一、Spark SQL概述
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象叫做DataFrame和DataSet并且作为分布式SQL查询引擎的作用,其实也是对RDD的再封装。大数据Hadoop之——计算引擎Spark,官方文档:https://spark.apache.org/sql/
二、SparkSQL版本
1)SparkSQL的演变之路

-
1.0以前: Shark(入口:SQLContext和HiveContext)
- SQLContext:主要DataFrame的构建以及DataFrame的执行,SQLContext指的是spark中SQL模块的程序入口。
- HiveContext:是SQLContext的子类,专门用于与Hive的集成,比如读取Hive的元数据,数据存储到Hive表、Hive的窗口分析函数等。
-
1.1.x开始:SparkSQL(只是测试性的)
-
1.3.x: SparkSQL(正式版本)+Dataframe
-
1.5.x: SparkSQL 钨丝计划
-
1.6.x: SparkSQL+DataFrame+DataSet(测试版本)
-
2.x:
- 入口:SparkSession(spark应用程序的一个整体入口),合并了SQLContext和HiveContext
- SparkSQL+DataFrame+DataSet(正式版本)
- Spark Streaming-》Structured Streaming(DataSet)
2)shark与SparkSQL对比
- shark
- 执行计划优化完全依赖于Hive,不方便添加新的优化策略;
- Spark是线程级并行,而MapReduce是进程级并行。
- Spark在兼容Hive的实现上存在线程安全问题,导致Shark
不得不使用另外一套独立维护的打了补丁的Hive源码分支;
- Spark SQL
- 作为Spark生态的一员继续发展,而不再受限于Hive,
- 只是兼容Hive;Hive on Spark作为Hive的底层引擎之一
- Hive可以采用Map-Reduce、Tez、Spark等引擎
3)SparkSession
- SparkSession是Spark 2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
- 在spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。
【例如】对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来。
- SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的,在spark 2.x中不推荐使用SparkContext对象读取数据,而是推荐SparkSession。
三、RDD、DataFrames和DataSet
1)三者关联关系
DataFrame 和 DataSet 是 Spark SQL 提供的基于 RDD 的结构化数据抽象。它既有 RDD 不可变、分区、存储依赖关系等特性,又拥有类似于关系型数据库的结构化信息。所以,基于 DataFrame 和 DataSet API 开发出的程序会被自动优化,使得开发人员不需要操作底层的 RDD API 来进行手动优化,大大提升开发效率。但是 RDD API 对于非结构化的数据处理有独特的优势,比如文本流数据,而且更方便我们做底层的操作。
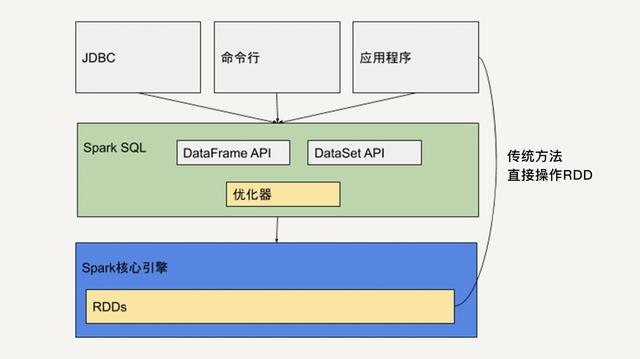
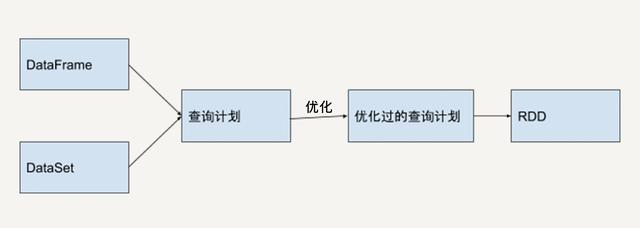
1)RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
1、核心概念
-
一组分片(Partition):即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
-
一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
-
RDD之间的依赖关系:RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
-
一个Partitioner:即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
-
一个列表:存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
2、RDD简单操作
启动spark-shell,其实spark-shell低层也是调用spark-submit,首先需要配置好,当然也可以写在命令行,但是不推荐。配置如下,仅供参考(这里使用yarn模式):
$ cat spark-defaults.conf

启动spark-shell(下面会详解讲解)
$ spark-shell
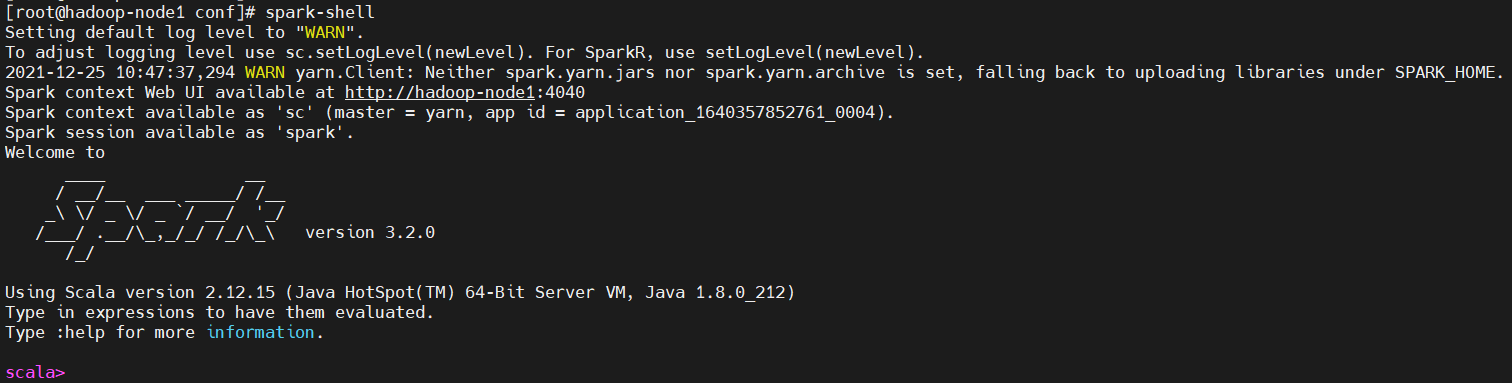
【问题】发现有个WARN:WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
【原因】是因为Spark提交任务到yarn集群,需要上传相关spark的jar包到HDFS。
【解决】 提前上传到HDFS集群,并且在Spark配置文件指定文件路径,就可以避免每次提交任务到Yarn都需要重复上传文件。下面是解决的具体操作步骤:
### 打包jars,jar相关的参数说明
#-c 创建一个jar包
# -t 显示jar中的内容列表
#-x 解压jar包
#-u 添加文件到jar包中
#-f 指定jar包的文件名
#-v 生成详细的报造,并输出至标准设备
#-m 指定manifest.mf文件.(manifest.mf文件中可以对jar包及其中的内容作一些一设置)
#-0 产生jar包时不对其中的内容进行压缩处理
#-M 不产生所有文件的清单文件(Manifest.mf)。这个参数与忽略掉-m参数的设置
#-i 为指定的jar文件创建索引文件
#-C 表示转到相应的目录下执行jar命令,相当于cd到那个目录,然后不带-C执行jar命令
$ cd /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2
$ jar cv0f spark-libs.jar -C ./jars/ .
$ ll
### 在hdfs上创建存放jar包目录
$ hdfs dfs -mkdir -p /spark/jars
## 上传jars到HDFS
$ hdfs dfs -put spark-libs.jar /spark/jars/
## 增加配置spark-defaults.conf
spark.yarn.archive=hdfs:///spark/jars/spark-libs.jar
然后再启动spark-shell
在Spark Shell中,有一个专有的SparkContext已经为您创建好了,变量名叫做sc,自己创建的SparkContext将无法工作。
$ spark-shell
### 由一个已经存在的Scala集合创建。
val array = Array(1,2,3,4,5)
# spark使用parallelize方法创建RDD
val rdd = sc.parallelize(array)
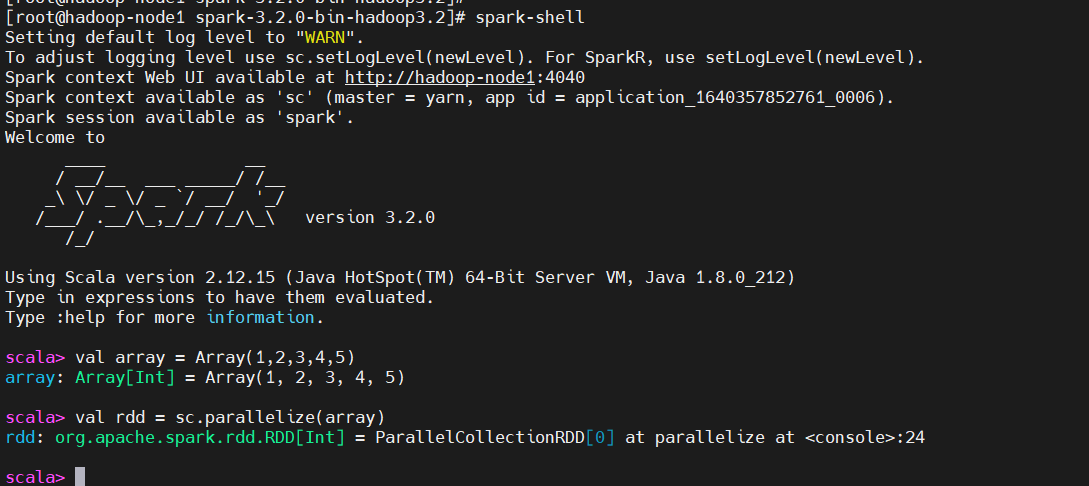
这里只是简单的创建RDD操作,后面会有更多RDD相关的演示操作。
3、RDD API
Spark支持两个类型(算子)操作:Transformation和Action
1)Transformation
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
常用的Transformation:
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 先按分区聚合 再总的聚合 每次要跟初始值交流 例如:aggregateByKey(0)(+,+) 对k/y的RDD进行操作 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 第一个参数是根据什么排序 第二个是怎么排序 false倒序 第三个排序后分区数 默认与原RDD一样 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集) |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable |
| cartesian(otherDataset) | 两个RDD的笛卡尔积 的成很多个K/V |
| pipe(command, [envVars]) | 调用外部程序 |
| coalesce(numPartitions) | 重新分区 第一个参数是要分多少区,第二个参数是否shuffle 默认false 少分区变多分区 true 多分区变少分区 false |
| repartition(numPartitions) | |
| 重新分区 必须shuffle 参数是要分多少区 少变多 | |
| repartitionAndSortWithinPartitions(partitioner) | 重新分区+排序 比先分区再排序效率高 对K/V的RDD进行操作 |
| foldByKey(zeroValue)(seqOp) | 该函数用于K/V做折叠,合并处理 ,与aggregate类似 第一个括号的参数应用于每个V值 第二括号函数是聚合例如:+ |
| combineByKey | 合并相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) |
| partitionBy(partitioner) | 对RDD进行分区 partitioner是分区器 例如new HashPartition(2) |
| cache/persist | RDD缓存,可以避免重复计算从而减少时间,区别:cache内部调用了persist算子,cache默认就一个缓存级别MEMORY-ONLY ,而persist则可以选择缓存级别 |
| Subtract(rdd) | 返回前rdd元素不在后rdd的rdd |
| leftOuterJoin | leftOuterJoin类似于SQL中的左外关联left outer join,返回结果以前面的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可。 |
| rightOuterJoin | rightOuterJoin类似于SQL中的有外关联right outer join,返回结果以参数中的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可 |
| subtractByKey | substractByKey和基本转换操作中的subtract类似只不过这里是针对K的,返回在主RDD中出现,并且不在otherRDD中出现的元素 |
2)Action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。
常用的Action:
| 动作 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 返回原RDD排序(默认升序排)后,前n个元素组成的数组 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | saveAsObjectFile用于将RDD中的元素序列化成对象,存储到文件中。使用方法和saveAsTextFile类似 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 |
| aggregate | 先对分区进行操作,在总体操作 |
| reduceByKeyLocally | 返回一个 dict 对象,同样是将同 key 的元素进行聚合 |
| lookup | lookup用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值。 |
| top | top函数用于从RDD中,按照默认(降序)或者指定的排序规则,返回前num个元素。 |
| fold | fold是aggregate的简化,将aggregate中的seqOp和combOp使用同一个函数op。 |
| foreachPartition | 遍历原RDD元素经过func函数运算过后的结果集,foreachPartition算子分区操作 |
4、实战操作
1、针对各个元素的转化操作
我们最常用的转化操作应该是map() 和filter(),转化操作map() 接收一个函数,把这个函数用于RDD 中的每个元素,将函数的返回结果作为结果RDD 中对应元素的值。而转化操作filter() 则接收一个函数,并将RDD 中满足该函数的元素放入新的RDD 中返回。
让我们看一个简单的例子,用map() 对RDD 中的所有数求平方
# 通过parallelize创建RDD对象
val input = sc.parallelize(List(1, 2, 3, 4))
val result = input.map(x => x * x)
println(result.collect().mkString(","))

2、对一个数据为{1,2,3,3}的RDD进行基本的RDD转化操作(去重)
var rdd = sc.parallelize(List(1,2,3,3))
rdd.distinct().collect().mkString(",")

3、对数据分别为{1,2,3}和{3,4,5}的RDD进行针对两个RDD的转化操作
var rdd = sc.parallelize(List(1,2,3))
var other = sc.parallelize(List(3,4,5))
# 生成一个包含两个RDD中所有元素的RDD
rdd.union(other).collect().mkString(",")
# 求两个RDD共同的元素RDD
rdd.intersection(other).collect().mkString(",")

4、行动操作
行动操作reduce(),它接收一个函数作为参数,这个函数要操作两个RDD 的元素类型的数据并返回一个同样类型的新元素。一个简单的例子就是函数+,可以用它来对我们的RDD 进行累加。使用reduce(),可以很方便地计算出RDD中所有元素的总和、元素的个数,以及其他类型的聚合操作。
var rdd = sc.parallelize(List(1,2,3,4,5,6,7))
# 求和
var sum = rdd.reduce((x, y) => x + y)
# 求元素个数
var sum = rdd.count()
# 聚合操作
var rdd = sc.parallelize(List(1,2,3,4,5,6,7))
var result = rdd.aggregate((0,0))((acc,value) => (acc._1 + value,acc._2 + 1),(acc1,acc2) => (acc1._1 + acc2._1 , acc1._2 + acc2._2))
var avg = result._1/result._2.toDouble
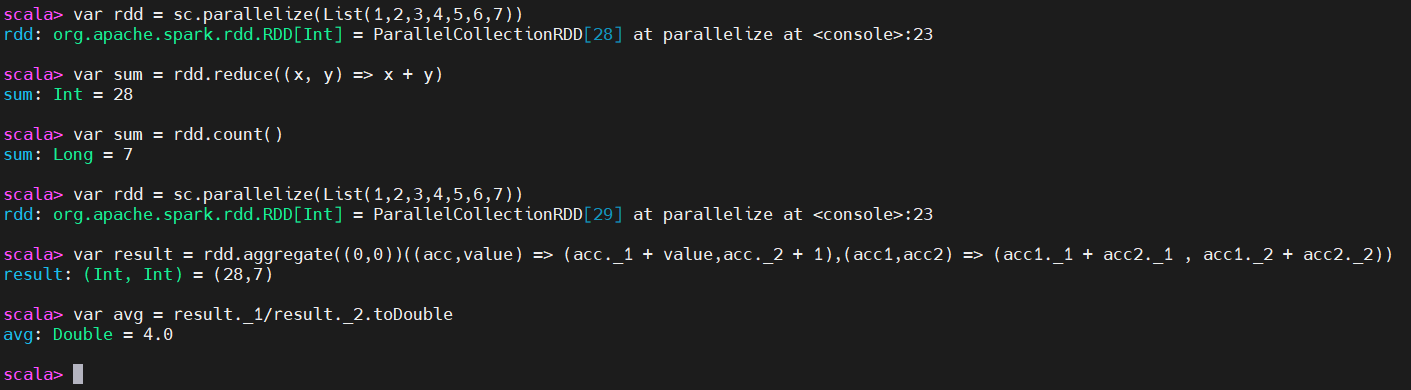
这里只是演示几个简单的示例,更多RDD的操作,可以参考官方文档学习哦。
2)DataFrames
在Spark中,DataFrame提供了一个领域特定语言(DSL)和SQL来操作结构化数据,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
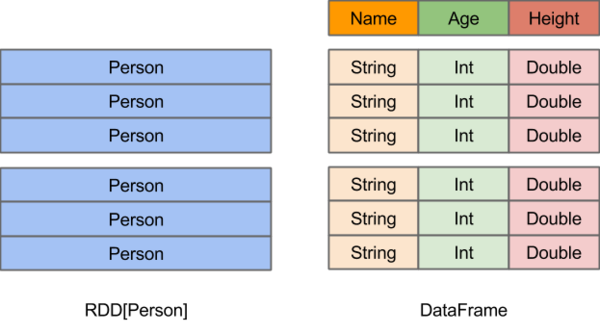
- RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
- DataFrame底层是以RDD为基础的分布式数据集,和RDD的主要区别的是:RDD中没有schema信息,而DataFrame中数据每一行都包含schema。DataFrame = RDD + shcema
1、DSL风格语法操作
1)DataFrame创建
创建DataFrame的两种基本方式:
- 已存在的RDD调用toDF()方法转换得到DataFrame。
- 通过Spark读取数据源直接创建DataFrame。
直接创建DataFarme对象
若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,如下所示。
| 方法名 | 描述 |
|---|---|
| spark.read.text(“people.txt”) | 读取txt格式文件,创建DataFrame |
| spark.read.csv (“people.csv”) | 读取csv格式文件,创建DataFrame |
| spark.read.text(“people.json”) | 读取json格式文件,创建DataFrame |
| spark.read.text(“people.parquet”) | 读取parquet格式文件,创建DataFrame |
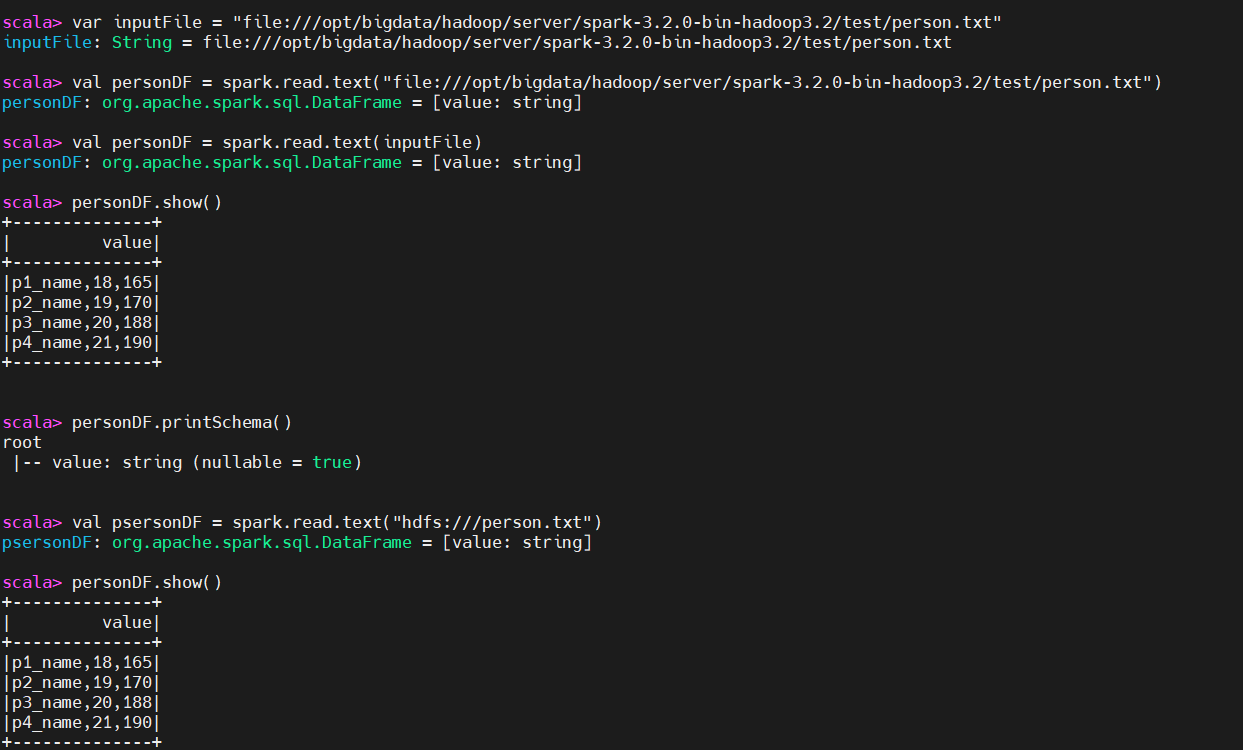
1、在本地创建一个person.txt文本文档,用于读取:运行spark-shell:
# person.txt,Name,Age,Height
p1_name,18,165
p2_name,19,170
p3_name,20,188
p4_name,21,190
# 启动spark shell,默认会创建一个spark名称的spark session对象
$ spark-shell
# 定义变量,【注意】所有节点都得创建这个person文件,要不然调度没有这个文件的机器会报错
var inputFile = "file:///opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/test/person.txt"
# 读取本地文件
val personDF = spark.read.text("file:///opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/test/person.txt")
val personDF = spark.read.text(inputFile)
# 显示
personDF.show()
# 将文件put到hdfs上
# 读取hdfs文件(推荐)
val psersonDF = spark.read.text("hdfs:///person.txt")
2、有RDD转换成DataFrame
| 动作 | 含义 |
|---|---|
| show() | 查看DataFrame中的具体内容信息 |
| printSchema() | 查看DataFrame的Schema信息 |
| select() | 查看DataFrame中选取部分列的数据及进行重命名 |
| filter() | 实现条件查询,过滤出想要的结果 |
| groupBy() | 对记录进行分组 |
| sort() | 对特定字段进行排序操作 |
| toDF() | 把RDD数据类型转成DataFarme |
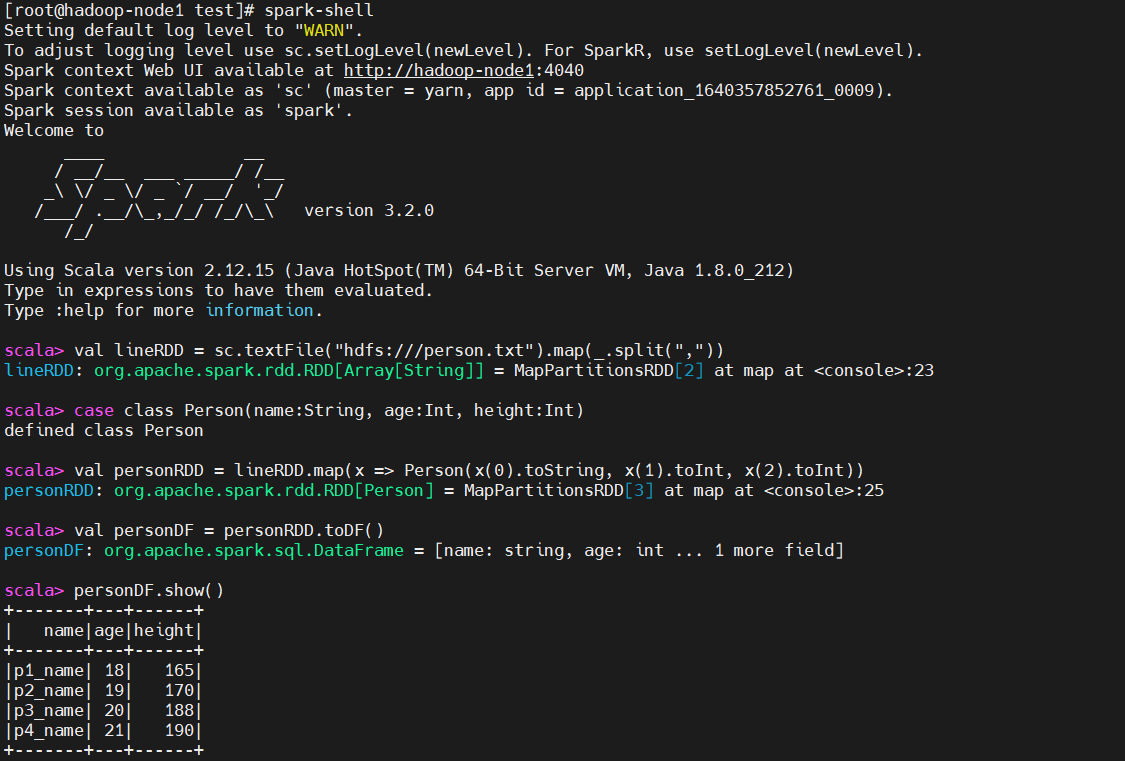
# 读取文本文档,按逗号分割开来
val lineRDD = sc.textFile("hdfs:///person.txt").map(_.split(","))
case class Person(name:String, age:Int, height:Int)
# 按照样式类对RDD数据进行分割成map
val personRDD = lineRDD.map(x => Person(x(0).toString, x(1).toInt, x(2).toInt))
# 把RDD数据类型转成DataFarme
val personDF = personRDD.toDF()
# 查看这个表
personDF.show()
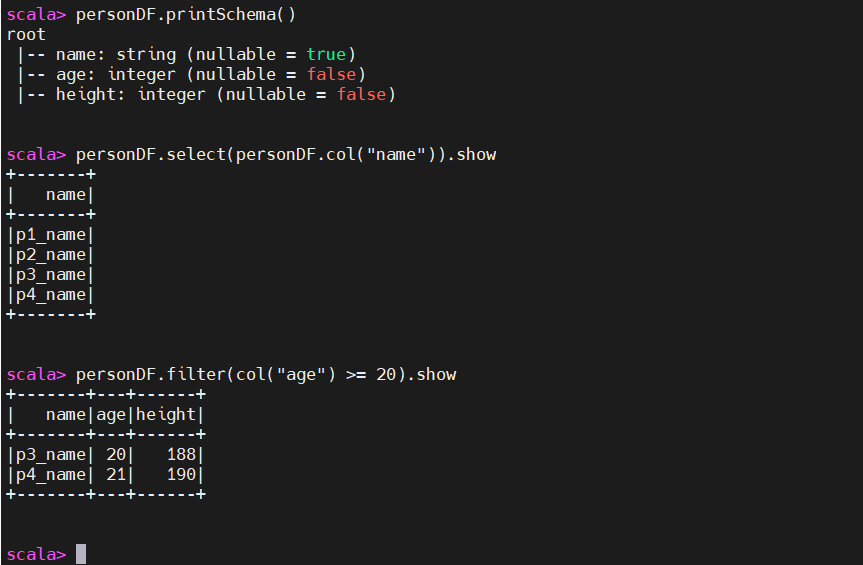
# 查看Schema数据
personDF.printSchema()
# 查看列
personDF.select(personDF.col("name")).show
# 过滤年龄小于25的
personDF.filter(col("age") >= 25).show
这里提供常用的spark dataframe方法:
| 方法名 | 含义 |
|---|---|
| collect() | 返回值是一个数组,返回dataframe集合所有的行 |
| collectAsList() | 返回值是一个java类型的数组,返回dataframe集合所有的行 |
| count() | 返回一个number类型的,返回dataframe集合的行数 |
| describe(cols: String*) | 返回一个通过数学计算的类表值(count, mean, stddev, min, and max),这个可以传多个参数,中间用逗号分隔,如果有字段为空,那么不参与运算,只这对数值类型的字段。例如df.describe("age", "height").show() |
| first() | 返回第一行 ,类型是row类型 |
| head() | 返回第一行 ,类型是row类型 |
| head(n:Int) | 返回n行 ,类型是row 类型 |
| show() | 返回dataframe集合的值 默认是20行,返回类型是unit |
| show(n:Int) | 返回n行,返回值类型是unit |
| table(n:Int) | 返回n行 ,类型是row 类型 |
| cache() | 同步数据的内存 |
| columns | 返回一个string类型的数组,返回值是所有列的名字 |
| dtypes | 返回一个string类型的二维数组,返回值是所有列的名字以及类型 |
| explan() | 打印执行计划 物理的 |
| explain(n:Boolean) | 输入值为 false 或者true ,返回值是unit 默认是false ,如果输入true 将会打印 逻辑的和物理的 |
| isLocal | 返回值是Boolean类型,如果允许模式是local返回true 否则返回false |
| persist(newlevel:StorageLevel) | 返回一个dataframe.this.type 输入存储模型类型 |
| printSchema() | 打印出字段名称和类型 按照树状结构来打印 |
| registerTempTable(tablename:String) | 返回Unit ,将df的对象只放在一张表里面,这个表随着对象的删除而删除了 |
| schema | 返回structType 类型,将字段名称和类型按照结构体类型返回 |
| toDF() | 返回一个新的dataframe类型的 |
| toDF(colnames:String*) | 将参数中的几个字段返回一个新的dataframe类型的 |
| unpersist() | 返回dataframe.this.type 类型,去除模式中的数据 |
| unpersist(blocking:Boolean) | 返回dataframe.this.type类型 true 和unpersist是一样的作用false 是去除RDD |
| agg(expers:column*) | 返回dataframe类型 ,同数学计算求值 |
| agg(exprs: Map[String, String]) | 返回dataframe类型 ,同数学计算求值 map类型的 |
| agg(aggExpr: (String, String), aggExprs: (String, String)*) | 返回dataframe类型 ,同数学计算求值 |
| apply(colName: String) | 返回column类型,捕获输入进去列的对象 |
| as(alias: String) | 返回一个新的dataframe类型,就是原来的一个别名 |
| col(colName: String) | 返回column类型,捕获输入进去列的对象 |
| cube(col1: String, cols: String*) | 返回一个GroupedData类型,根据某些字段来汇总 |
| distinct | 去重 返回一个dataframe类型 |
| drop(col: Column) | 删除某列 返回dataframe类型 |
| dropDuplicates(colNames: Array[String]) | 删除相同的列 返回一个dataframe |
| except(other: DataFrame) | 返回一个dataframe,返回在当前集合存在的在其他集合不存在的 |
| filter(conditionExpr: String) | 刷选部分数据,返回dataframe类型 |
| groupBy(col1: String, cols: String*) | 根据某写字段来汇总返回groupedate类型 |
| intersect(other: DataFrame) | 返回一个dataframe,在2个dataframe都存在的元素 |
| join(right: DataFrame, joinExprs: Column, joinType: String) | 一个是关联的dataframe,第二个关联的条件,第三个关联的类型:inner, outer, left_outer, right_outer, leftsemi |
| limit(n: Int) | 返回dataframe类型 去n 条数据出来 |
| orderBy(sortExprs: Column*) | 做alise排序 |
| sort(sortExprs: Column*) | 排序 df.sort(df("age").desc).show(); 默认是asc |
| select(cols:string*) | dataframe 做字段的刷选 df.select($"colA", $"colB" + 1) |
| withColumnRenamed(existingName: String, newName: String) | 修改列表 df.withColumnRenamed("name","names").show(); |
| withColumn(colName: String, col: Column) | 增加一列 df.withColumn("aa",df("name")).show(); |
这里已经列出了很多常用方法了,基本上涵盖了大部分操作,当然也可以参考官方文档
2、SQL风格语法操作
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL查询,结果将作为一个DataFrame返回。因为spark session包含了Hive Context,所以spark.sql() 会自动启动连接hive,默认模式就是hive里的local模式(内嵌derby)
启动spark-shell
$ spark-shell
会在执行spark-shell当前目录下生成两个文件:derby.log,metastore_db
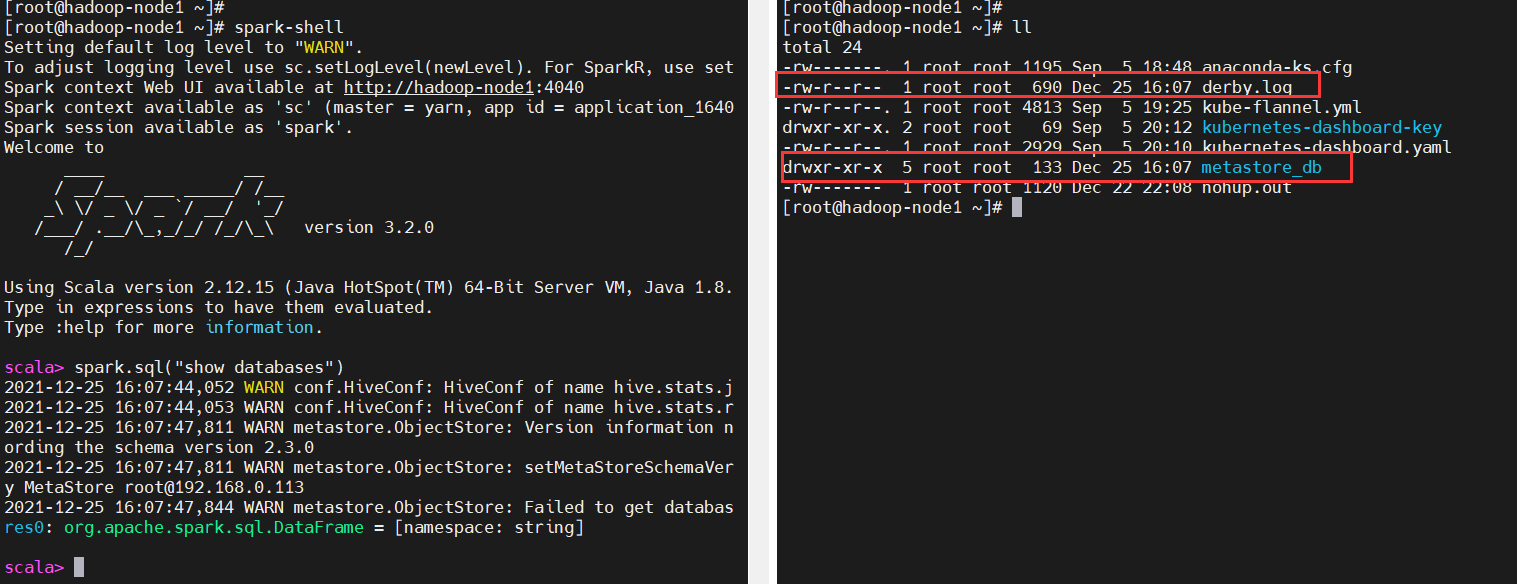
接下来就可以happy的写sql了,这里就演示几个命令,跟之前的hive一样,把sql语句放在spark.sql()方法里执行即可,不清楚hive sql的可以参考我之前的文章:大数据Hadoop之——数据仓库Hive
# 有个默认default库
$ spark.sql("show databases").show
# 默认当前库是default
$ spark.sql("show tables").show
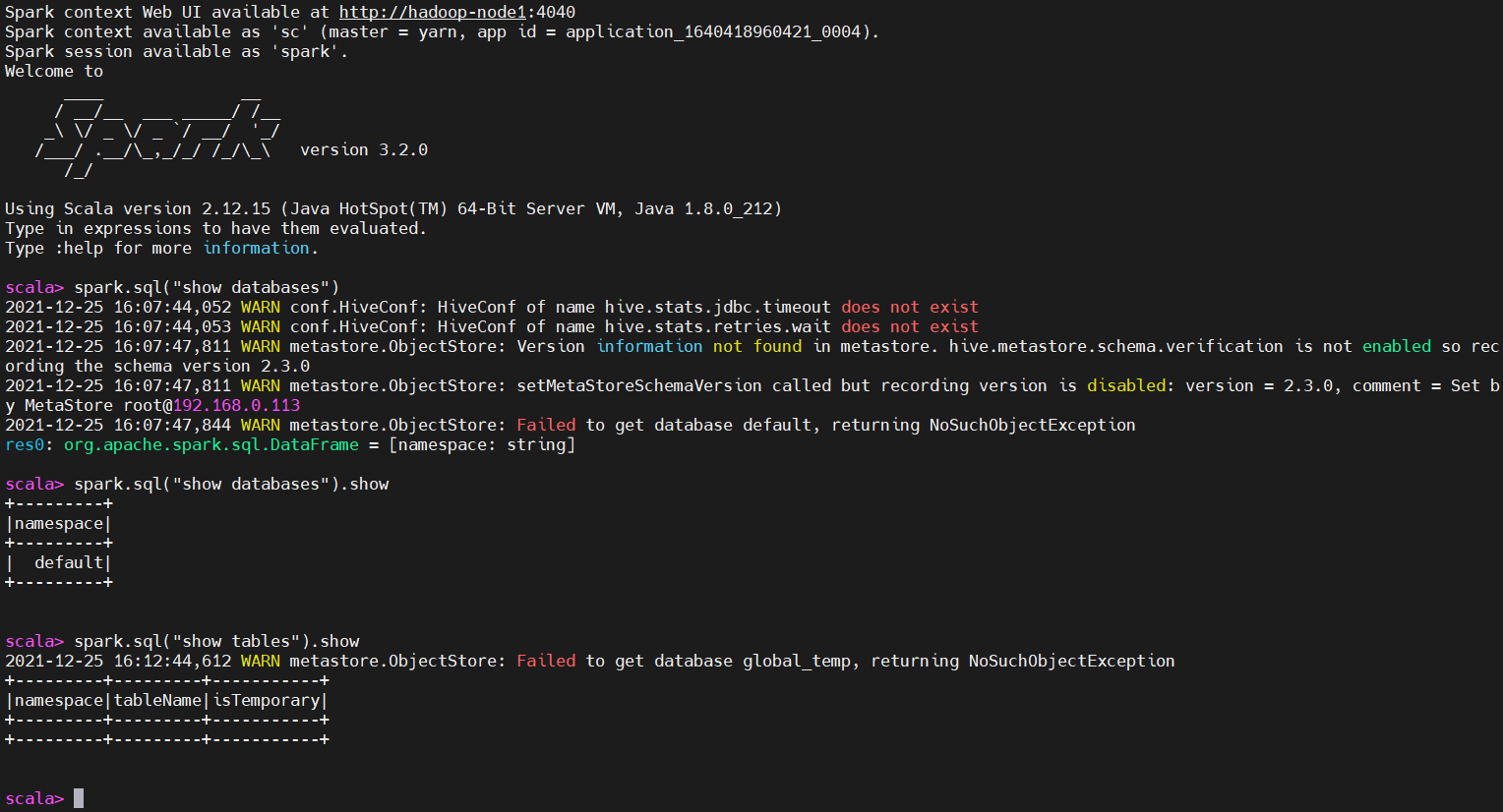
通过spark-sql启动spark shell
操作就更像sql语法了,已经跟hive差不多了。接下来演示几个命令,大家就很清楚了。
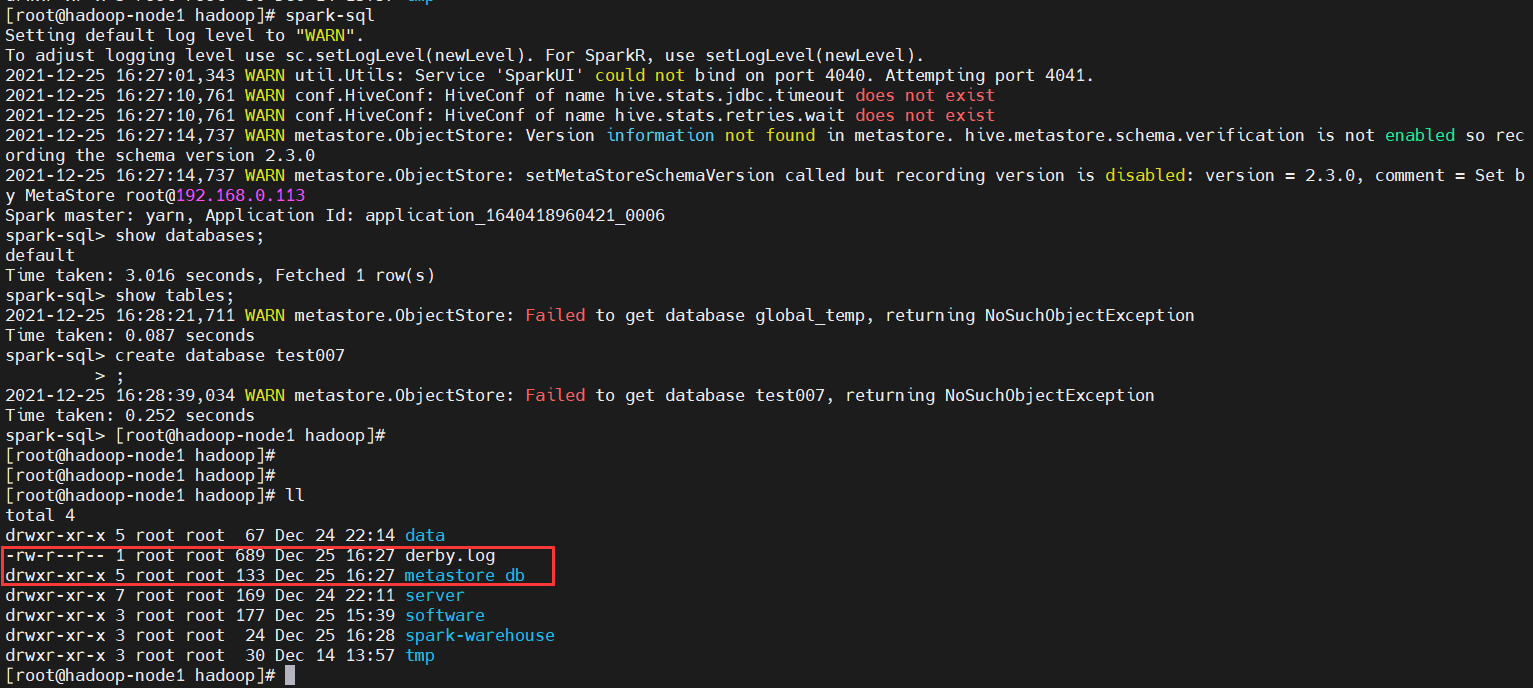
$ spark-sql
show databases;
create database test007
同样也会在当前目录下自动创建两个文件:derby.log,metastore_db
3)DataSet
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作。
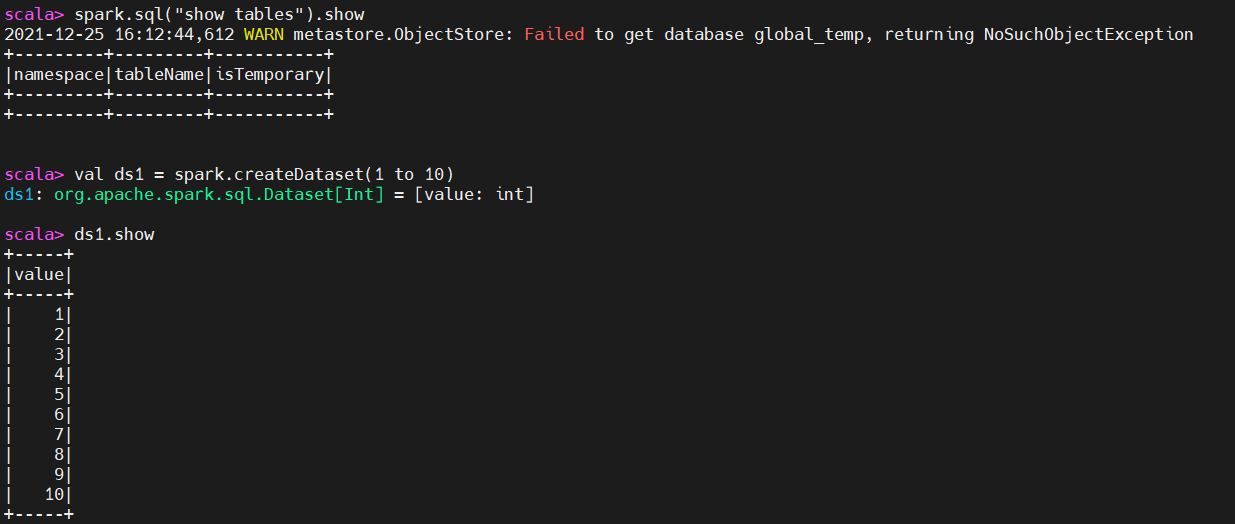
1、通过spark.createDataset通过集合进行创建dataSet
val ds1 = spark.createDataset(1 to 10)
ds1.show
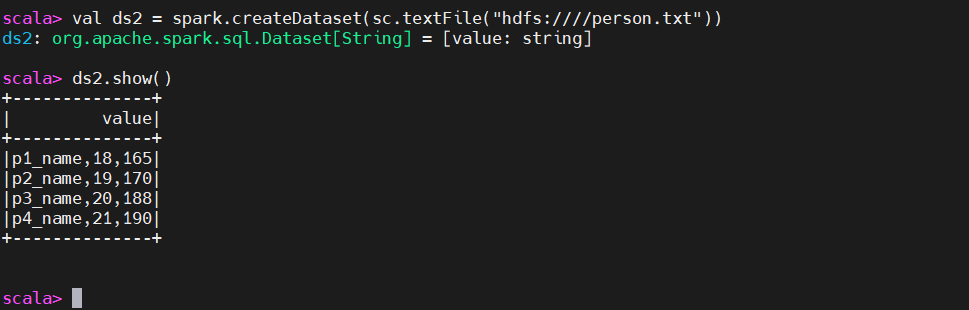
2、从已经存在的rdd当中构建dataSet
val ds2 = spark.createDataset(sc.textFile("hdfs:////person.txt"))
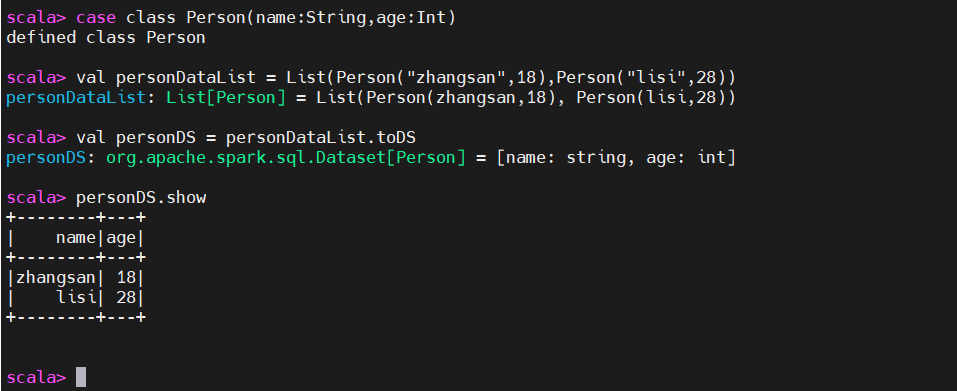
3、通过样例类配合创建DataSet
case class Person(name:String,age:Int)
val personDataList = List(Person("zhangsan",18),Person("lisi",28))
val personDS = personDataList.toDS
personDS.show
4、通过DataFrame转化生成
Music.json文件内容如下:
{"name":"上海滩","singer":"叶丽仪","album":"香港电视剧主题歌","path":"mp3/shanghaitan.mp3"}
{"name":"一生何求","singer":"陈百强","album":"香港电视剧主题歌","path":"mp3/shanghaitan.mp3"}
{"name":"红日","singer":"李克勤","album":"怀旧专辑","path":"mp3/shanghaitan.mp3"}
{"name":"爱如潮水","singer":"张信哲","album":"怀旧专辑","path":"mp3/airucaoshun.mp3"}
{"name":"红茶馆","singer":"陈惠嫻","album":"怀旧专辑","path":"mp3/redteabar.mp3"}
case class Music(name:String,singer:String,album:String,path:String)
# 注意把test.json传到hdfs上
val jsonDF = spark.read.json("hdfs:///Music.json")
val jsonDS = jsonDF.as[Music]
jsonDS.show

RDD,DataFrame,DataSet互相转化
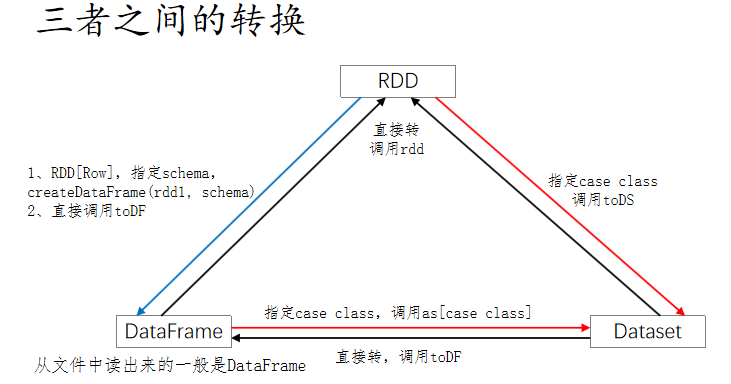
四、RDD、DataFrame和DataSet的共性与区别
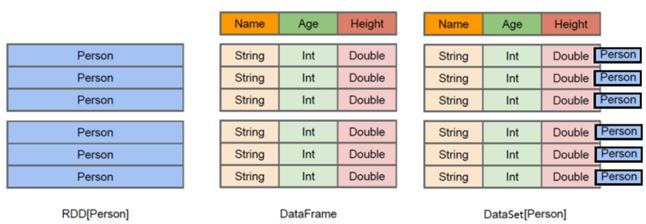
-
RDD[Person]:以Person为类型参数,但不了解 其内部结构。
-
DataFrame:提供了详细的结构信息schema(结构)列的名称和类型。这样看起来就像一张表了
-
DataSet[Person]:不光有schema(结构)信息,还有类型信息
1)共性
- 三者都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
- 三者都有惰性机制。在创建时、转换时(如map)不会立即执行,只有在遇到action算子的时候(比如foreach),才开始进行触发计算。极端情况下,如果代码中只有创建、转换,但是没有在后面的action中使用对应的结果,在执行时会被跳过。
- 三者都有partition的概念,都有缓存(cache)的操作,还可以进行检查点操作(checkpoint)
- 三者都有许多共同的函数(如map、filter,sorted等等)。
在对DataFrame和DataSet操作的时候,大多数情况下需要引入隐式转换(ssc.implicits._)
2)区别
- DataFrame:DataFrame是DataSet的特例,也就是说DataSet[Row]的别名;DataFrame = RDD + schema
- DataFrame的每一行的固定类型为Row,只有通过解析才能获得各个字段的值
- DataFrame与DataSet通常与spark ml同时使用
- DataFrame与DataSet均支持sparkSql操作,比如select,groupby等,也可以注册成临时表,进行sql语句操作
- DataFrame与DateSet支持一些方便的保存方式,比如csv,可以带上表头,这样每一列的字段名就可以一目了然
- DataSet:DataSet = RDD + case class
- DataSet与DataFrame拥有相同的成员函数,区别只是只是每一行的数据类型不同。
- DataSet的每一行都是case class,在自定义case class之后可以很方便的获取每一行的信息
五、spark-shell
Spark的shell作为一个强大的交互式数据分析工具,提供了一个简单的方式学习API。它可以使用Scala(在Java虚拟机上运行现有的Java库的一个很好方式)或Python。spark-shell的本质是在后台调用了spark-submit脚本来启动应用程序的,在spark-shell中会创建了一个名为sc的SparkContext对象。
【注】spark-shell只能以client方式启动。
查看帮助
$ spark-shell --help
spark-shell常用选项
--master MASTER_URL 指定模式(spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]))
--executor-memory MEM 指定每个Executor的内存,默认1GB
--total-executor-cores NUM 指定所有Executor所占的核数
--num-executors NUM 指定Executor的个数
--help, -h 显示帮助信息
--version 显示版本号
从上面帮助看,spark有五种运行模式:spark、mesos、yarn、k8s、local。这里主要讲local和yarn模式
| Master URL | 含义 |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力 |
| local[K] | 在本地运行,有 K 个工作进程,通常设置 K 为机器的CPU 核心数量 |
| local[*] | 在本地运行,工作进程数量等于机器的 CPU 核心数量。 |
| spark://HOST:PORT | 以 Standalone 模式运行,这是 Spark 自身提供的集群运行模式,默认端口号: 7077 |
| mesos://HOST:PORT | 在 Mesos 集群上运行,Driver 进程和 Worker 进程运行在 Mesos 集群上,部署模式必须使用固定值:--deploy-mode cluster |
| yarn | 在yarn集群上运行,依赖于hadoop集群,yarn资源调度框架,将应用提交给yarn,在ApplactionMaster(相当于Stand alone模式中的Master)中运行driver,在集群上调度资源,开启excutor执行任务。 |
| k8s | 在k8s集群上运行 |
1)local
在Spark Shell中,有一个专有的SparkContext已经为您创建好了,变量名叫做sc。自己创建的SparkContext将无法工作。可以用--master参数来设置SparkContext要连接的集群,用--jars来设置需要添加到CLASSPATH的jar包,如果有多个jar包,可以使用逗号分隔符连接它们。例如,在一个拥有2核的环境上运行spark-shell,使用:
#资源存储的位置,默认为本地,以及使用什么调度框架 ,默认使用的是spark内置的资源管理和调度框架Standalone
# local单机版,只占用一个线程,local[*]占用当前所有线程,local[2]:2个CPU核运行
$ spark-shell --master local[2]
# --master 默认为 local[*]
#默认使用集群最大的内存大小
--executor-memorty
#默认使用最大核数
--total-executor-cores
$ spark-shell --master local[*] --executor-memory 1g --total-executor-cores 1
Web UI地址:http://hadoop-node1:4040
随后,就可以使用spark-shell内使用Scala语言完成一定的操作。这里做几个简单的操作,有兴趣的话,可以自行去了解scala
val textFile = sc.textFile("file:///opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/README.md")
textFile.count()
textFile.first()
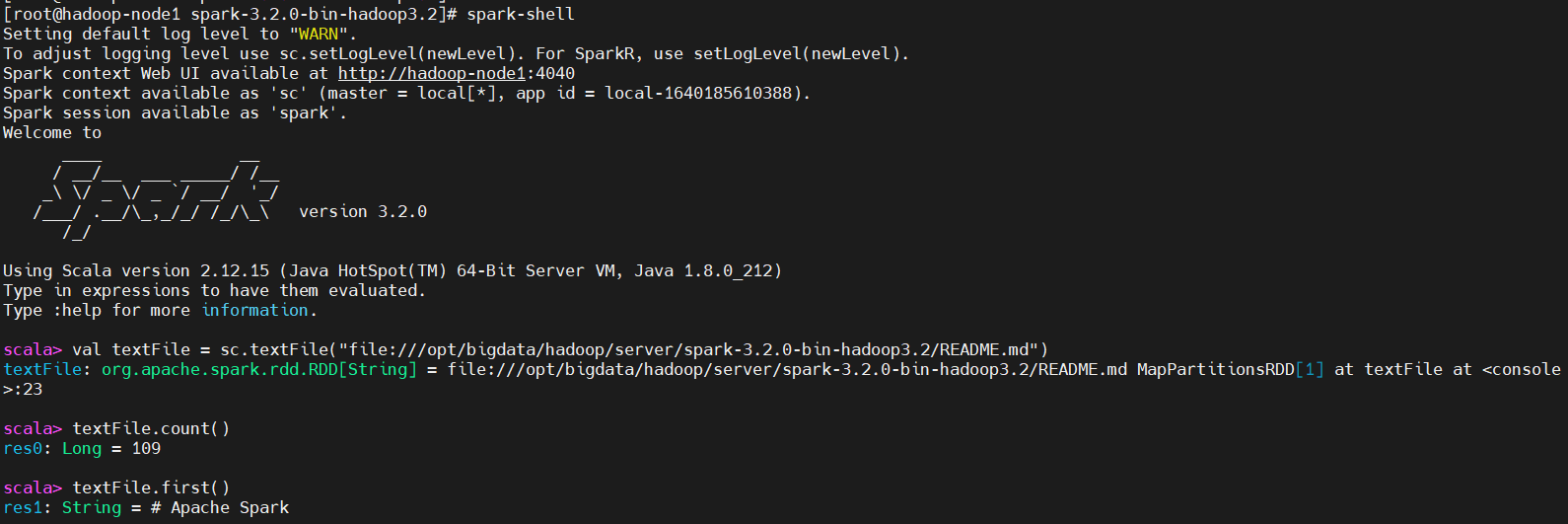
其中,count代表RDD中的总数据条数;first代表RDD中的第一行数据。
2)on Yarn(推荐)
# on yarn,也可以在配置文件中修改这个字段spark.master
$ spark-shell --master yarn
--master用来设置context将要连接并使用的资源主节点,master的值是standalone模式中spark的集群地址、yarn或mesos集群的URL,或是一个local地址。
六、SparkSQL和Hive的集成(Spark on Hive)
1)创建软链接
$ ln -s /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf/hive-site.xml /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/conf/hive-site.xml
2)复制 hive lib目录 下的mysql连接jar包到spark的jars下
$ cp /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/lib/mysql-connector-java-5.1.49-bin.jar /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/jars/
3)配置
# 创建spark日志在hdfs存储目录
$ hadoop fs -mkdir -p /tmp/spark
$ cd /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/conf
$ cp spark-defaults.conf.template spark-defaults.conf
在spark-defaults.conf追加如下配置:
# 使用yarn模式
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-node1:8082/tmp/spark
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
4)启动 spark-shell操作Hive(local)
支持多用户得启动metastore服务
$ nohup hive --service metastore &
$ ss -atnlp|grep 9083
在hive-site.xml加入如下配置:
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-node1:9083</value>
</property>
启动spark-sql
# yarn模式,--master yarn可以不带,因为上面在配置文件里已经配置了yarn模式了
$ spark-sql --master yarn
show databases;
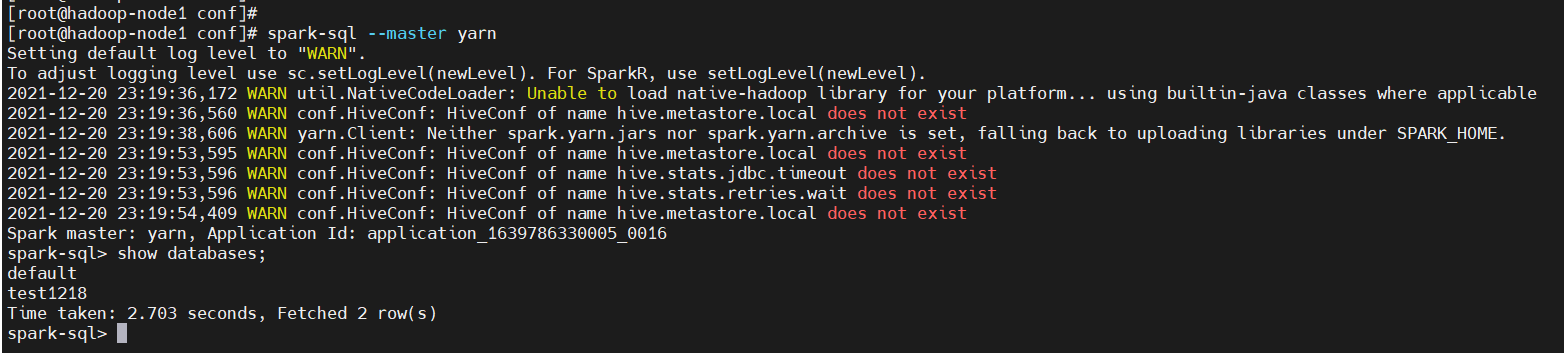
从上图就可发现,已经查到我之前创建的库了,说明已经集成ok了。
七、Spark beeline
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容
HiveServer2。因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好Spark Thrift Server后,可以直接使用hive的beeline访问Spark Thrift Server执行相关语句。Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore进行交互,获取到 hive 的元数据。
1)Spark Thrift Server架构于HiveServer2架构对比
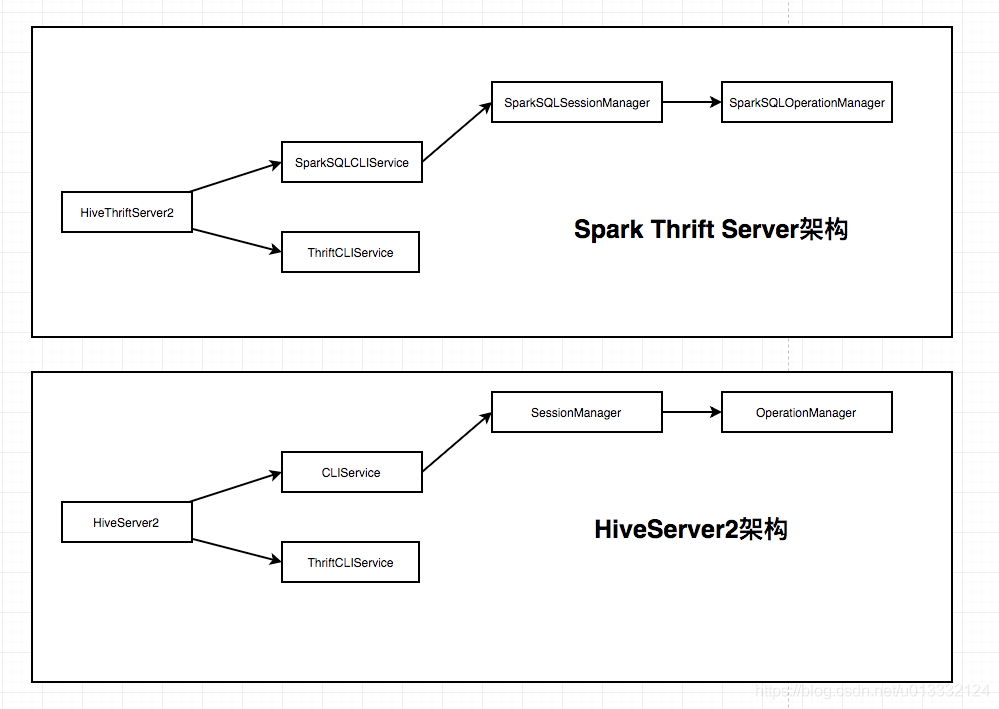
2)Spark Thrift Server和HiveServer2的区别
| Hive on Spark | Spark Thrift Server | |
|---|---|---|
| 任务提交模式 | 每个session都会创建一个RemoteDriver,也就是对于一个Application。之后将sql解析成执行的物理计划序列化后发到RemoteDriver执行 | 本身的Server服务就是一个Driver,直接接收sql执行。也就是所有的session都共享一个Application |
| 性能 | 性能一般 | 如果存储格式是orc或者parquet,性能会比hive高几倍,某些语句甚至会高几十倍。其他格式的话,性能相差不是很大,有时hive性能会更好 |
| 并发 | 如果任务执行不是异步的,就是在thrift的worker线程中执行,受worker线程数量的限制。异步的话则放到线程池执行,并发度受异步线程池大小限制。 | 处理任务的模式和Hive一样。 |
| sql兼容 | 主要支持ANSI SQL 2003,但并不完全遵守,只是大部分支持。并扩展了很多自己的语法 | Spark SQL也有自己的实现标准,因此和hive不会完全兼容。具体哪些语句会不兼容需要测试才能知道 |
| HA | 可以通过zk实现HA | 没有内置的HA实现,不过spark社区提了一个issue并带上了patch,可以拿来用:https://issues.apache.org/jira/browse/SPARK-11100 |
【总结】Spark Thrift Server说白了就是小小的改动了下HiveServer2,代码量也不多。虽然接口和HiveServer2完全一致,但是它以单个Application在集群运行的方式还是比较奇葩的。可能官方也是为了实现简单而没有再去做更多的优化。
3)配置启动Spark Thrift Server
1、配置hive-site.xml
<!-- hs2端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>11000</value>
</property>
2、启动spark thriftserver服务(不能起hs2,因为配置是一样的,会有冲突)
$ cd /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/sbin
$ ./start-thriftserver.sh
$ ss -tanlp|grep 11000

3、启动beeline操作
# 为了和hive的区别,这里使用绝对路径启动
$ cd /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/bin
# 操作跟hive操作一模一样,只是计算引擎不一样了,换成了spark了
$ ./beeline
!connect jdbc:hive2://hadoop-node1:11000
show databases;
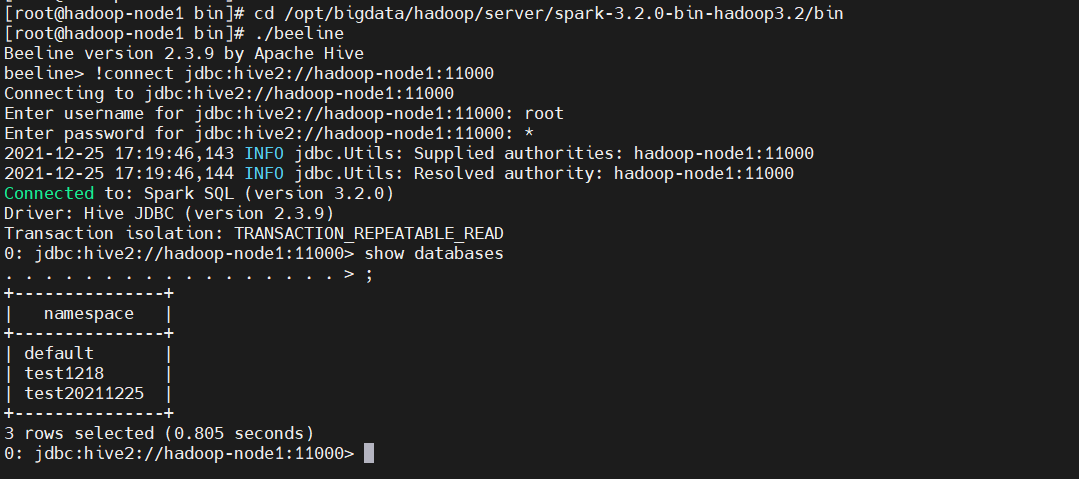
访问HDFS WEB UI:http://hadoop-node1:8088/cluster/apps

八、Spark Streaming
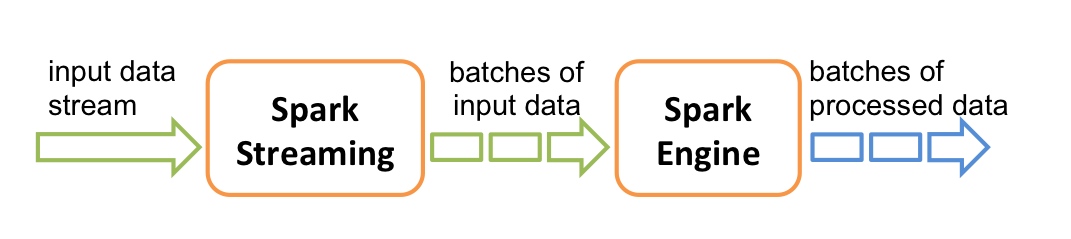
Spark Streaming与其他大数据框架Storm、Flink一样,Spark Streaming是基于Spark Core基础之上用于处理实时计算业务的框架。其实现就是把输入的流数据进行按时间切分,切分的数据块用离线批处理的方式进行并行计算处理。原理如下图:

支持多种数据源获取数据:

Spark处理的是批量的数据(离线数据),Spark Streaming实际上处理并不是像Strom一样来一条处理一条数据,而是将接收到的实时流数据,按照一定时间间隔,对数据进行拆分,交给Spark Engine引擎,最终得到一批批的结果。
由于考虑到本篇文章篇幅太长,所以这里只是稍微提了一下,如果有时间会继续补充Spark Streaming相关的知识点,请耐心等待……
官方文档:https://spark.apache.org/docs/3.2.0/streaming-programming-guide.html
