without (cpu)
###所用容器system cpu的累计使用时间(1min钟内)
sum(rate(container_cpu_system_seconds_total[1m]))
###每个容器system cpu的使用时间(1min钟内)
sum(irate(container_cpu_system_seconds_total{image!=""}[1m])) without (cpu)
#每个容器的cpu使用率
sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) * 100
#总容器的cpu使用率
sum(sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) * 100)
五、监控配置
1)监控k8s集群中的pod
kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有容器相关的性能指标数据。cAdvisor默认集成在k8s中,无需再安装了。
导入grafana模板,集群资源监控:3119
官方模块下载地址:https://grafana.com/grafana/dashboards/

上面截图第一个就是3119模板,当然也可以使用上面截图的其它模板,可以根据需要自己选择。将json下来导入到grafana中。
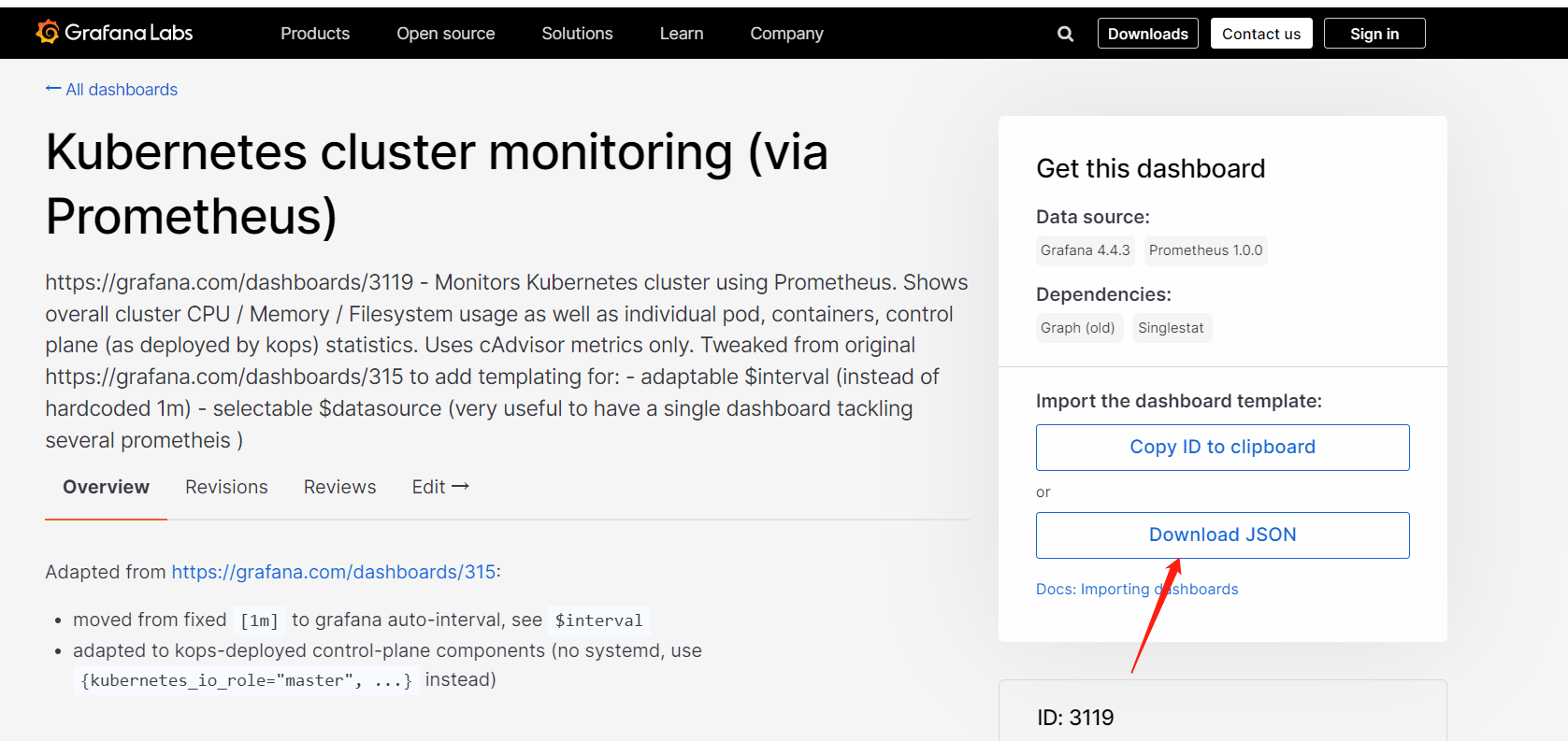
导入模板


2) 监控k8s集群中的node
使用文档:https://prometheus.io/docs/guides/node-exporter/
GitHub:https://github.com/prometheus/node_exporter
exporter列表:https://prometheus.io/docs/instrumenting/exporters/
所有node节点部署node_exporter
kubectl get pods -n prometheus -owide|grep node-exporter

查看prometheus是否收集到kubernetes-nodes

导入grafana模板,集群资源监控:13105,13824,8919
官方模块下载地址:https://grafana.com/grafana/dashboards/

3)监控k8s资源对象
kube-state-metrics是一个简单的服务,它监听Kubernetes API服务器并生成有关对象状态的指标。它不关注单个Kubernetes组件的运行状况,而是关注内部各种对象的运行状况,例如部署,节点和容器。
GitHub地址:https://github.com/kubernetes/kube-state-metrics
导入grafana模板,集群资源监控:16520

如果上面的模板不满足需求,也可以自定义。
六、自定义Dashboard
当然,在有些时候我们需要对我们的应用进行指标监控,这个时候需要我们自定义dashboard。这就需要我们对Grafana有更深入的了解,比如什么时候metrics,Grafana的查询语法等等。笔者尝试用最简单的方式和大家进行介绍。
1)Folder文件夹
dashboard必须属于某个文件夹,可以理解成分类,当dashboard多了之后方便管理,默认的folder是 general,我们可以根据实际情况进行分文件夹,比如 MySQL,K8s等待。

2)dashboard的组成
一个dashboard由
General、Annotations、Variables、Links、Versions、Permissions、JSON Model、Pannels等组成。


General基本信息,配置名称,数据源等基本信息Annotations查询条件,上方查询条件Variables变量,可以用于查询Links友情链接Versions每一次修改后的历史版本Permissions权限JSON Model,dashboard的最终代码用json来表达,我们上面导入id后其实加载的就是json代码Panel,图标组件,图表组件支持大部分常见的图表

七、Grafana Alerting
官方文档:https://grafana.com/docs/grafana/latest/alerting/
除了Prometheus的AlertManager可以发送报警,
Grafana Alerting同时也支持。Grafana Alerting可以无缝定义告警在数据中的位置,可视化的定义阈值,并可以通过钉钉、email等平台获取告警通知。最重要的是可直观的定义告警规则,不断的评估并发送通知。grafana只有在4.0以上版本才有,同时在Grafana 5.3及以上版本支持发送提醒,可以指定如何经常提醒应用使用的秒、分、或者小时。所以在企业里用AlertManager 告警反而少了。
下图概述了 Grafana 警报的工作原理图:

Alert rule——设置确定警报实例是否会触发的评估标准。警报规则由一个或多个查询和表达式、条件、评估频率以及满足条件的持续时间(可选)组成。Labels——将警报规则及其实例与通知策略和静默相匹配。它们还可用于按严重性对警报进行分组。Notification policy——设置警报的发送地点、时间和方式。每个通知策略指定一组标签匹配器来指示它们负责哪些警报。通知策略具有分配给它的由一个或多个通知者组成的联系点。Contact points——定义触发警报时如何通知您的联系人。我们支持多种 ChatOps 工具,以确保您的团队收到警报。

1)告警规则(Alert rules)
-
告警规则是一组评估标准,用于确定告警实例是否会触发。该规则由一个或多个查询和表达式、一个条件、评估频率以及满足条件的持续时间(可选)组成。
-
在查询和表达式选择要评估的数据集时,条件会设置告警必须达到或超过才能创建警报的阈值。
-
间隔指定评估警报规则的频率。持续时间在配置时表示必须满足条件的时间。告警规则还可以定义没有数据时的告警行为。
2)告警规则的注释和标签(Annotations and labels for alerting rules)
注释和标签是与源自警报规则、数据源响应以及警报规则评估结果的警报相关联的键值对。它们可以直接用于警报通知,也可以在模板和模板函数中使用,以动态创建通知联系人。
-
注释(Annotations )——注释是提供有关警报的附加元信息的键值对。您可以使用以下注释:description、summary、runbook_url、alertId、dashboardUid、 和panelId。例如,描述、摘要和 Runbook URL。这些显示在 UI 中的规则和警报详细信息中,并可用于联络点消息模板。
-
标签(labels )——标签是包含有关信息的键值对,用于唯一标识警报。在整个警报评估和通知过程中生成并添加警报的标签集。
3)告警规则的状态和运行状况
共有三个关键组件:告警规则状态、告警规则运行状况和告警实例状态。尽管相关,但每个组件都传达了微妙的不同信息。

1、告警规则状态(Alert rule state)
告警规则可以处于以下状态之一:
| 状态 | 描述 |
|---|---|
| Normal | 评估引擎返回的时间序列都不是处于Pending 或者 Firing状态。 |
| Pending | 评估引擎返回的至少一个时间序列是Pending。 |
| Firing | 评估引擎返回的至少一个时间序列是Firing。 |
2、告警规则运行状况(Alert rule health)
告警规则可以具有以下运行状况之一:
| 状态 | 描述 |
|---|---|
| Ok | 评估告警规则时没有错误。 |
| Error | 评估告警规则时没有错误。 |
| NoData | 在规则评估期间返回的至少一个时间序列中缺少数据。 |
3、告警实例状态(Alert instance state)
告警实例可以处于以下任一状态:
| 状态 | 描述 |
|---|---|
| Normal | 既未触发也未挂起的告警状态,一切正常。 |
| Pending | 已激活的告警状态少于配置的阈值持续时间。 |
| Alerting | 已激活超过配置的阈值持续时间的告警的状态。 |
| NoData | 在配置的时间窗口内未收到任何数据。 |
| Error | 尝试评估告警规则时发生的错误。 |
八、告警通道(Contact points/Notification channels)
使用告警通道来定义当警报触发时如何通知您的联系人。一个告警通道可以有一个或多个告警通道类型,例如
电子邮件、webhook、钉钉、企业微信等。触发警报时,会向为某个告警通道列出的所有告警通道类型发送通知。或者,使用消息模板自定义告警通道类型的通知消息。您可以配置 Grafana 管理的联系点以及外部Alertmanager数据源的联系点。这里不讲,关于对接外部的Alertmanager,请查看官方文档。
1)邮件告警通道(默认)
1、配置stmp服务(grafana.ini)
[smtp]
enabled = true
host = localhost:25
user =
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password =
cert_file =
key_file =
skip_verify = false
from_address = admin@grafana.localhost
from_name = Grafana
ehlo_identity =
startTLS_policy =
grafana on k8s 中配置values.yaml
smtp:
enabled: true
host: "smtp.qq.com:465"
user: "xxx@qq.com"
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password: "xxx"
skip_verify: true
from_address: "xxx@qq.com"
from_name: Grafana
cert_file: ""
key_file: ""
ehlo_identity: ""
startTLS_policy: ""
upgrade更新
helm upgrade grafana ./grafana -n grafana
2、grafana web配置

测试

3、测试验证
第一步:创建Folder

第二步:告警规则配置,在需要配置告警的图表上按e就进入编辑页面,在编辑页面配置告警规则


第三步:等待邮件告警

2)Webhook 告警通道
Webhook告警通道其实也是最常用的,一般就是对接内部的告警平台,通过公司内部的告警平台分发到其它告警通道发告警,例如:IM,电话,zabbix等等,其实Webhook就是告警转发器,一般需要自己写程序去实现,webhook的实现就由小伙伴自己根据业务场景去实现了,除了这两种,告警通道还有很多,一般用的多的可能就是邮件、webhook、钉钉、企业微信了。当然有什么疑问也欢迎给我留言哦。
Prometheus+Grafana 监控 k8s 资源实战操作就先到这里了,小伙伴有任何疑问欢迎给我留言,有空必回,后续会持续更新关于【云原生和大数据】相关的文章,请小伙伴耐心等待~