一、简介
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控;属于sysstat包;它是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。与top不同的是,top是交互式工具,用于监视性能,包含整个Linux系统的性能概要和进程信息。
如果没有vmstat命令,则需要安装
yum install -y sysstat
二、内存解读
Linux系统的内存分为物理内存和虚拟内存两种。物理内存是真实的,也就是物理内存条上的内存。而虚拟内存则是采用硬盘空间补充物理内存,将暂时不使用的内存页写到硬盘上以腾出更多的物理内存让有需要的进程使用。当这些已被腾出的内存页需要再次使用时才从硬盘(虚拟内存)中读回内存。这一切对于用户来说是透明的。通常对Linux系统来说,虚拟内存就是swap分区。
三、参数解读
3.1、 表达式:
SYNOPSIS vmstat [-a] [-n] [delay [ count]] vmstat [-f] [-s] [-m] vmstat [-S unit] vmstat [-d] vmstat [-D] vmstat [-p disk partition] vmstat [-V]
3.2、要以1秒为时间间隔,连续收集3次性能数据,命令如下:
(py3) [root@jumpserver-168-182-149 ~]# vmstat 1 3 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 434432 700156 36 1380360 0 0 3 13 42 12 5 3 92 0 0 1 0 434432 686628 36 1380456 0 0 0 0 2573 1434 18 6 77 0 0 1 0 434432 662676 36 1380512 0 0 0 0 2021 1395 15 5 80 0 0
|
类别 |
项目 |
含义 |
说明 |
|
Procs(进程) |
r |
等待执行的任务数 |
展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
|
B |
等待IO的进程数量 |
||
|
Memory(内存) |
swpd |
正在使用虚拟的内存大小,单位k |
|
|
free |
空闲内存大小 |
||
|
buff |
已用的buff大小,对块设备的读写进行缓冲 |
||
|
cache |
已用的cache大小,文件系统的cache |
||
|
inact |
非活跃内存大小,即被标明可回收的内存,区别于free和active |
具体含义见:概念补充(当使用-a选项时显示) |
|
|
active |
活跃的内存大小 |
具体含义见:概念补充(当使用-a选项时显示) |
|
|
Swap |
si |
每秒从交换区写入内存的大小(单位:kb/s) |
|
|
so |
每秒从内存写到交换区的大小 |
||
|
IO |
bi |
每秒读取的块数(读磁盘) |
块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
|
bo |
每秒写入的块数(写磁盘) |
块设备每秒发送的块数量,单位是block |
|
|
system |
in |
每秒中断数,包括时钟中断 |
这两个值越大,会看到由内核消耗的cpu时间sy会越多 秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 |
|
cs |
每秒上下文切换数 |
||
|
CPU(以百分比表示) |
us |
用户进程执行消耗cpu时间(user time) |
us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
|
sy |
系统进程消耗cpu时间(system time) |
sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足 |
|
|
Id |
空闲时间(包括IO等待时间) |
一般来说 us+sy+id=100 |
|
|
wa |
等待IO时间 |
wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
vmstat命令提供了许多命令行参数,使用man手册查看参数的详细文档。常用的参数有:
-m :显示内核的内存使用情况(slabs) -a :显示活动和非活动内存分页相关信息 -n :只显示一次栏位名称行,当在取样模式通下将输出信息存储到文件时非常有用。(例如,root#vmstat –n 2 10 以每2秒钟的频率执行10次取样),如果只接一个数字,则表示每多少秒无限执行
三、系统监控的实验
实例一、大量的系统调用
本脚本会进入一个死循环,不断的执行cd命令,从而模拟大量系统调用的环境
测试脚本如下:
#!/bin/bash while (true) do cd ; done
chmod +x loop.sh
./loop.sh
运行:vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 0 435712 416576 36 1736788 0 0 0 0 5890 7219 4 21 75 0 0 2 0 435712 361036 36 1736792 0 0 0 0 6974 7930 24 24 52 0 0 3 0 435712 330312 36 1736968 0 0 0 0 7304 7761 18 32 51 0 0 3 0 435712 321648 36 1737080 0 0 0 0 6767 7008 21 29 50 0 0 1 0 435712 290116 36 1737144 0 0 0 0 6346 6591 25 24 50 0 0 5 0 435712 289628 36 1737168 0 0 0 99 8346 13175 8 25 68 0 0 1 0 435712 413956 36 1737188 0 0 0 144 7947 12721 18 25 58 0 0 1 0 435712 413792 36 1737188 0 0 0 0 5701 7234 4 21 75 0 0 2 0 435712 413368 36 1737188 0 0 0 8 5944 7442 4 21 75 0 0 2 0 435712 415280 36 1737188 0 0 0 0 5709 7221 4 21 75 0 0 1 0 435712 414148 36 1737188 0 0 0 0 5713 6706 4 21 75 0 0 1 0 435712 413932 36 1737188 0 0 0 0 5298 6310 5 20 76 0 0 2 0 435712 415592 36 1737188 0 0 0 0 5678 7199 4 21 75 0 0 2 0 435712 414368 36 1737188 0 0 0 0 5653 6700 4 20 75 0 0 3 0 435712 413432 36 1737188 0 0 0 210 5633 7050 4 21 75 0 0 7 0 435712 411728 36 1737188 0 0 0 230 6648 9505 5 22 73 0 0 2 0 435712 373168 36 1737200 0 0 0 190 9797 16602 24 31 45 0 0
随着程序不断调用cd命令,运行队列有等待的进程r(看参数r),每秒的中断数in(看参数in),下文切换的次数cs骤然提高(看参数cs),系统占用的cpu时间sy(看参数sy)也不断提高,cpu空闲时间id(看参数id)一直为0。当程序终止的时候,r,in,cs,sy数据都下来了,id上去了,表示系统已经空闲下来了。
实例二、大量的io操作
我们用dd命令,从/dev/zero读数据,写入到/tmp/data文件中,如下:
dd if=/dev/zero of=/tmp/data bs=1M count=1000 参数解释: if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file > of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file > bs=bytes:同时设置读入/输出的块大小为bytes个字节。 count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
/dev/zero:“零”设备,可以无限的提供空字符(0x00,ASCII代码NUL)。常用来生成一个特定大小的文件
dd if=/dev/zero of=./output.txt bs=1024 count=1 #产生一个1k大小的文件output.txt
运行:vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 21 0 439296 114440 36 1975824 0 0 0 0 410 769 3 97 0 0 0 24 0 439552 129656 36 1959912 0 348 0 348 287 536 4 96 0 0 0 24 0 439808 129572 36 1959316 0 36 0 36 206 423 0 100 0 0 0 18 0 439808 157688 36 1930456 0 148 0 148 308 511 4 96 0 0 0 23 0 440320 160804 36 1927740 0 456 0 456 277 540 5 95 0 0 0 17 1 440320 181112 36 1912696 0 48 208 48 373 707 10 90 0 0 0 20 0 440576 185452 36 1909900 0 168 136 168 246 373 11 89 0 0 0 30 0 440576 176440 36 1918448 0 0 3984 19 471 846 23 74 3 0 0 34 0 440576 168792 36 1921808 0 0 1072 24 448 851 17 83 0 0 0 17 0 440576 166992 36 1923036 0 0 332 0 304 704 10 90 0 0 0 12 0 440576 167552 36 1926380 0 0 1532 0 573 1381 38 62 0 0 0 13 0 440576 165368 36 1927568 0 0 0 127 267 433 5 95 0 0 0 6 0 440576 163492 36 1928592 0 0 0 0 319 527 8 92 0 0 0 7 0 440576 160376 36 1929892 0 0 0 0 279 613 4 96 0 0 0 10 0 440576 158276 36 1931884 0 0 0 0 325 568 4 96 0 0 0 12 0 440576 156188 36 1934068 0 0 0 0 334 584 11 89 0 0 0 12 0 440576 154172 36 1935252 0 0 0 0 282 419 4 96 0 0 0 10 0 440576 152016 36 1935856 0 0 0 0 245 452 0 100 0 0 0 9 0 440576 149820 36 1936904 0 0 0 4 291 535 4 96 0 0 0 19 0 440576 147456 36 1937672 0 0 0 0 282 445 4 96 0 0 0 18 1 440576 145656 36 1938468 0 0 0 18 273 614 5 95 0 0 0 14 0 440576 143684 36 1940092 0 0 0 6 296 514 4 96 0 0 0 10 0 440576 141644 36 1940580 0 0 0 0 244 445 0 100 0 0 0
1、bo写数据到磁盘的速率,bi是从磁盘读的速度
2、dd不断的向磁盘写入数据,所以bo的值会骤然提高
这回从/tmp/data文件读,写到/dev/null文件中,如下:
dd if=/tmp/test1 of=/dev/null bs=1M
1、dd不断的从/tmp/data磁盘文件中读取数据,所以bi的值会骤然变高,最后我们看到b(在等待io的进程)也由0变成了1甚至到2
2、dd读的时候,in中断数和cs上下文切换很高,还有就是等待IO所消耗的cpu时间wa相当高
四、vmstat用法:
1、查看系统已经fork了多少次
(py3) [root@jumpserver-168-182-149 ~]# vmstat -f 14642852 forks
注意:这个数据是从/proc/stat中的processes字段里取得的
2、查看内存的active和inactive
(py3) [root@jumpserver-168-182-149 ~]# vmstat -a
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 376576 229028 897160 2018204 0 0 4 14 8 27 5 3 92 0 0
3、查看内存使用的详细信息
(py3) [root@jumpserver-168-182-149 ~]# vmstat -s 3861364 K total memory 1758596 K used memory 2017476 K active memory 897136 K inactive memory 229908 K free memory 36 K buffer memory 1872824 K swap cache 4063228 K total swap 376576 K used swap 3686652 K free swap 5201414 non-nice user cpu ticks 49 nice user cpu ticks 2814309 system cpu ticks 89605394 idle cpu ticks 36633 IO-wait cpu ticks 0 IRQ cpu ticks 110102 softirq cpu ticks 0 stolen cpu ticks 3924612 pages paged in 14092886 pages paged out 25685 pages swapped in 117208 pages swapped out 480587807 interrupts 670429635 CPU context switches 1624539986 boot time 14652200 forks
4、查看磁盘的读/写
(py3) [root@jumpserver-168-182-149 ~]# vmstat -d disk- ------------reads------------ ------------writes----------- -----IO------ total merged sectors ms total merged sectors ms cur sec sr0 18 0 2056 580 0 0 0 0 0 0 sda 119355 7888 7838620 5931106 1215186 204210 27261464 4283174 0 2143 dm-0 100059 0 7566702 5788365 1302162 0 26315487 4253256 0 1819 dm-1 25773 0 209888 193185 117208 0 937664 34797615 0 522 dm-2 148 0 2532 170 4 0 4096 96 0 0 sdb 194 0 8548 304 951 33592 930656 716 0 0
注意:这些信息主要来自于/proc/diskstats.
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
5、查看/dev/sda磁盘的读/写,注意磁盘需要是已分区的。
(py3) [root@jumpserver-168-182-149 ~]# vmstat -p /dev/sdb2 sdb2 reads read sectors writes requested writes 100 6224 0 0
五、top命令详解
5.1、参数详解
top命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
top的使用方式 top [-d number] | top [-bnp]
参数解释:
-d:number代表秒数,表示top命令显示的页面更新一次的间隔。默认是5秒。
-b:以批次的方式执行top。
-n:与-b配合使用,表示需要进行几次top命令的输出结果。
-p:指定特定的pid进程号进行观察。 在top命令显示的页面还可以输入以下按键执行相应的功能(注意大小写区分的): ?:显示在top当中可以输入的命令
P:以CPU的使用资源排序显示
M:以内存的使用资源排序显示
N:以pid排序显示
T:由进程使用的时间累计排序显示
k:给某一个pid一个信号。可以用来杀死进程
r:给某个pid重新定制一个nice值(即优先级)
q:退出top(用ctrl+c也可以退出top)。
5.2、top前5行统计信息
第1行:top - 05:43:27 up 4:52, 2 users, load average: 0.58, 0.41, 0.30
第1行是任务队列信息,其参数如下:
| 内容 | 含义 |
|---|---|
| 05:43:27 | 表示当前时间 |
| up 4:52 | 系统运行时间 格式为时:分 |
| 2 users | 当前登录用户数 |
| load average: 0.58, 0.41, 0.30 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
load average: 如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第2行:Tasks: 159 total, 1 running, 158 sleeping, 0 stopped, 0 zombie 第3行:%Cpu(s): 37.0 us, 3.7 sy, 0.0 ni, 59.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
第2、3行为进程和CPU的信息
注意:%Cpu(s)是系统所有用户进程占用整个CPU的平均值,由于每个核心占用的百分比不同,所以按平均值来算比较有参考意义。
当有多个CPU时,这些内容可能会超过两行,其参数如下:
| 内容 | 含义 |
|---|---|
| 159 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 158 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| 37.0 us | 用户空间占用CPU百分比 |
| 3.7 sy | 内核空间占用CPU百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 59.3 id | 空闲CPU百分比 |
| 0.0 wa | 等待输入输出的CPU时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| 0.0 si | 软中断(Software Interrupts)占用CPU的百分比 |
| 0.0 st |
第4行:KiB Mem: 1530752 total, 1481968 used, 48784 free, 70988 buffers 第5行:KiB Swap: 3905532 total, 267544 used, 3637988 free. 617312 cached Mem
第4、5行为内存信息
其参数如下:
| 内容 | 含义 |
|---|---|
| KiB Mem: 1530752 total | 物理内存总量 |
| 1481968 used | 使用的物理内存总量 |
| 48784 free | 空闲内存总量 |
| 70988 buffers(buff/cache) | 用作内核缓存的内存量 |
| KiB Swap: 3905532 total | 交换区总量 |
| 267544 used | 使用的交换区总量 |
| 3637988 free | 空闲交换区总量 |
| 617312 cached Mem | 缓冲的交换区总量。 |
| 3156100 avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上述最后提到的缓冲的交换区总量,这里解释一下,所谓缓冲的交换区总量,即内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
计算可用内存数有一个近似的公式:
第四行的free + 第四行的buffers + 第五行的cached
5.3、进程信息
| 列名 | 含义 |
|---|---|
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEM | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
5.4、其它实用快捷键操作
默认进入top时,各进程是按照CPU的占用量来排序的。
1、在top基本视图中,按键盘数字“1”可以监控每个逻辑CPU的状况:
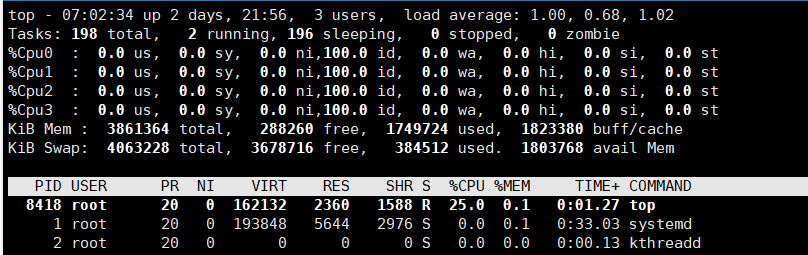
2、改变进程显示字段
在top基本视图中,敲击”f”进入另一个视图,在这里可以编辑基本视图中的显示字段:
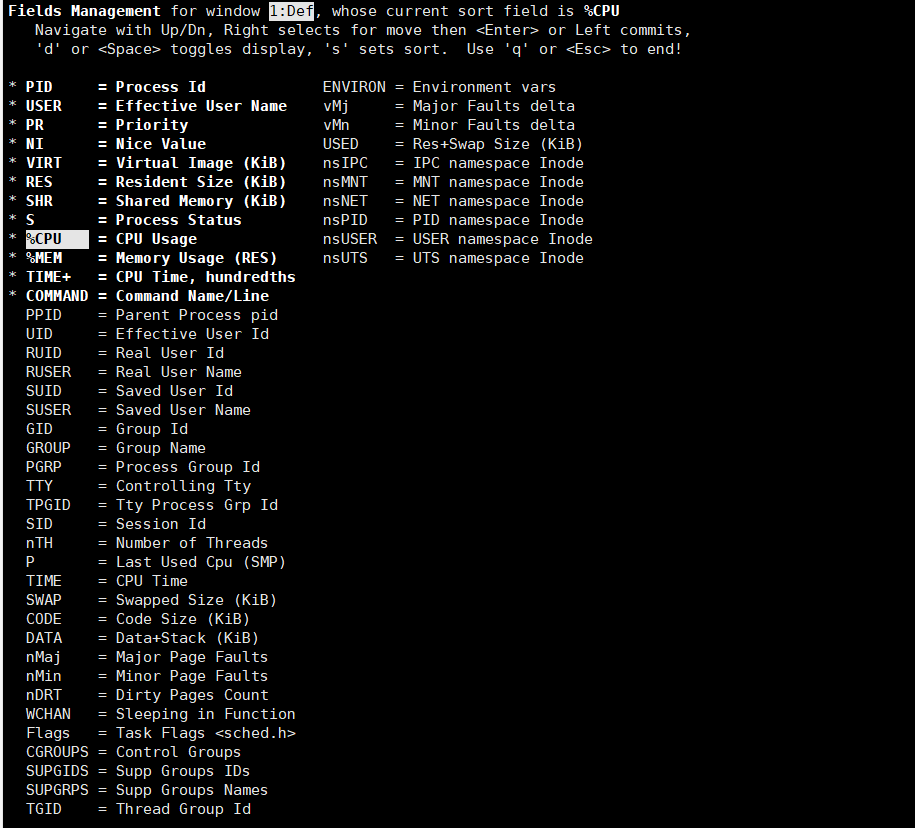
用上下键选择选项,按下空格键可以决定是否在基本视图中显示这个选项。
top命令是一个非常强大的功能,但是它监控的最小单位是进程,如果想监控更小单位时,就需要用到ps或者netstate命令来满足我们的要求。
~~~以上就是vmstat和top工具的讲解~~~