一、window 概念
窗口(window)是处理无限流的核心。窗口将流分割成有限大小的“桶”,我们可以在桶上应用计算。本文档重点介绍如何在Flink中执行窗口操作,以及程序员如何从其提供的功能中获得最大的好处。
一个有窗口的Flink程序的一般结构如下所示。第一个片段指的是键控流,而第二个片段指的是非键控流。可以看到,唯一的区别是keyBy(…)调用键流,而window(…)调用非键流的windowwall(…)。这也将作为页面其余部分的路标。
Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
一般真实的流都是无界的,怎样处理无界的数据?
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你 分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
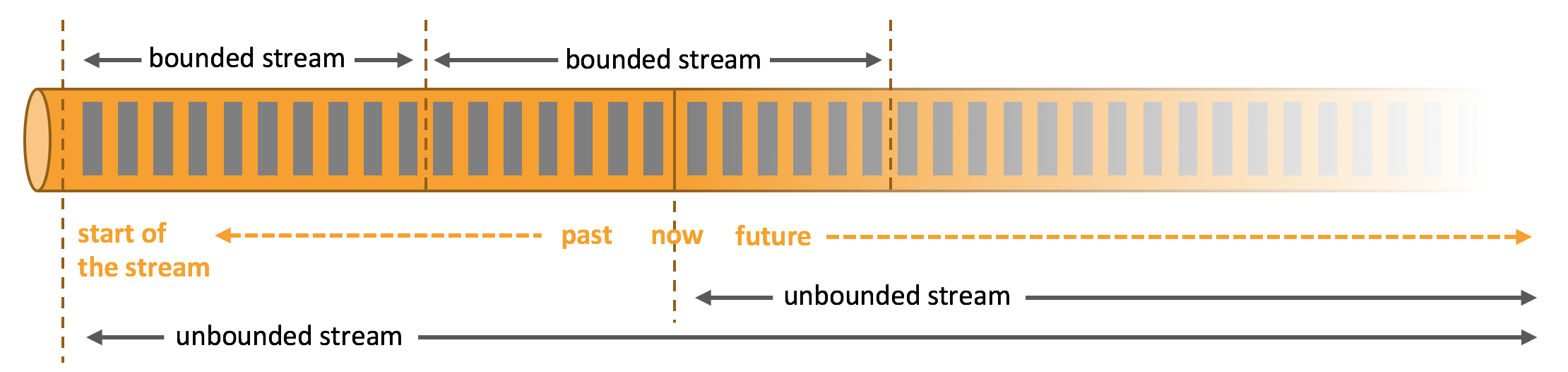
上面图片来源:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/learn-flink/overview/
- 可以把无限的数据流进行切分,得到有限的数据集进行处理 —— 也
就是得到有界流 - 窗口(window)就是将无限流切割为有限流的一种方式,它会将流
数据分发到有限大小的桶(bucket)中进行分析
二、 时间窗口(Time Window)
1)滚动窗口(Tumbling Windows)
翻转窗口赋值器将每个元素赋值给一个指定窗口大小的窗口。滚动的窗口有固定的尺寸,而且不重叠。例如,如果您指定一个大小为5分钟的滚动窗口,则当前窗口将被评估,并每5分钟启动一个新窗口,如下图所示:
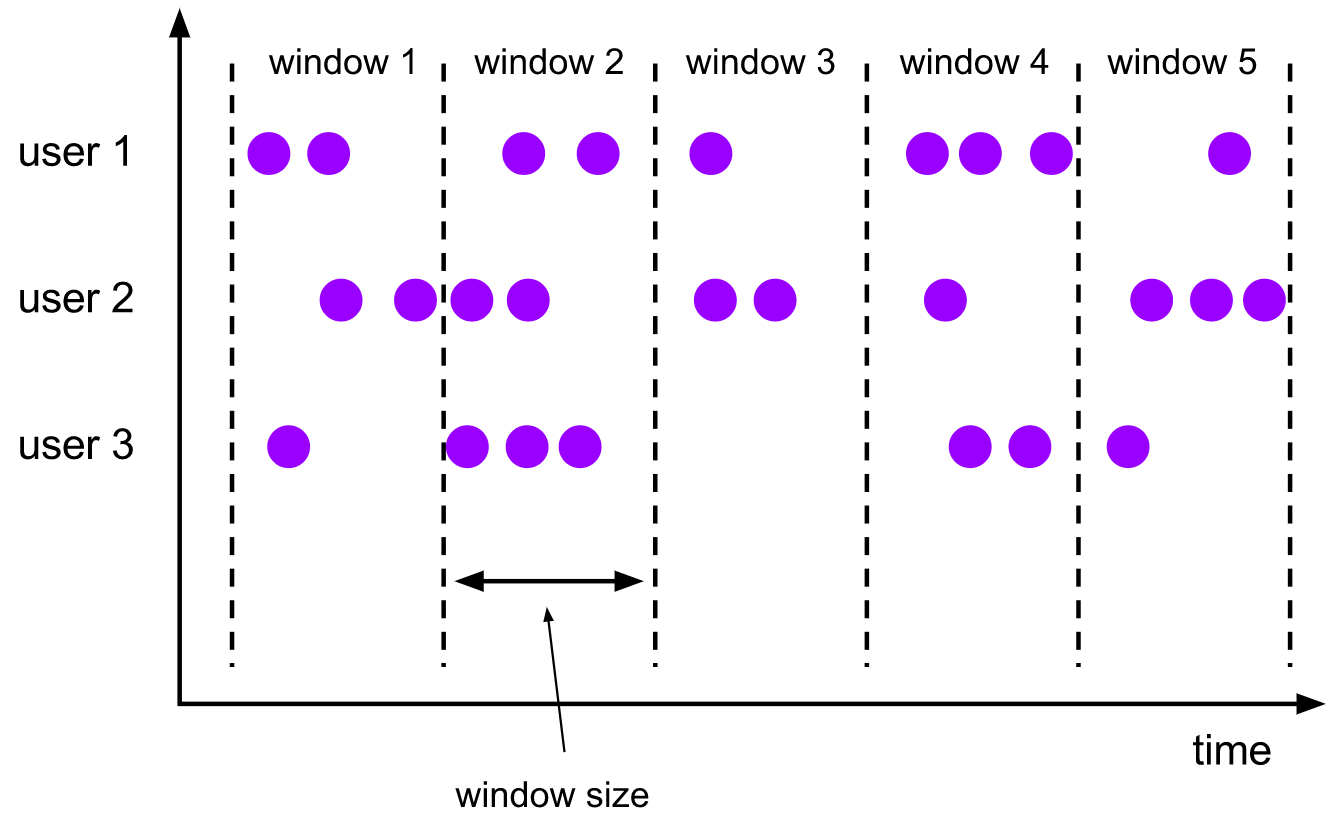
【特点】
- 将数据依据固定的窗口长度对数据进行切分
- 时间对齐,窗口长度固定,没有重叠
【示例代码】
TumblingEventTimeWindows:滚动事件时间窗口
TumblingProcessingTimeWindows:滚动处理时间窗口
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
2)滑动窗口(Sliding Windows)
滑动窗口赋值器将元素赋值给固定长度的窗口。类似于滚动窗口赋值器,窗口的大小由窗口大小参数配置。另外一个窗口滑动参数控制滑动窗口启动的频率。因此,如果滑动窗口小于窗口大小,则滑动窗口可以重叠。在这种情况下,元素被分配给多个窗口。
例如,您可以将大小为10分钟的窗口滑动5分钟。这样,每隔5分钟就会出现一个窗口,其中包含在最后10分钟内到达的事件,如下图所示:
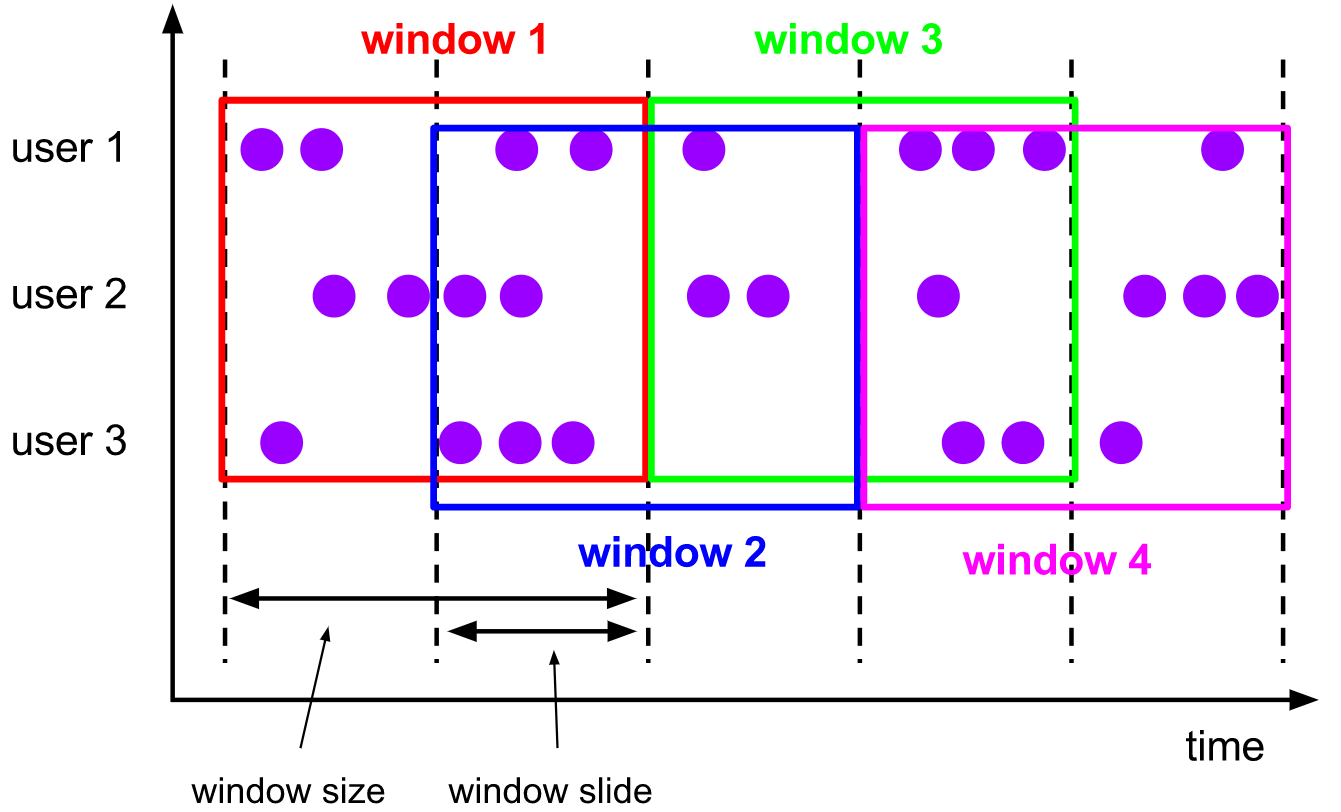
【特点】
- 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口
长度和滑动间隔组成 - 窗口长度固定,可以有重叠
【示例代码】
SlidingEventTimeWindows:滑动事件时间窗口
SlidingProcessingTimeWindows:滑动处理时间窗口
val input: DataStream[T] = ...
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
3)会话窗口(Session Windows)
会话窗口分配器根据活动的会话对元素进行分组。与滑动窗口不同,会话窗口没有重叠,也没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到元素时,即当一个不活动间隙发生时,会话窗口将关闭。会话窗口分配器可以配置一个静态会话间隙,也可以配置一个会话间隙提取器函数,该函数定义了不活动的时间长度。当这段时间到期时,当前会话关闭,随后的元素被分配到一个新的会话窗口。
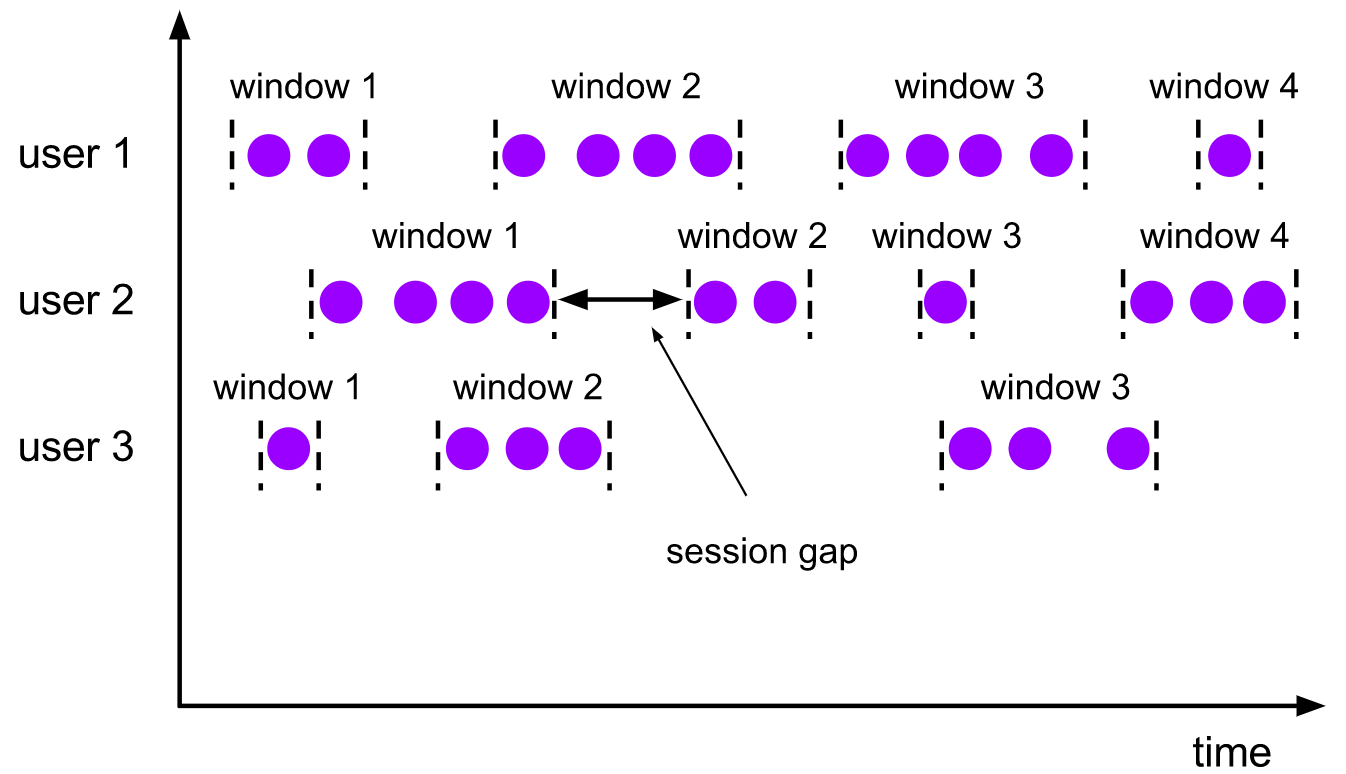
【特点】
- 由一系列事件组合一个指定时间长度的 timeout 间隙组成,也就是
一段时间没有接收到新数据就会生成新的窗口 - 时间无对齐
- 窗口长度不固定,也不会重叠
【示例代码】
EventTimeSessionWindows:会话事件时间窗口
SlidingProcessingTimeWindows:会话处理时间窗口
val input: DataStream[T] = ...
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
三、window API
窗口分配器 —— window() 方法
- 我们可以用
.window()来定义一个窗口,然后基于这个 window 去做一些聚
合或者其它处理操作。注意 window () 方法必须在keyBy之后才能用。 - Flink 提供了更加简单的三种类型时间窗口用于定义时
间窗口,也提供了countWindowAll来定义计数窗口。
TumblingEventTimeWindows:滚动事件时间窗口
TumblingProcessingTimeWindows:滚动处理时间窗口
SlidingEventTimeWindows:滑动事件时间窗口
SlidingProcessingTimeWindows:滑动处理时间窗口
EventTimeSessionWindows:会话事件时间窗口
SlidingProcessingTimeWindows:会话处理时间窗口
四、窗口分配器(window assigner)
window function 定义了要对窗口中收集的数据做的计算操作。可以分为两类。
1)增量聚合函数(incremental aggregation functions)
- 每条数据到来就进行计算,保持一个简单的状态
- ReduceFunction
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
- AggregateFunction
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)
2)全窗口函数(full window functions)
- 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
- ProcessWindowFunction
一个ProcessWindowFunction可以这样定义和使用:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
3)其它可选window API
- .trigger() —— 触发器,定义 window 什么时候关闭,触发计算并输出结果
- .evictor() —— 移除器,定义移除某些数据的逻辑
- .allowedLateness() —— 允许处理迟到的数据
- .sideOutputLateData() —— 将迟到的数据放入侧输出流
- .getSideOutput() —— 获取侧输出流
五、Flink 中的时间语义
官方文档
Flink 明确支持以下三种时间语义:
-
事件时间(event time): 事件产生的时间,记录的是设备生产(或者存储)事件的时间
-
摄取时间(ingestion time): 数据进入Flink的时间,Flink 读取事件时记录的时间
-
处理时间(processing time):执行操作算子的本地系统时间,与机器相关
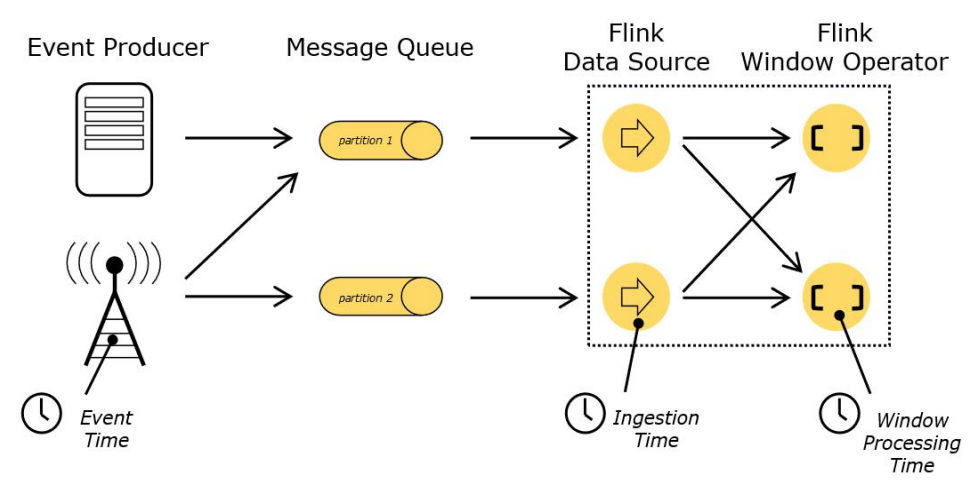
上面图片来源:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/concepts/time/
六、设置 Event Time
我们可以直接在代码中,对执行环境调用
setStreamTimeCharacteristic
方法,设置流的时间特性,具体的时间,还需要从数据中提取时间戳(timestamp)
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
var env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
七、水位线(Watermark)
1)为什么需要水位线(Watermark)
当 Flink 以 Event Time 模式处理数据流时,它会根据数据里的时间戳来
处理基于时间的算子,由于网络、分布式等原因,会导致乱序数据的产生,乱序数据会让窗口计算不准确。Watermark正是处理乱序数据而来的。
2)如何利用Watermark处理乱序数据问题?
遇到一个时间戳达到了窗口关闭时间,不应该立刻触发窗口计算,而是等
待一段时间,等迟到的数据来了再关闭窗口。
- Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发;
- Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用
Watermark 机制结合 window 来实现; - 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,
都已经到达了,因此,window 的执行也是由 Watermark 触发的; - watermark 用来让程序自己平衡延迟和结果正确性。
3)watermark 的特点
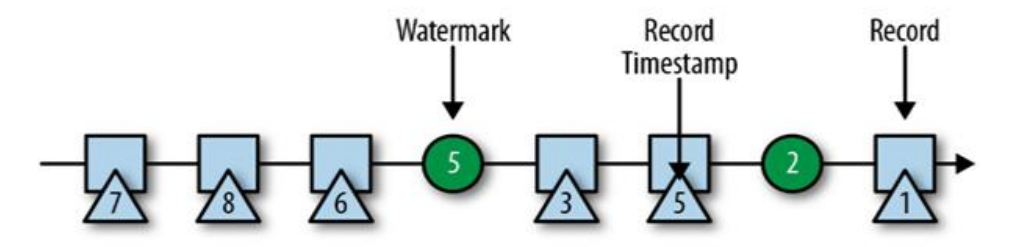
- watermark 是一条特殊的数据记录
- watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不
是在后退 - watermark 与数据的时间戳相关
4)watermark 的传递

5)watermark 策略与应用
1)Watermark 策略简介
时间戳的分配与 watermark 的生成是齐头并进的,其可以告诉 Flink 应用程序事件时间的进度。其可以通过指定
WatermarkGenerator来配置 watermark 的生成方式。
使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy。WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,并且用户也可以在某些必要场景下构建自己的 watermark 策略。WatermarkStrategy 接口如下:
public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{
/**
* 根据策略实例化一个可分配时间戳的 {@link TimestampAssigner}。
*/
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
/**
* 根据策略实例化一个 watermark 生成器。
*/
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
通常情况下,你不用实现此接口,而是可以使用
WatermarkStrategy工具类中通用的watermark策略,或者可以使用这个工具类将自定义的TimestampAssigner与WatermarkGenerator进行绑定。
【例如】你想要要使用有界无序(bounded-out-of-orderness)watermark 生成器和一个 lambda 表达式作为时间戳分配器,那么可以按照如下方式实现:
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withTimestampAssigner(new SerializableTimestampAssigner[(Long, String)] {
override def extractTimestamp(element: (Long, String), recordTimestamp: Long): Long = element._1
})
【温馨提示】其中 TimestampAssigner 的设置与否是可选的,大多数情况下,可以不用去特别指定。
2)使用 Watermark 策略应用
WatermarkStrategy 可以在 Flink 应用程序中的两处使用:
- 第一种是直接在数据源上使用
- 第二种是直接在非数据源的操作之后使用。
【温馨提示】第一种方式相比会更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确。
【示例】仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy):
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream: DataStream[MyEvent] = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter())
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.filter( _.severity == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>)
withTimestampsAndWatermarks
.keyBy( _.getGroup )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) => a.add(b) )
.addSink(...)
【示例】处理空闲数据源
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当某些其他分区仍然发送事件数据的时候就会出现问题。由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化。
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1))
3)使用场景
- 对于排好序的数据,不需要延迟触发,可以只指定时间戳就行了。
// 注意时间是毫秒,所以根据时间戳不同,可能需要乘以1000
dataStream.assignAscendingTimestamps(_.timestamp * 1000)
- Flink 暴露了 TimestampAssigner 接口供我们实现,使我们可以自定义如
何从事件数据中抽取时间戳和生成watermark。
// MyAssigner 可以有两种类型,都继承自 TimestampAssigner
dataStream.assignAscendingTimestamps(new MyAssigner())
4)TimestampAssigner
定义了抽取时间戳,以及生成 watermark 的方法,有两种类型
1、AssignerWithPeriodicWatermarks
- 周期性的生成 watermark:系统会周期性的将 watermark 插入到流中
- 默认周期是200毫秒,可以使用 ExecutionConfig.setAutoWatermarkInterval()
方法进行设置 - 升序和前面乱序的处理 BoundedOutOfOrderness ,都是基于周期性
watermark 的。
2、AssignerWithPunctuatedWatermarks
- 没有时间周期规律,可打断的生成 watermark
可以弃用 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 了
在 Flink 新的
WatermarkStrategy,TimestampAssigner和WatermarkGenerator的抽象接口之前,Flink 使用的是 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks。你仍可以在 API 中看到它们,但建议使用新接口,因为其对时间戳和 watermark 等重点的抽象和分离很清晰,并且还统一了周期性和标记形式的 watermark 生成方式。
5)WatermarkStrategy(重点)
flink1.11版本后 建议用
WatermarkStrategy(Watermark生成策略)生成Watermark,当创建DataStream对象后,使用如下方法指定策略:assignTimestampsAndWatermarks(WatermarkStrategy<T>)
通常情况下,你不用实现此接口,而是可以使用
WatermarkStrategy工具类中通用的 watermark 策略,或者可以使用这个工具类将自定义的 TimestampAssigner 与 WatermarkGenerator 进行绑定。
1、固定乱序长度策略(forBoundedOutOfOrderness)
通过调用WatermarkStrategy对象上的forBoundedOutOfOrderness方法来实现,接收一个Duration类型的参数作为最大乱序(out of order)长度。WatermarkStrategy对象上的withTimestampAssigner方法为从事件数据中提取时间戳提供了接口。
【示例】
- ForBoundedOutOfOrderness.java
package com.com.streaming.watermarkstrategy;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
import java.time.LocalDateTime;
//在assignTimestampsAndWatermarks中用WatermarkStrategy.forBoundedOutOfOrderness方法抽取Timestamp和生成周期性水位线示例
public class ForBoundedOutOfOrderness {
public static void main(String[] args) throws Exception{
//创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置EventTime语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置周期生成Watermark间隔(10毫秒)
env.getConfig().setAutoWatermarkInterval(10L);
//并行度1
env.setParallelism(1);
//演示数据
DataStreamSource<ClickEvent> mySource = env.fromElements(
new ClickEvent(LocalDateTime.now(), "user1", 1L, 1),
new ClickEvent(LocalDateTime.now(), "user1", 2L, 2),
new ClickEvent(LocalDateTime.now(), "user1", 3L, 3),
new ClickEvent(LocalDateTime.now(), "user1", 4L, 4),
new ClickEvent(LocalDateTime.now(), "user1", 5L, 5),
new ClickEvent(LocalDateTime.now(), "user1", 6L, 6),
new ClickEvent(LocalDateTime.now(), "user1", 7L, 7),
new ClickEvent(LocalDateTime.now(), "user1", 8L, 8)
);
//WatermarkStrategy.forBoundedOutOfOrderness周期性生成水位线
//可更好处理延迟数据
//BoundedOutOfOrdernessWatermarks<T>实现WatermarkGenerator<T>
SingleOutputStreamOperator<ClickEvent> streamTS = mySource.assignTimestampsAndWatermarks(
//指定Watermark生成策略,最大延迟长度5毫秒
WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofMillis(5))
.withTimestampAssigner(
//SerializableTimestampAssigner接口中实现了extractTimestamp方法来指定如何从事件数据中抽取时间戳
new SerializableTimestampAssigner<ClickEvent>() {
@Override
public long extractTimestamp(ClickEvent event, long recordTimestamp) {
return event.getDateTime(event.getEventTime());
}
})
);
//结果打印
streamTS.print();
env.execute();
}
}
- ClickEvent.java
package com.com.streaming.watermarkstrategy;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
public class ClickEvent {
private String user;
private long l;
private int i;
private LocalDateTime eventTime;
public ClickEvent(LocalDateTime eventTime, String user, long l, int i) {
this.eventTime = eventTime;
this.user = user;
this.l = l;
this.i = i;
}
public LocalDateTime getEventTime() {
return eventTime;
}
public void setEventTime(LocalDateTime eventTime) {
this.eventTime = eventTime;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public long getL() {
return l;
}
public void setL(long l) {
this.l = l;
}
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public long getDateTime(LocalDateTime dt) {
ZoneOffset zoneOffset8 = ZoneOffset.of("+8");
return dt.toInstant(zoneOffset8).toEpochMilli();
}
}
2、单调递增策略(forMonotonousTimestamps)
通过调用WatermarkStrategy对象上的forMonotonousTimestamps方法来实现,无需任何参数,相当于将forBoundedOutOfOrderness策略的最大乱序长度outOfOrdernessMillis设置为0。
- ForMonotonousTimestamps.java
package com.com.streaming.watermarkstrategy;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
import java.time.LocalDateTime;
public class ForMonotonousTimestamps {
public static void main(String[] args) throws Exception{
//创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置EventTime语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置周期生成Watermark间隔(10毫秒)
env.getConfig().setAutoWatermarkInterval(10L);
//并行度1
env.setParallelism(1);
//演示数据
DataStreamSource<ClickEvent> mySource = env.fromElements(
new ClickEvent(LocalDateTime.now(), "user1", 1L, 1),
new ClickEvent(LocalDateTime.now(), "user1", 2L, 2),
new ClickEvent(LocalDateTime.now(), "user1", 3L, 3),
new ClickEvent(LocalDateTime.now(), "user1", 4L, 4),
new ClickEvent(LocalDateTime.now(), "user1", 5L, 5),
new ClickEvent(LocalDateTime.now(), "user1", 6L, 6),
new ClickEvent(LocalDateTime.now(), "user1", 7L, 7),
new ClickEvent(LocalDateTime.now(), "user1", 8L, 8)
);
//WatermarkStrategy.forMonotonousTimestamps周期性生成水位线
//相当于延迟outOfOrdernessMillis=0
//继承自BoundedOutOfOrdernessWatermarks<T>
SingleOutputStreamOperator<ClickEvent> streamTS = mySource.assignTimestampsAndWatermarks(
WatermarkStrategy.<ClickEvent>forMonotonousTimestamps()
.withTimestampAssigner((event, recordTimestamp) -> event.getDateTime(event.getEventTime()))
);
//结果打印
streamTS.print();
env.execute();
}
}
3、不生成策略(noWatermarks)
WatermarkStrategy.noWatermarks()
- 当一个算子从多个上游算子中获取数据时,会取上游最小的Watermark作为自身的Watermark,并检测是否满足窗口触发条件。当达不到触发条件,窗口会在内存中缓存大量窗口数据,导致内存不足等问题。
- flink提供了设置流状态为空闲的
withIdleness方法。在设置的超时时间内,当某个数据流一直没有事件数据到达,就标记这个流为空闲。下游算子不需要等待这条数据流产生的Watermark,而取其他上游激活状态的Watermark,来决定是否需要触发窗口计算。
上面代码设置超时时间5毫秒,超过这个时间,没有生成Watermark,将流状态设置空闲,当下次有新的Watermark生成并发送到下游时,重新设置为活跃。
WatermarkStrategy.withIdleness(Duration.ofMillis(5))
未完待续~